この記事は Classi developers Advent Calendar 2021 の13日目の記事です。
こんにちは。開発本部プロダクト開発部学習チームでエンジニアをしています、藤田です。 本記事では AWS の IAM の Policy の定義から、アクセス可能なリソース範囲・許可されるアクション等を事前に検証できる IAM Policy Simulator を紹介します。
続きを読むこの記事は Classi developers Advent Calendar 2021 の13日目の記事です。
こんにちは。開発本部プロダクト開発部学習チームでエンジニアをしています、藤田です。 本記事では AWS の IAM の Policy の定義から、アクセス可能なリソース範囲・許可されるアクション等を事前に検証できる IAM Policy Simulator を紹介します。
続きを読む開発本部の onigra です。今回の記事は、Classiのアプリケーション実行環境をAmazon EC2からECSに移行しているお話をします。
この記事では「Ruby on RailsのWebアプリケーションをECSに移行する上での技術的なトピック」ではなく、「なぜClassiはEC2からECSに移行する必要があるのか」「どのように移行を進めているのか」についてをお話します。
なお、この記事は Classi developers Advent Calendar 2021 11日目の記事です。昨日は データプラットフォームチームの滑川さんによる Cloud Composer 2へのupgradeでどハマりした話 でした。
私が入社した当初、Classiは前述の通りAmazon EC2で稼働していました。それ自体に問題は無いのですが、サーバのプロビジョニングとデプロイが遅く、不安定という課題を抱えていました。
また、普段プロダクトを開発・運用しているチームの中にデプロイ、インフラの知識や、既存の仕組みを把握しているメンバーが少なく、プロビジョニングやデプロイに何か問題があると、私のような組織横断的な技術課題に取り組むメンバーが対応にあたることが多々ありました。
近年、書籍 『LeanとDevOpsの科学』 でも語られているように、変更のリードタイムとデプロイの頻度は組織のパフォーマンスに大きく関わる要素であり、今後価値提供のスピードを上げていくにあたって大きな障害となるため、なんとか全社的に解決したい課題だと考えていました。
そんな中、 2020年の春に不正アクセスが発生し、その後サービスの高負荷によるアクセス障害が続く状態 になりました。
日々対応に追われる中、次から次へとサーバのチューニングやアプリケーションの修正をデプロイしなければならない状況で、デプロイとプロビジョニングの仕組みが大きなボトルネックになっていることをこの時に改めて痛感します。
また、今後Classiがセキュリティ面でもパフォーマンス面でもお客様からの信頼を回復しなければならない中で、今のままの仕組みではとても改善のスピードを上げることはできません。
この時、現状のEC2へのプロビジョニング、デプロイの仕組みを全て捨て、ECSに移行して1から作り直そうという決断をしました。
この時点で現場は日々の対応で疲弊していました。そんな状況を打破し、サービスの改善にポジティブな勢いを生むためには、移行する1つめのリポジトリの成果に大きく左右されると考え、確実に成功させる必要がありました。
そのため、最初の移行対象はコンテナ化の難易度が比較的低いWeb APIの機能のみを提供しているリポジトリを選択することにしました。
私はコンテナを普段から利用し、ECSを触った経験があったので、移行する上で知識の問題は無いのですが、コンテナの運用に慣れていないメンバーへレクチャーをしきれるのかという懸念がありました。
また、Classiには多くのリポジトリがあり、それらを1つ1つ移行していたらかなりの期間がかかってしまうことは容易に想像できます。そのため、移行作業と移行のレクチャーができる人員をスケールさせる戦略を練る必要がありました。
そのため、移行作業は以下のようにメンバーを巻き込みつつ、最終的に自分以外のメンバーがレクチャーを行えるような状態を目指して進めることにしました。
また、本番リリース直前は必ず一緒に「あと何をすればリリースできるのか」を確認する機会を設けました。 いわゆるリリーススプリントに臨むための準備です。以下のような内容を確認、レクチャーし、リリースマネジメントを行いました。
これらを移行作業の中でレクチャーすることによって、今後リポジトリ担当者が自立してサービスを運用できる状態になることを目指しました。移行の完了は終わりではありません、始まりなのです。
