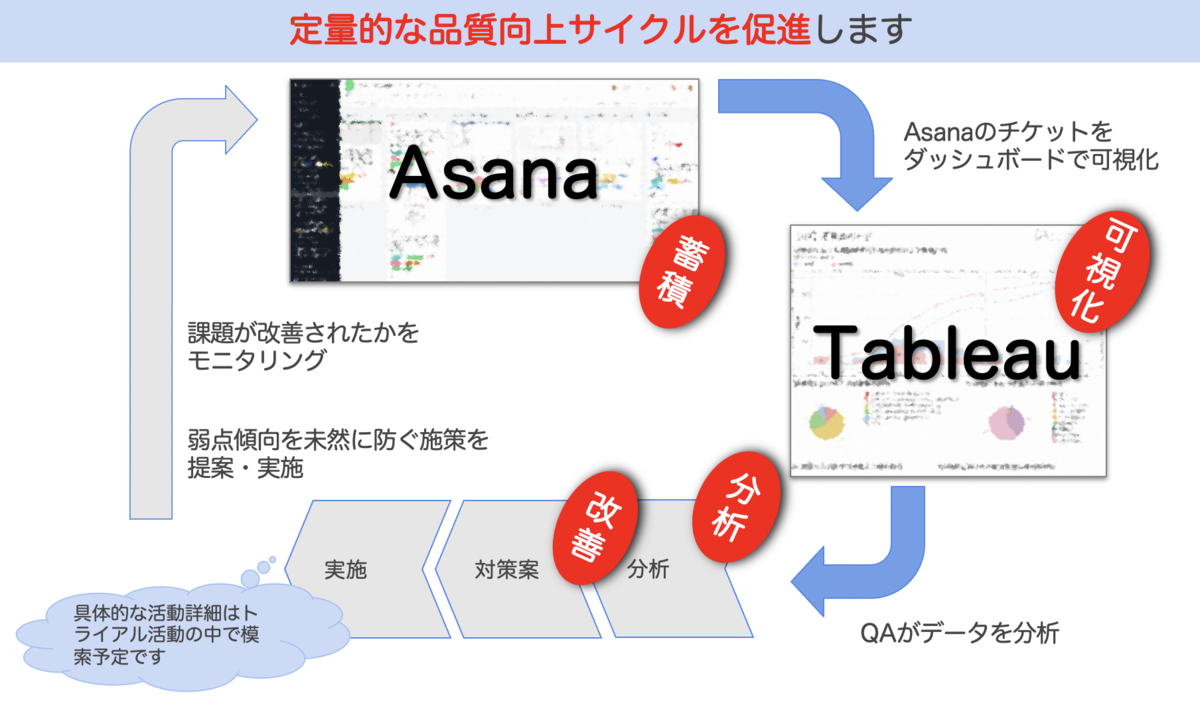
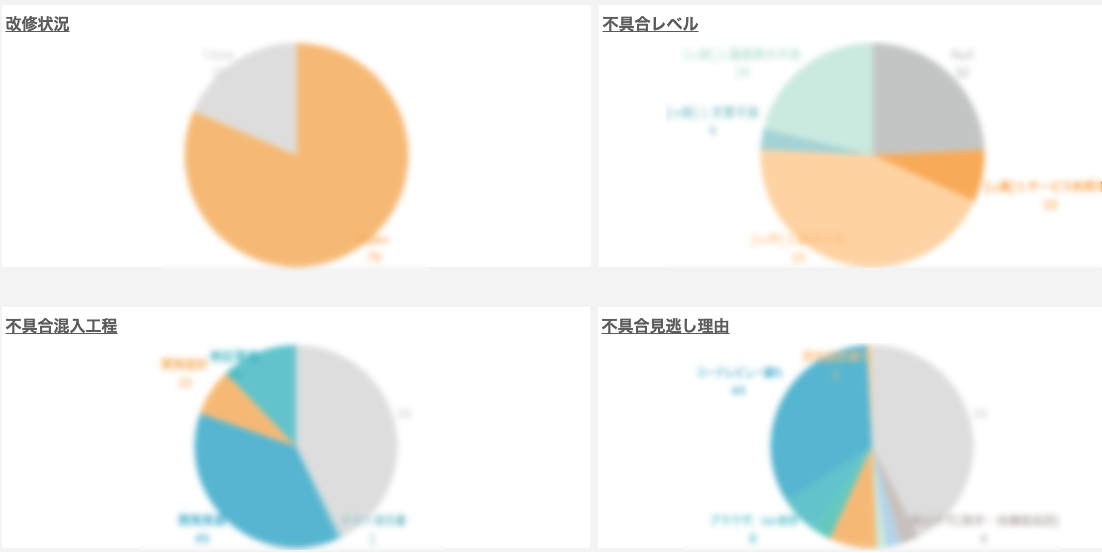
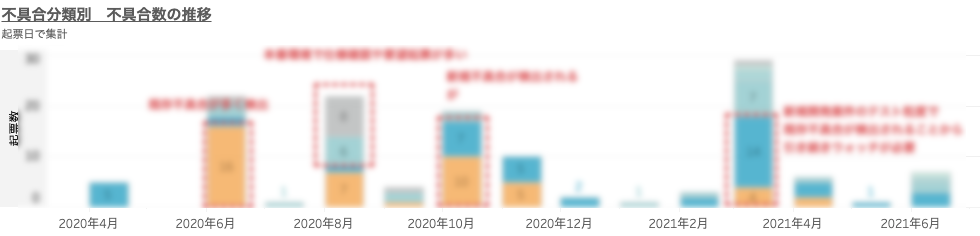
はじめに
Classi 株式会社 開発本部です。
先日開催された RubyKaigi Takeout 2021、弊社もスポンサーとして後援したりメンバ数名が参加してセッションを見たりして盛り上がりました。
毎日の開発で日常的に使いつつもどんな人がどのように作っているかをあまり意識していない Ruby そのものについて色々なことが知れる刺激的な Kaigi だったと思います。
以下、参加したメンバの印象に残ったセッションの感想になります。
Ractorをワーカーとして使うアプリケーションサーバの課題
1年前に新卒入社したWebtestチームの@minhquangです。
Classiのおかげで、初めてのRubyKaigiに楽しく参加できました。
私にとってほぼ未知の世界なので、様々なセッションを見てみました。
今回は一番興味があった tagomoris さんのRactor's speed is not light-speedに関するお話を紹介します。
Ractor は 笹田さんから2016年に紹介されて、CPUのコアを並列で実行できる仕組みとしてRuby 3.0に導入されました。
(※ Ractorの仕様を詳しく知りたいなら、Ruby repository の資料をご覧ください)
Ractor間でオブジェクトはメッセージとして共有されるのですが、以下のオブジェクト以外は共有禁止されています。
- Module, Classes
- Application Code (Proc)
- Definitions (constants), Settings/Configurations (frozen objects)
Ractor間でオブジェクトを共有するには、オブジェクトにshareableをマークする必要があります。
x = 1
p1 = ->() { x + 2 }
p p1.call
x = 5
p p1.call
x = 1
p2 = ->() { x + 2 }
p Ractor.shareable?(p2)
Ractor.make_shareable(p2)
p Ractor.shareable?(p2)
p p2.call
x = 5
p p2.call
このようにマークすると、Proc自体はisolatedになって共有できるようになります。
けど、Procの中で共有できないオブジェクトがある場合はもうちょっと深くisolated化にする必要があります。
s1 = "Yaaaaaaay"
p3 = ->(){ s1.upcase }
p Ractor.shareable?(p3)
=> false
Ractor.make_shareable(p3)
s2 = "Boooooooo".freeze
p4 = ->(){ s2.upcase }
Ractor.make_shareable(p4)
なお、この辺の面倒なのを避けるために Ruby 3.0 には凄く便利なマジックコメントが追加されているみたいです。
TABLE = {a: 'ko1', b: 'ko2', c: 'ko3'}
(セッションの中でもこういうマジックコメントほしい!と tagomoris さんが言ってましたが既にあったようです。ブログでもフォローされていました)
Ractorを使ってどのようにWebアプリケーションのパフォーマンスを向上させるか、4コアなら4倍になるのか、 tagomoris さんはRactorをワーカーとして使うアプリケーションサーバのright_speed を作りました。
私も tagomoris さんの作ったデモで実験してみました。