2021年12月現在、13のリポジトリが移行完了しています。
同じ課題感を感じていたメンバーがフォロワーシップを発揮し、2つめのリポジトリの移行作業を早々に完了させ、以降に続くメンバーの勧誘とレクチャーを積極的に行ってくれました。
そのおかげで予定よりも早く自分がサポーターの役割に移行でき、アプリケーション固有の問題や例外的な対応をメインに行うことによって、移行プロセスのボトルネックの解消にフォーカスすることができました。
移行するメンバーを募集した際、新卒や若手が積極的に手をあげて参加してくれました。私自身、キャリアの中でもトップレベルに困難な状況と感じていたのに、それを成長機会と捉え、できることをしようとする姿勢には強く勇気づけられました。
会社の危機的な状況に対し、若いメンバーからサービス改善に繋がるポジティブなムーブメントを起こせたことは、非常に大きな意義があったと思っています。
移行に参加したメンバーの1人である小川さんがECS化について書いた記事も是非ご覧ください。
私はチャットへのレスポンスが早い方なのですが、移行作業を行うメンバーが集まるチャネルではよりそれを心がけました。未知の作業を行うことに不安を感じているメンバーに対し、何か書き込めばレスポンスが返ってくる安心感を与えたかったからです。結果的にその行動はチャネルが盛り上がることに繋がり、コミュニティのようになりました。
社内にポジティブな雰囲気を起こすことと、移行しきったメンバーを称えて成功体験にしてもらうために、移行が完了したら担当したメンバーにオープンチャンネルで移行完了宣言してもらい、スタンプを可能な限りつけて盛大に祝うというセレモニーを必ず行っていました。

運用の知識を身につけたメンバーを触媒に、社内で徐々にサービス運用を改善する動きが浸透していきました。
まず、株式会社はてな様で行っている Performance Working Group を自主的に行うチームが現れました。その活動が他のチームに広がり、チームで個別に行うだけではなく、インフラチームが主催で行う組織横断的なPerformance Working Groupも定期開催されるようになりました。
また、定期的にSentryの整理やエラー内容の調査する取り組みも各チームで行われています。アプリケーションやエラー監視ツールはインシデント以前から導入されていたものの、これまではエラーが多すぎたり、使い方がわからないメンバーも多く、放置されがちだった状況から大きく改善されました。
これは、lacolacoさんがSentryについての継続的な活用支援を続けてきてくれたことも大きな後押しであったと感じています。
インシデント以前はシステムアラートの発生に対して、特定のメンバーしか反応しない・できない状態で、反応したメンバーが担当しているチームに「これ大丈夫ですか?」と伝えに行くことも多かったのですが、徐々に反応するメンバーが増えてきて、今では担当チームのメンバーがシステムアラート発生から真っ先に「確認します」と反応することがほとんどになりました。
これにはインフラチームが主体で行っていた、サービスのピークタイムの監視を当番制で行う取り組みが定常化し、インフラチーム以外のメンバーもその当番に参加するようになり、システムアラートへの対応経験を積んだメンバーが徐々に増えていったことも後押しになりました。
今となってはピークタイムの監視当番は、システムアラート対応のオンボーディングの役割も兼ねるようになりました。
移行作業をきっかけにインフラに興味を持ち、自主的にAWSの資格を受験して合格したメンバーも数名います。
AWS 認定 ソリューションアーキテクト - アソシエイト(SAA-C02) 試験に合格したので振り返る
受験費用は会社でサポートしているのですが、最初に受験したメンバーは会社で精算できるということを知らず、たまたまSlackで「この間の試験受かってよかった〜」という発言を見かけて「会社で精算できるから申請してね」と声をかけたこともありました。
また、理解の必要はあるが自分で構築することは少ないAWSのネットワーク(VPC、Subnetなど)について、移行に参加したメンバーが勉強会を開催したいと相談され、一緒に内容を考えてハンズオンを実施したりもしました。
監視についての記事を開発者ブログに執筆してくれるメンバーもいました。
AWS ECS監視のオオカミ少年化を防ぐために考えたちょっとしたこと Amazon EventBridge(CloudWatch Events)で動かしているバッチをDatadogで監視する仕組みを構築した話
現状維持を良しとせず、試行錯誤しながらアウトプットする姿勢はとても頼もしく感じます。
ここまで良かった点ばかり書いていますが、当然省みることもあります。
「移行に関わりたい」というメンバーが想定以上に多く、移行作業が勢いよく進んでしまい、私がコントロール仕切れないこともありました。また、私が移行作業しつつアクセス障害への対応も行なっていたため、当然作業の中でボトルネックになってしまうことも発生し、十分にサポート仕切れないまま進んでしまい、不安を感じさせてしまったメンバーもいました。私がボトルネックになってしまうことは、事前に予測できていたことでした。
移行のふりかえりを行なった際に、「表面的にうまくいってると評価されているECS移行のイメージと参加当初ギャップがあった」というフィードバックをもらいました。これは当時、十分なサポート体制を組めなかった状態を的確に指摘していると感じています。
結果、Classiでは現在ほとんどのサービスをECSで運用し、デプロイの安定化と頻度の向上に成功しました。また、移行作業を通して若手メンバーを中心に、全社的な運用力の底上げに繋げられたと感じています。最悪の状況から前を向けるようになったのは、間違いなくこの時に成長してくれたメンバーのおかげです。
一方で繰り返しになりますが、移行の完了は終わりではありません、始まりなのです。移行は価値提供のスピードを上げていくにあたっての最低条件でしかありません。また、「ほぼ」と書いた通り移行完了していないリポジトリは残っています。
引き続き、より良いサービスを運用していくために精進していきます。
この記事は Classi developers Advent Calendar 2021 の10日目の記事です。
こんにちは、データプラットフォームチームの滑川(@tomoyanamekawa)です。
Google CloudのCloud Composerのversion2(Cloud Composer 2)がpreview公開され、Terraformでも10月末から作成可能になりました*1。
「Cloud Composer 2ならworker数をautoscalingしてくれるらしい。そんなに設定変わらないだろうからサクッと移行しよう。」 くらいの軽い気持ちでCloud Composer 1からupgradeをしましたが、てこずってだいぶ時間を溶かしてしまいました。
そのハマったポイント4つとCloud Composer 2へupgrade完了した上での所感をまとめた記事です。
※追記:
2021年12月16日にgenerally available (GA)になりました。
https://cloud.google.com/composer/docs/release-notes#December_16_2021
*1:v3.90.0からnode_configを含めたCloud Composer 2をTerraformで作成できるようになった
composer: removed config.node_config.zone requirement on google_composer_environment (#10353) https://github.com/hashicorp/terraform-provider-google/releases/tag/v3.90.0
開発本部 認証連携チームでエンジニアをしている、id:ruru8net です。
これはClassi developers Advent Calendar 2021の9日目の記事です。
昨日の記事はこちらです。
Hardening 2021 Active Fault 参加レポート - 桐生あんずです
以前のClassi Advent Calender 2019では新卒が入社半年で社内サービスをリリースしてエンジニア楽しいってなったお話を書かせていただきましたが、あれから2年の間に業務の中で様々な経験をし、さらに知識やスキルを身につけていくことができました。
今日はその中でも自分が担当しているサービスの、バッチ監視の仕組みを考えたので紹介させてください。
担当チームでは毎日深夜2時にDBからデータを削除するバッチを動かしています。
他にも社内では様々なバッチが動いていますが、これらを監視する仕組みは社内で確立されていませんでした。
そのためサービス稼働に影響の少ないバッチは実行中に問題があったり、そもそも実行されていなかったりしても検知されず、見過ごされてしまうことが多かったです。
弊社ではサービスの監視にDatadogを使用しているため、この監視体制にそのままバッチの監視を組み込むことでバッチの監視ができていない状態を是正したいと考えました。