Rackサーバで起動してみると以下のエラーが発生しました (Bug #18024)。また、 RailsとSinatraを起動してみたところエラーもたくさん発生しました。
> right_speed -c config.ru -p 8080 --workers 4
> wrk git:(master) ./wrk -t12 -c100 -d30s http://127.0.0.1:8080/
Running 30s test @ http://127.0.0.1:8080/
12 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 8.67ms 1.69ms 13.77ms 71.14%
Req/Sec 328.83 105.85 484.00 66.67%
797 requests in 30.04s, 51.37KB read
Socket errors: connect 0, read 796, write 0, timeout 0
Requests/sec: 26.53
Transfer/sec: 1.71KB
7fff90200000-7fff90400000 rw- /usr/lib/dyld
7fff90400000-7fffc0000000 r-- /usr/lib/dyld
7fffc0000000-7fffffe00000 r-- /usr/lib/dyld
7fffffe00000-7fffffe01000 r-- /usr/lib/dyld
7ffffff3f000-7ffffff40000 r-x /usr/lib/dyld
[IMPORTANT]
Don't forget to include the Crash Report log file under
DiagnosticReports directory in bug reports.
[1] 27965 abort right_speed -c config.ru -p 8080 --workers 4
[2021-10-05 22:17:05 +0900] ERROR Unexpected error: can not access instance variables of classes/modules from non-main Ractors
確かに上記の説明と同じように Rack/Rails/Sinatraの中に unshareableが多すぎて問題が発生しました。 unshareableオブジェクトはRactor間で共有できないため、オブジェクトをshareableにマークしたり、オブジェクトの中にもデフォルトインスタンスや frozenなどもdeepに指定したりしなければなりません。
Ractorはまだまだ新しいものですし、既存のプロダクトに導入するには対応しなければならないことが多くありそうに思いました。しかし、Ractorで動くアプリケーションの未来は面白いと感じますし、対応が大変だからこそ Contributionチャンスになります。自分も出来る限り、この未来に力を入れたいと思います。
Ruby開発の実情を聞いて背筋がピンとした話
こんにちは。プロダクト開発部 webtestチームに所属している中村(真)@s_nakamuraです。今回RubyKaigi Takeout 2021に参加しました。オンライン開催ということで雰囲気はどうなるのか楽しみでしたが、実際想像していた以上にオンラインでも以前参加したRubyKaigiと同じような熱気を感じることが出来ました。
さて私は今回一番印象に残った「How to develop the Standard Libraries of Ruby?」について紹介したいと思います。
このセッションではRubyの開発がどのような観点を持って進めているのか話されていました。