Ruby on Railsを使い、rake taskとして実行させています。
Amazon EventBridgeにてECS Fargateのタスクを起動させ、実行しています。これは既にdatadog-agentコンテナが動いている前提です。datadog-agentコンテナの設定方法は以下のURLを参考にしました。
https://docs.datadoghq.com/ja/integrations/ecs_fargate
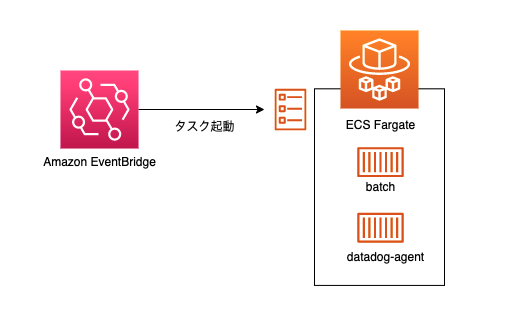
バッチ実行において監視したいことは以下です。
定期的な実行の成功と失敗
実行時間の異常
今回は定期的な実行の成功と失敗をメインとして、
バッチ実行中に例外が発生した場合の検知
バッチの起動自体がされなかった場合の検知
という監視の仕組みを作っていきます。
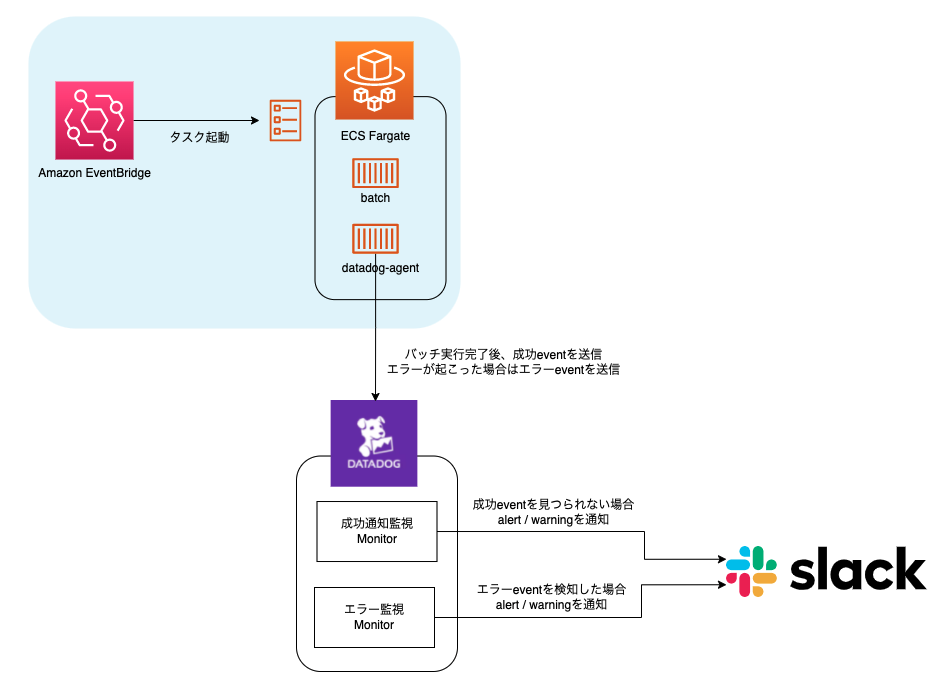
DatadogにEventを送信する方法は4つあります。
今回のようにsidecarコンテナとしてdatadog-agentを起動させているのであればDogStatsDを使ってEventを送るのがやりやすいと思います。
今回はRubyで書いているので基本的にはDatadogのドキュメントに書いてあるExampleと、使用するgemであるdogstatsd-rubyのドキュメントを参考にコードを書きました。 docs.datadoghq.com github.com
▽作成したバッチのスクリプトファイル
require 'datadog/statsd' task batch: :environment do begin begin # バッチの実行時間を計測 execution_time = Benchmark.measure do ### # 実行処理内容は省略 ### end statsd = Datadog::Statsd.new(logger: logger, single_thread: true, buffer_max_pool_size: 1) begin # バッチの実行が完了したら成功Eventを送る statsd.event( 'データを削除するバッチ', # Eventのタイトル "バッチ実行時間 #{execution_time.real}s", # 好きな内容をメッセージとして送れる alert_type: 'success', tags: ['env: development', 'service:rails-app'] # タグを指定 ) rescue => e logger.error e ensure statsd.close() end rescue => e begin # バッチ実行中に問題が発生した場合はエラーEventを送る statsd = Datadog::Statsd.new(logger: logger, single_thread: true, buffer_max_pool_size: 1) statsd.event( 'データを削除するバッチ', "#{e.class}:#{e.message}", alert_type: 'error', tags: ['env: development', 'service:rails-app'] ) logger.info 'Datadogへのエラー通知送信完了' rescue => e logger.error e ensure statsd.close() end end end end def logger Rails.logger end
statsd = Datadog::Statsd.new(logger: logger, single_thread: true, buffer_max_pool_size: 1)
statsdのインスタンスを作成します。
dogstatd-rubyのバージョンや必要に応じてオプションをつけてください。
https://github.com/DataDog/dogstatsd-ruby#migrating-from-v4x-to-v5x https://www.rubydoc.info/github/DataDog/dogstatsd-ruby/Datadog/Statsd
begin # バッチの実行が完了したら成功Eventを送る statsd.event( 'データを削除するバッチ', # Eventのタイトル "バッチ実行時間 #{execution_time.real}s", # 好きな内容をメッセージとして送れる alert_type: 'success', tags: ['env: development', 'service:rails-app'] # タグを指定 ) rescue => e logger.error e ensure statsd.close() end