最初にRuby3.0についてです。RubyはStandard LibrariesとDefault Gemsで構成されていて、必ず含まれていなくても良いものはBundled Gemsとされています。
このような構成にすることでセキュリティ対応の時にアップデートが必要な箇所だけアップデートすれば良いというのは、理にかなっていると思いました。各機能が適切に分割されて作られていれば、問題があった箇所だけ入れ替えることで確認すべき範囲を絞り込むことが出来ます。使う側としては確認する作業に変わりはないですが。
次に3.1についての話もありました。それによるとRuby3.1からdefault gemに含まれていたライブラリを幾つかRubyのリポジトリから外した物がありました。その一方で外せなかったものもあったというのが興味深かったです。例えばEnglishというgemは外したかったがrubocopの方で推奨されるなど影響度が広いためdefault gemsから外せなかったとの事でした。何をdefault gemsとして入れるか判断するのに現在の状況や他のgemの挙動/世の中への影響度も考慮に入れて判断しているというのが、言語開発という世の中に大きな影響を与えているプロジェクトの苦労するポイントなのかと思いました。
そして一番これは大変だと思ったのがRuby開発者それぞれが開発したコードをマージしていく作業についてです。ある程度までは自動チェック出来るそうですが、自動でチェック出来ないところは「手動による心温まる手作業」との事です。
普段業務でたまにconflictが発生することがありますが、それを解消するのも割と神経を使う作業ですし骨が折れるときもあります。それが開発言語の開発で発生した場合に手作業でマージする作業が如何に神経を使う繊細な作業か・・・・。開発人数が多くなったり、規模が大きくなるとそういう部分の苦労もある、今Rubyが使えているのは日々言語開発者の方々の繊細で緻密な作業の結果なのだと再認識し背筋がピンとのびました。
その他
あとセッションの内容とは直接関係ないのですが、gitではリポジトリが違ってもcherry-pickが出来るというのが勉強不足で知りませんでした。どんな感じで出来るのか、試しに自分のプライベートで使っているリポジトリで試してみました。試してみたことはまずリポジトリAでhoge.txtというファイルを追加しcommit & pushします。次に同じ修正をリポジトリBに入れるというのを試します。
$ git add hoge.txt
$ git commit -m'hoge.txtを新規に作成'
$ git push origin HEAD
$ git log
commit f863xxxxxxxxxxxxxxxxxxxxxxx (HEAD -> master, origin/master, origin/HEAD)
Author: nakaearth <shinichiro.nakamura@classi.jp>
Date: Wed Jul 10 15:29:29 2019 +0900
次にリポジトリBで先ほどリポジトリAでした修正をcherry pickする。
最初にリポジトリBに移動する
$ cd repo_b
git remote add でリポジトリAを追加する
$ git remote add add_hoge https:://github.com/nakaearth/repo_a
add_hogeをfetchしcherry-pick
$ git fetch add_hoge
$ git cherry-pick add_hoge
cherry-pickした後に実際リポジトリAで行なった作業がリポジトリBにも反映されていることが確認できました。今回は簡単に1ファイルだけでしたが、これが複数のファイルで更にコンフリクトが発生した場合、これもまた繊細な作業になると思いました。