eventメソッドが取れるパラメータやオプションはこちらに書いてあります。 www.rubydoc.info
またドキュメントに書いてある通り、DogStatsDのクライアントが不要になった時には適切に破棄をするためにstatsd.close()します。
https://app.datadoghq.com/event/stream にてeventの一覧が確認できます。
左上の検索欄に、eventのタイトルやタグで検索ができます。
このときの検索で、eventが一意に絞り込めるようなタイトル、タグをつけるようにしてください。
またメッセージの内容も一緒に出力されます。
ですので、ここに実行時間や、実行完了したときに欲しい情報を出力させておくと確認がしやすいです。
| 状態 | |
|---|---|
| 成功時 |  |
| 例外発生時 |  |
Monitors > + New Monitor > Event を選択します。
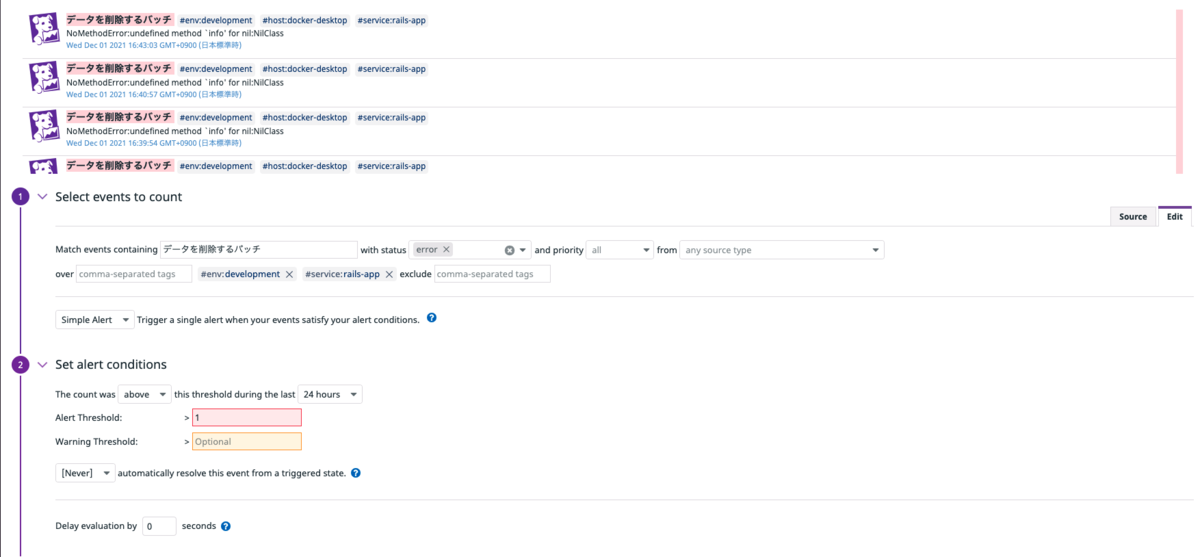
するとMonitor作成画面になります。今回は「バッチ実行中に例外が発生した場合の検知」と「バッチの起動自体がされなかった場合の検知」をする2つのMonitorを作成します。
エラーeventのみを絞り込むように設定し、alert conditionsをセットします。今回は24時間に一回動くバッチのため、24hoursを選択、また1つでもエラーeventを受け取ったらalertとして発火させたいのでAlert Thresholdを1にしています。
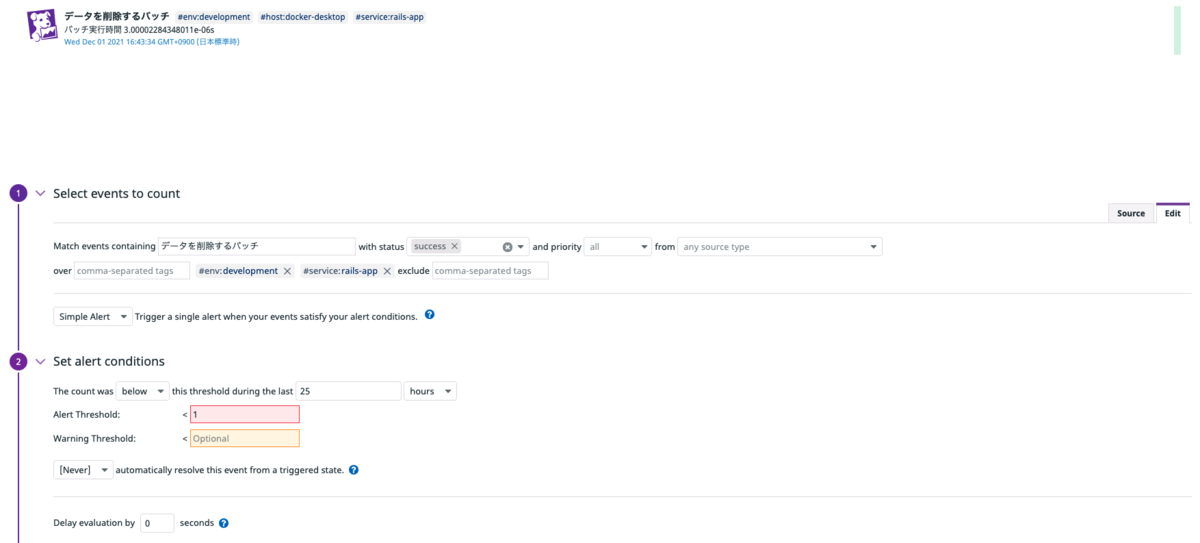
成功eventのみを絞り込むように設定します。
またeventをカウントする期間を24hoursにしてしまうと、前回のeventからきっかり24時間以内にeventが来ないとalertとなってしまうので、余裕を持たせるために25hoursにしておきます。
対象期間1つも成功eventがない場合はバッチの起動がされなかったとみなしalertを送るように、Alert Thresholdを1にします。
③で通知させたい先のslackチャンネル(slack-{チャンネル名}となっているもの)を選択します。
(DatadogとSlack連携のセットアップはこちら
https://docs.datadoghq.com/ja/integrations/slack/?tab=slackapplicationus)
④ではslackに投稿する際のテンプレートを作成します。
ここでは色々な変数やMarkdownが使えます。
Monitor作成時の右下にあるTest Notificationsで確認ができます。
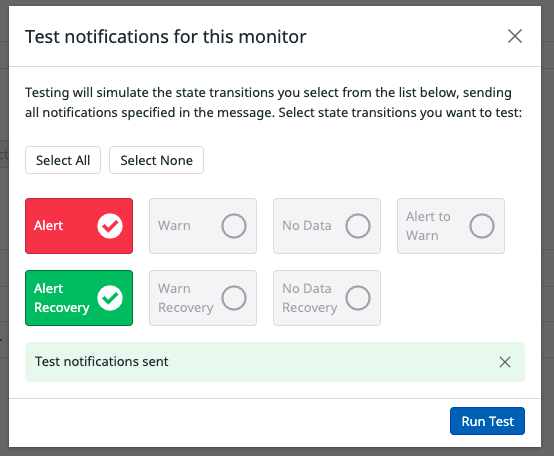
下のようにSlackに通知が送られるようになりました。
| バッチ実行中にエラーが発生した場合の通知 | バッチの実行確認ができなかった場合の通知 |
|---|---|
 |
 |
DogstatsDによるEvent送信はバッチ処理中への埋め込みがしやすくとても使いやすかったです。
またバッチに限らず監視の仕組みを考える時にはまず、「何を監視したいのか」を整理するのがとても大事だなと思います。
今回は実行の監視のみしかできていませんが、今後は実行時間がかかり過ぎていた場合にalertを発報できるような仕組みも監視の項目に入れていきたいです。
(現状はeventのメッセージに対してMonitorを作成する方法が見つからず、別の方法を模索中です。)
社内で確立されていなかったバッチの監視に対して、この仕組みを社内展開することができ、他のチームの人たちからも喜んでいただけたので嬉しかったです。
自分のチームだけでなく他のチームにとっても役に立つような仕組みづくりというのを意識して今後も頑張っていきたいです。
明日のClassi developers Advent Calendar 2021の担当はTomoya Namekawaさんです。お楽しみに。
この記事は Classi developers Advent Calendar 2021 の 7日目の記事です。
こんにちは。顧客サポート基盤チーム兼、技術戦略室にてエンジニアをしています、中島です。
みなさんは、日々仕事をする上で必須である「誰かに質問をする」という行為について、自信を持って適切に行うことはできているでしょうか?
先月弊社では外部講師である、株式会社フィッシャーデータのあんちべさん をお招きし、質問力向上のための研修を実施しました。今回はこの研修を実施するに至った背景、研修内容を少しお見せするのと、社内の反響をお伝えします。
弊社は2020年2月頃よりリモートワークへの移行を行い、1年半以上が経過しました。リモートワークのお困りごととして一般的にもよく聞かれる、コミュニケーションについての課題を見聞きするようになってきました。 (ちなみに私自身は2020年4月入社で、まだ片手で数えられるほどしか出社したことがありません)
特にコミュニケーションの一つである「質問をする」ということに対して、リモートワーク以前では気軽にできていた(ような気がする)のに機会が減ってしまったり、やり取りするのに時間がかかるようになってしまったり。
質問をする人も、回答する人も、双方ともになんだかしんどいぞ?と感じることが多くなってきました。 そんな時、とあるメンバーが「質問投げる時も受ける時も意識してもらえると助かるノウハウが多いよ」とあんちべさんのツイートをSlackで共有してくれました。
https://t.co/PrTfoAuhmN
— (あんちべ! 俺がS式だ) (@AntiBayesian) 2021年10月22日
技術的な質問を受けるとき、質問の内容が全然わからないこと多いんだけど、質問する側は1OIのつもりで回答者側から見たら2~3OIなことよくある。質問するということは技術で、ノウハウやアプローチがあるとまず理解して欲しい pic.twitter.com/moQF1Psql6
私は常々自分の質問の仕方が下手だなと感じることが多かったので、このツイートとツイート内にある記事にはとても感銘を受けました。本部長があんちべさんの質問の仕方研修を受けていたこと、その内容が今のClassiの課題にもマッチすることが多いのではないかという思いもあり、ぜひ具体的にお話しをお聞きしたく研修をお願いすることになりました。
研修の始めにまずあんちべさんより問われました、「質問とは何ですか?」と。
このような抽象的な質問をする背景としては、今回の研修の目的「質問力を上げたい!」という共通のゴールのためには共通の言葉の定義をし、まず認識を合わせる必要があるということでした。まずは「質問とは?」の定義を以下のようにはっきりとさせます。
「質問とは問題解決のアプローチである」
定義のあとでよくない(けどよくある)質問の例を挙げていただきました。
これらのことを理解した上で、どのように質問に立ち向かっていけばよいのかを学びました。
知らないことを聞くということは質問をする上での一つのHowであって、本当にやりたいことではありません。質問とは何なのかを正しく把握することが、正しい質問への第一歩と教えてもらいました。
どのような質問をすれば、成果に繋がるのでしょうか?ここでもまた「成果とは何か?」という問いを投げかけてくれました。成果を生み出すためには以下の3点セットが重要であるとのことです。
ここまでの前段で質問とは何かというマインドを学びました。どれか一つでは駄目で、3つ揃うことでより複雑な問題のゴール(成果)に向かっていけるということです。
ここからは後半です。具体的にどのような質問をすればよいのか?の方法論を学びました。
質問の手法として2つ挙げてくださいました。手法の詳細については調べていただければと思います。
質問の手法は背景次第で変わってくるため、どのような状態を自覚しているのか、質問者・回答者双方で認識を合わせる必要があります。そのために質問には「レベル感」があるということを学びました。
まずは以下の3段階から、どの状態の時にどういった質問をするべきか具体事例を元に理解しました。

※詳しく知りたい方は以下の記事を見ると更に理解が深まるかも知れません
「なんで教えて(回答して)くれないんだろう?」「なんでそんな質問するんだろう?」双方このように思ってしまい、社内の関係がギクシャクすることはありがちです。
「質問をする」という行為は、得てして「質問者による質問の仕方の改善」がフォーカスされることが多い気がします。ですが、回答者の存在も忘れてはいけません。双方ともに以下のような心得を持つことが重要だと学びました。

質問者の心得にもあるように、感謝の気持ちを示すという手段の一つとして、弊社で導入している Unipos といったピアボーナスでも伝えることができそうです。
質問のレベルも自覚できていて、心得も問題ないと思っている。しかし不安が拭いきれない場合のために、質問文を作るときのチェックリストを頂きました。

私自身できていなかったことばかりで、頭の中の整理をする上で非常に有用なリストと感じました。この内容をしっかりと考えることで解決策を思いついて質問しなくても良くなった!ということもありそうです。 このチェックリストは社内でもとても反響がありました (印刷して机に貼っておく!と言う人や、SlackでPinしている人も複数名いました)
質問のやり取りが終わった後、質問に対して不足がないかを確認する必要があります。以下が明確に得られていれば、次の動き出しもスムーズです。
質問をして回答をしてもらったけど、もやもやが残ることがたまにありました。これはAs is, To beを描けずに質問をしていたんだなと私自身気付くことができました。
弊社から挙がった質問を一部抜粋して掲載します。詳細を載せるのは控えますが、興味のある質問もあるのではないでしょうか?
質問者されたときに圧をかけずにいい質問者としての成長を促すにはどうしたらよいでしょうか? (やり方次第では詰める感じになってしまって難しそうに思いました)
なぜこの質問に回答するのか?を考えてから回答するとよいとお話しいただきました。
いただいた回答内容は上の方で資料を掲載した「質問者と回答者の心得」にもあるところですし、あらためて意識していけるとよさそうです。
そもそも質問が出にくい組織の場合、どのようなコミュニケーションの課題があると思いますか?
あんちべさんからよくある課題を共有していただいた上で、改善のためによく行っている打ち手を3つお話し頂きました。
回答者と前提や制約や諸々を共有できるように、丁寧に質問文を作った結果、Slack 上で結構なボリュームの文になり、回答者が「ウッ」ってなり、確認を後回しにされる経験が多くあります。オンライン上の適切な質問において、上記のような問題を軽減するテクニック等ありますでしょうか?