以上が「How to develop the Standard Libraries of Ruby?」についての私のレポートになります
RubyにおけるDSLの短所を克服するための静的解析支援
新卒入社3年目の@willsmileです。アプリチームでサーバサイドの開発・運用を担当しています。
会社からもらったスポンサーチケットで、今年のRubyKaigiにも参加できて、3年前初めて参加する時の印象と変わらず、セッション内容の多様性に富んでいると感じています。それに参加することを通じて気づいたことを言語化し、他の人に紹介する経験は、自身の技術者のロールモデルの形成と更新にとても役に立つと自覚しました。このような経験学習において自身のモチベーションを高めるために、今回は技術ブログの執筆に担当させてもらいました。
紹介したい発表は、@paracycleさんのDemystifying DSLs for better analysis and understandingです。以下でこの発表の内容を自分の言葉で説明してみます。
- DSL 1 の特徴
- 長所:複数の場所で繰り返されるボイラープレートコードを無しにできること(No boilerplate)と、シンプルな表現でAPIを定義できること(Natural API)
- 短所:Static Analysisが難しくなり、Code Readabilityが低下する恐れがある
- 問題定義
- Rubyで構築されたDSLを、RBI・RBSのような静的型解析にも対応できれば、上記の短所を乗り越えられるのではないか
- 解決方法
- DSLにより動的定義されたメソッドに対応して、RBIを自動生成するライブラリーtapiocaを開発した 2
手元で簡単な Rails app を作成し(要件:UserがArticleを作成・編集・一覧・削除でき、1件のArticleに複数個のTagを付けることが可能)、 tapiocaのREADME.mdを見ながら、手元で各モデルのRBIを作成してみました。モデルの定義と生成されたRBIのファイルは以下の具体例で示しています。 3
class Article < ApplicationRecord
belongs_to :user
has_many :article_tags
has_many :tags, through: :article_tags, dependent: :destroy
enum status: {archived: 0, wip: 1, published: 2}, _prefix: true
end
> bundle exec tapioca init
> bundle exec tapioca dsl Article
class Article
include GeneratedAssociationMethods
include GeneratedAttributeMethods
include EnumMethodsModule
extend GeneratedRelationMethods
sig { returns(T::Hash[T.any(String, Symbol), Integer]) }
def self.statuses; end
module EnumMethodsModule
sig { void }
def status_archived!; end
sig { returns(T::Boolean) }
def status_archived?; end
end
module GeneratedAssociationMethods
sig { returns(::ActiveRecord::Associations::CollectionProxy[::Tag]) }