回答者としては、回答するために背景説明をしてほしい気持ちと、長文読みたくない!の矛盾した気持ちを持ってしまうことがあります。そのために質問者として心がけたほうが良い質問の仕方を教えてもらいました。
元々エンジニア向けに企画した研修でしたが、部署を超えエンジニア以外の方も含めて50名近く集まってくれました。講義内容は弊社メンバーも思い当たることや気付きも多かったようで、講義中のチャットも大変盛り上がりました。
研修後の実務では、これ質問力研修で習ったやつだ!と言ってくれるメンバーもいて、共通言語としてインストールできた気がして嬉しかったです。
Slackで感想を書いてくれたメンバーもいました🎉

質問力の向上に役立つ記事になりましたでしょうか?打席に立ち続け回数をこなしていかないと質問力は磨かれないということですので、学んだフレームワークを活かして実務に挑んでいこうと思います。
とてもためになるお話しをあんちべさんよりお聞きできて、大変感謝しています。ありがとうございました!
研修時に使用されたあんちべさんのスライドはこちらになります。
こんにちは。開発本部プロダクト開発部学習チームでエンジニアをしています、id:tkdn 武田です。
弊社もスポンサーとして後援していた JSConfJP へ参加してきましたので、今日はそのレポートと特に気になったセッションを中心に感想をまとめていきます。
なお、この記事は Classi developers Advent Calendar 2021 の 3 日目の記事です。
本カンファレンスは本年が 2 回目の開催です。前身となっている Node 学園祭が、各国で開催する JSConf といった冠のついた日本版 JSConf といった趣きのイベントとなり、2019 年から生まれ変わっています。私個人としては前身のイベントには 2017, 2018 に参加、JSConfJP 2019 に参加しているので、今回のオンラインイベント含めて 4 回目の参加になります。
今年は SpatialChat の会場が用意されスポンサーブースの設置もありましたが、自身の性格もあいまって話しかけるのは難しかったなという印象でした。Twitter でのハッシュタグつきの投稿は盛り上がっており、当日は私も見ていたセッションについて積極的にコメントしていました。
アーカイブが残っていますので見逃したセッションのある方や当日参加できなかった方は以下からご覧になれます。
最初に取り上げるのは Classi フロントエンドのプロジェクトに入っているツールの 1 つでもある Prettier、そのメンテナーである sosukesuzuki さんのセッション。そして、今年会社化され Deno Deploy など分散ホスティングサービスも展開する Deno、その中の人でもある kt3k さんによるセッションです。
sosukesuzuki さんのセッションで語られた印象的な部分は Prettier がエコシステムでどういった立ち位置にあるのかといったものです。
下記は TC39 Proposal の策定プロセスから、各ツールチェインに新しい構文がどう反映されどのパーサにどういった役割があるか発表のスライドから引用したものですが、かなり複雑な図に感じますね。
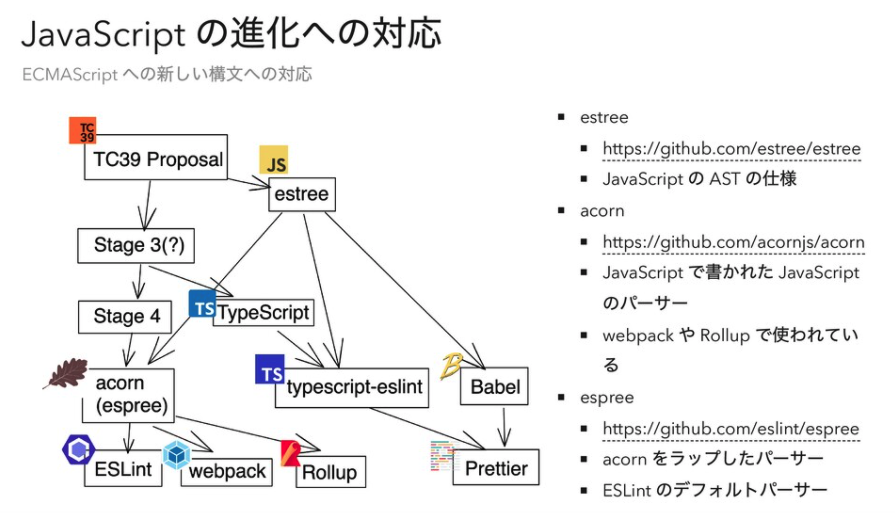
セッション後の質疑応答では sosukesuzuki さんの個人的な見解ではあるものの、「今の JavaScript を支えるツールチェインは歪な形をしている」という話が出ていました。
Rome などのオールインワンの OSS が代替ツールとして出てくることについても、各ツールが独自にもつパーサによる解析を統一すればコンピュータリソースの削減もできるし計算効率も高くなり無駄がなくなる、順当な流れなのではないだろうかというお話でした。このくだりは本当にいいお話だったので、執筆の際にも何度か繰り返し再生しています。
OSS のメンテナーが感じている所感をほかのソフトウェア(webpack, Babel)のメンテナーのインタビューも交えながらリアルな声を聞けたのは、OSS の実際というところを垣間見る良い機会となりました。
しばしば話題になる以下のようなメンテナー不足の issue を見るたびにユーザーとして心を痛める反面、ソフトウェアにできることは何なのかを考え、還元していかなければとあらためて感じました。
スライドリンク:Deno のこれまでとこれから JSConf JP 2021
一方で Deno は法人化しており Deno Deploy をベータで公開しながらも GA した際には収益化も検討しているプラットフォームでありカンパニーです。すでに GitHub においての採用が発表されていますし、つい先ごろ発表された Slack の新しい開発プラットフォームのバックエンドとしても採用されています。
kt3k さんから語られたのは Deno のこれまでの歩みとこれからについてでした。Deno は Node.js の作者でもあった Ryan Dahl が Node.js をデザインした際の後悔を元に、それらを克服したプロジェクトとして立ち上げたものです。

Ryan Dahl の後悔はいくつかあるようなのですが、その中でも実行環境におけるセキュリティサンドボックスのモデルについてをここでは取り上げています。