def tags; end
sig { params(value: T::Enumerable[::Tag]).void }
def tags=(value); end
sig { returns(T.nilable(::User)) }
def user; end
sig { params(value: T.nilable(::User)).void }
def user=(value); end
end
module GeneratedAttributeMethods
sig { returns(T.untyped) }
def status; end
sig { params(value: T.untyped).returns(T.untyped) }
def status=(value); end
sig { returns(T::Boolean) }
def status?; end
sig { returns(T::Boolean) }
def status_changed?; end
sig { returns(T.nilable(T.untyped)) }
def status_was; end
end
module GeneratedRelationMethods
sig { params(args: T.untyped, blk: T.untyped).returns(T.untyped) }
def not_status_published(*args, &blk); end
sig { params(args: T.untyped, blk: T.untyped).returns(T.untyped) }
def status_published(*args, &blk); end
end
end
生成されたRBIファイルを眺めてみて、以下のことを気づきました。
- Railsの仕組みにより、DSLとして自動生成されたメソッドには以下のような分類がある。
- GeneratedAssociationMethods:アソシエーション(ActiveRecord::Associations)により定義されたされたインスタンスメソッド
- GeneratedRelationMethods:クエリインターフェイス(ActiveRecord::Relation)により定義されたクラスメソッド
- EnumMethods:Enum(ActiveRecord::Enum)の定義により定義されたインスタンスメソッド
- GeneratedAttributeMethods:属性(ActiveModel::Attributes)により定義されたされたインスタンスメソッド
- GeneratedAttributeMethodsで定義された
status_changed?やstatus_wasなどActiveModel::Dirtyにより定義されたメソッドは初めて知った
specific_instance_of_article.tagsの戻り値のタイプがActiveRecord::Associations::CollectionProxyであることに“なるほど”と思った
今回の試みを全体的に振り返ってみると、業務の中でtapiocaを実際に使う機会が少ないかもしれないが、Railsで定義された便利なメソッドを網羅的に知るきっかけになったと思います。冒頭でも述べたように、RubyKaigiではいろいろな“面白い”発表があります。その面白さは、人によって捉え方が違います。人(発表者)がどのような問題定義・解決方法を考えているのかを考えてみること、自分が少し試して気づいたことを話してみることは良い学び方かなと考えて、お勧めします。
参考文献
Fowler, M. (2010). Domain-Specific Languages. Pearson Education, p28.
Ruby3.1 から irb が進化するみたいなのでさわってみた
今年Classiにエンジニアとして新卒入社しました北村です。
今回私もRubyKaigi Takeout 2021 に参加し、初めて RubyKaigi を体験しました。運営の方、発表者の方、視聴されている方、全ての方から Ruby への熱い思いが溢れ出るこのイベントでまさに「Ruby 漬け」な三日間を過ごすことができたのは、とても貴重な経験になりました。
そんな RubyKaigi Takeout 2021への参加レポートとして、私からは @aycabta さんによるセッション「Graphical Terminal User Interface of Ruby 3.1」で発表された irb の新機能について、その内容と実際に使ってみた時のログを書きたいと思います。
セッション要点
Ruby3.1 から irb において以下の二点が新機能として追加されると発表されました。
- 自動補完を実現する dialog window 機能
- dialog window 内での RDoc 参照機能
dialog window 機能についてはもともと @aycabta さんが reline という gem の中でこれまで実装されてきた機能で、それが Ruby3.1 の irb で採用されるということでした。
RDoc の dialog window 内での参照機能については、元々 RDoc の参照機能自体がすでにリリースされた irb で実現されていた機能ではあったものの、その使用体験に問題意識を感じた@aycabta さんが dialog window 内で RDoc を参照できるように実装されたということでした。
やってみた
今回発表された新機能は、 Ruby3.1 が出るのを待たずしても prerelease 版の irb をインストールすればいますぐ使えるということだったので試しに触ってみました。
準備
(今回は Ruby 3.0.2 で検証しました。)
gem install irb --pre を実行
- reline と irb の prerelease 版がインストールされました
irb -v でバージョンを確認
- 2021/10/11 執筆時現在の最新バージョンは
irb 1.3.8.pre.11 (2021-10-09) となっている
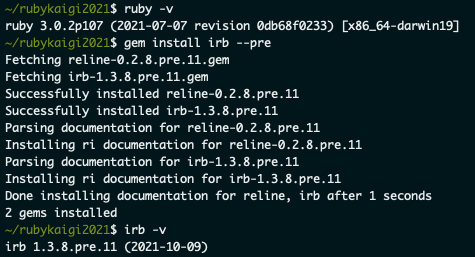
確認
まずは dialog window の表示してみる
irb を起動してみてどういう感じに dialog window が表示されるのかを見てみました。
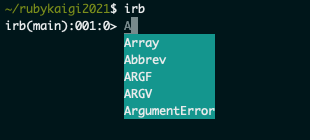
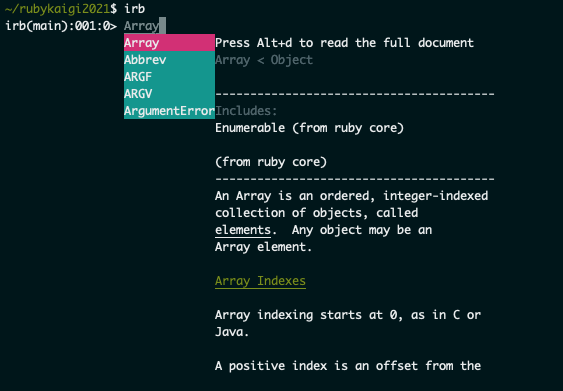
セッション内の demo では String クラスが例として使用されていたので、ここでは Array クラスを見てみようと思います。
ちゃんと dialog window が出て自動補完が効いていること、そして RDoc も dialog window 内に出ていることが確認できました。(Alt+d を押せば対象のドキュメントを全て表示することもできます)
処理中に挟んだ binding.irb の場合どうなるの?