Node.js は実行時の許可なくファイルの読み書き、ネットワークアクセスなどが自由にできますが、Deno では実行時のパーミッションオプション(--allow-read, --allow-net など)を有効にしないとできません。実行時に明示的に権限を与える必要があるのです。これによって高いセキュリティを期待できる点も採用事例が増えてきた理由でしょう。
ですが、セッションでも語られたように 10 月に大きなロードマップの追加がありました。それが Node.js 互換モードです。おい待てよと、Node.js との差別化のために生まれたはずなのに迎合しているのでは、といった意見がコミュニティや社内から湧き上がったそうです。
Node.js 互換といった 180 度の転換が Ryan Dahl 本人からの発案であることも驚きですし社内では反対意見が多かったということも驚きですが、背景としては Deno をインストールするユーザー数の今のところ横ばいであるのも起因しているようです(質疑応答より)。
スライドでも登場しますが、卵が先か鶏が先かのプラットフォームの問題にも触れ、ユーザーが少なければそのプラットフォームで動くソフトウェアは増えず、ソフトウェアが少なければそのプラットフォームを使うユーザーが増えないという Deno が今直面している状況と、今回の Node.js 互換モードが紐付けられています。
こういった Deno の裏側を知ることができたのも興味深くおもしろい話でした。
最後に取り上げるのは yamanoku さんによる「アクセシブルなフロントエンド開発のこれまでとこれから」というセッションです。
この発表の前に yamanoku さんは「HTML だけで UI を作る限界、あるいは無理なくユースケースと向き合っていくためには」と題した発表も別の場でされており、そちらも強く私の印象に残った内容でした。

今回はその限界を示しながらもっとアクセシブルであるためには、といった内容が主題になっています。Web, HTML そして HTTP の父であるティム・バーナーズ・リーの引用も交えながら、アクセシブルとは普遍的に障害の有無に関係なく誰も使えることが本質だという力強い言葉に、Web が好きなフロントエンド開発者として冒頭から胸が打たれました。
そして肝心のアクセシビリティに関してですが、セッションの内容には恥ずかしながら自身にとっては初めて知ることが多く反省も多くありました。
たとえば SPA におけるルーティングの遷移後、スクリーンリーダーでの読み上げ時にページが変わったことを検知できないというデモを見て、初めて WAI-ARIA aria-live について認識できました。Angular では下記のような実装イメージで画面タイトルの変更をスクリーンリーダーを扱うユーザーに通知できます。
<div *ngIf="pageTitle$ | async as pageTitle" aria-live="polite"> {{ pageTitle }} </div>
発表のあとに調べると Angular CDK では LiveAnnouncer といったモジュールも提供されておりこちらもうまく活用できそうです。
@Component({/* ... */}) export class MyComponent { // ... constructor(liveAnnouncer: LiveAnnouncer) { liveAnnouncer.announce(this.pageTitle)); } }
ほかにも Custom Elements に直接 role 属性を与えずに JavaScript から内部的に与えるという Accessibility Object Model といった案もコミュニティから出ていると知りました。利用時に都度必要な属性を利用者が付与せず、Custom Elements の実装者が内部的に担保できるというのは納得の提案ではあります。
スクリーンリーダーへの対応というと身構えそうですが、スライドでも出てきたようにキーボード操作のタブフォーカスでアクセスが可能かといった小さなところからでも始められるはずです。UI が知覚可能であるかどうかということを気にかけるだけでも、考慮できるポイントが増えそうだと感じました。
Node 学園祭から参加し続け、今回は初めてのオンライン開催でしたが、オフラインと変わりなく JSConfJP を楽しむことができました。カンファレンスでは新たに気付くことも多く、今回は特に OSS やソフトウェアが成立するためのプラットフォームの話から、我々開発者はどうコミュニティに貢献するのかといったことをあらためて考えさせられる良い機会を得ることができました。
まだまだ数は少ないですが社内メンバーの登壇やコミットメントという形でも成果を発揮しながら、Classi は今後もコミュニティを通じて OSS への還元を目的に、利用技術のカンファレンスやイベントに支援していく予定です。
またカンファレンスで得た知識、特に今回はアクセシブルな UI を実装していくことなどを現場のプロダクト開発に持ち帰りたいと思います。
JSConfJP 運営の皆さま、ご苦労さまでした!
こんにちは、データAI部の滑川(@tomoyanamekawa) & 工藤( id:irisuinwl )です。 今日(2021-12-01)、2人でGoogle CloudのSecurity Summitに「Security Command Center から始めるクラウド セキュリティ運用」というタイトルで登壇してきました! その報告と発表内では話しきれなかった各施策の実装面の補足の記事です。
続きを読む© 2020 Classi Corp.