ここまでやってみて、ふと「binding.irb などを使って処理の途中で irb を実行した場合についても、処理に関わるクラスやそのメソッド、変数などについて自動補完機能を利用できるのでは?」ということを感じたので、それについても試してみました。
class Book
def initialize(title)
@title = title
end
def title
@title
end
end
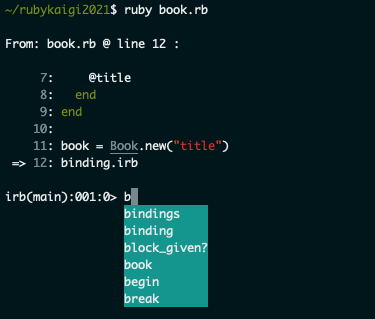
book = Book.new("title")
binding.irb
- コードを実行し止まったところでメソッドや変数の自動補完が出るか確認
bと打った時点で book が候補の中に表示される
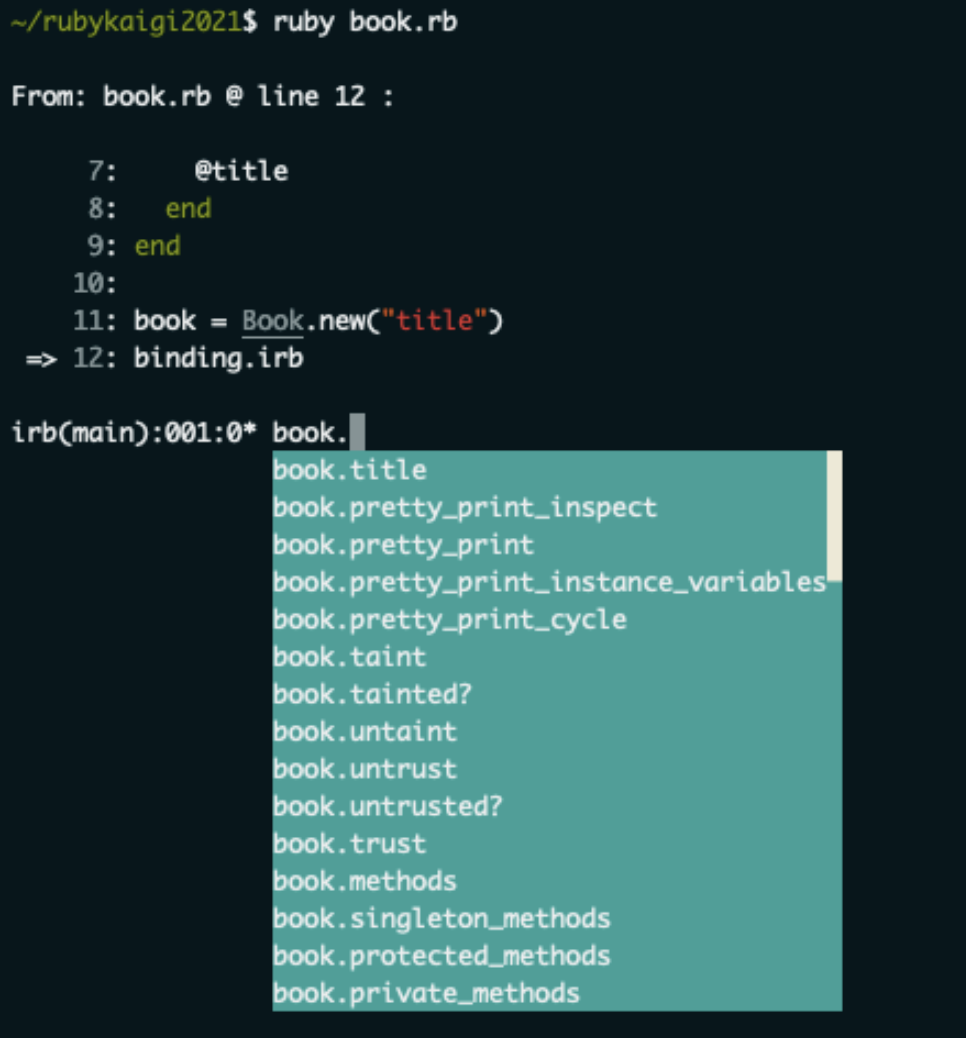
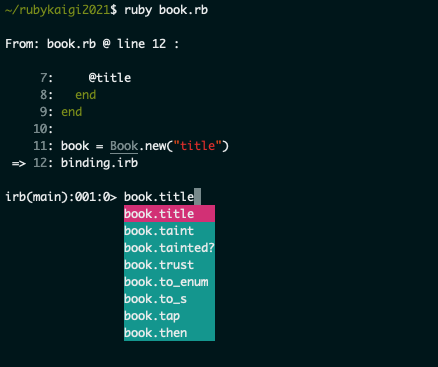
- tabキー押下で
book まで打ち込める。そこから、. を打つと title と表示される。再び tabキー押下で title まで打ち込める
自動補完機能はこのような使用用途でもきちんと使うことができそうです。
これなら irb の使用中にクラス名やメソッド名がわからずにいちいちコードを見にいって確認する、などの手間が省けそうで開発者にとっては嬉しい限りですね。
そしてこの検証をした後に気づいたのですが、実はこの内容、 Rails を背景としたお話ではありましたがセッション中に @aycabta さんがきちんと言及されていました。
Now you can use the rails console without worrying about adding many classes and methods to your business code.
(aycabta/RubyKaigi2021_daihon.md より)
rails console は内部で irb を使用しているということで、rails での開発体験についてもかなり向上が見込めそうです。
実際Classiでも「たくさんのクラスやメソッドが定義された rails コード」が多数存在します。もし rails console 上でクラス名やメソッド名が自動補完されるようになれば、 debug の際などに非常に嬉しいはずです。今後の日常の開発でもどんどん使っていこうと思いました。(なお、使用用途によっては debug gem を使用していくのが良い場合もありそうです)
以上、「Graphical Terminal User Interface of Ruby 3.1」セッションに関するレポートでした。
Rails app に RBS 導入試してみた!
開発本部所属エンジニアの匿名希望です。
今回見たセッションでは @pocke さんの The newsletter of RBS updates がよかったです。
※セッションの内容については公開されてる動画を見るのが早いと思うので割愛します
Ruby の型関連、気になってはいたのでたまにブログ記事とか見てへ〜みたいになりつつも導入までは至ってなかったんですが、このセッションで rbs collection っていうのを使うと始めやすいっぽい!と知れたのでせっかくだしちょっと触ってみよ〜ってなりました。
早速業務コードで……と思ったのですが、まずは簡単にお試し。
以下で試したサンプルはこちら:
rails scaffold で簡単なアプリ作って→ライブラリ等の設定をして→以下の型定義を作って、
def id_string: () -> String
型定義に合わないように実装ミスをして、
def id_string
id
end
型検査をしてみると、
> bundle exec steep check
app/models/task.rb:2:6: [error] Cannot allow method body have type `::Integer` because declared as type `::String`
│ ::Integer <: ::String
│ ::Numeric <: ::String
│ ::Object <: ::String
│ ::BasicObject <: ::String
│
│ Diagnostic ID: Ruby::MethodBodyTypeMismatch
│
└ def id_string
~~~~~~~~~
ちゃんと怒られた!うれしい!
やってみた感想は、rbs collection 最高〜!こんな導入簡単でいいの?です。
今回試す前に rbs で検索して出てきた他の方が書いた過去のブログとかも見て予習していたのですが、git submodule したり長いコマンドとか打ち込んでてめっちょ大変そう〜って思ってたので、シュッと終わって正直拍子抜けでした。
ってわけで業務コードにも導入!……と思ったのですが、年代物のコードだとあれこれ出てしまってすんなりはいかなそうでした🙃
とまれ、簡単なアプリで試して勘所を軽く掴んだ気がするので引き続きやっていこうと思います〜。
終わりに
個人的にオンラインの Kaigi に参加したのは初めてだったのですが、セッションごとのチャットで講演者に質問して盛り上がったり、社内の Slack で実況中継したりオンラインならではの楽しみ方ができてとてもよかったです。
素晴らしい Kaigi を開催してくれた運営チームの皆さんに感謝です!