こんにちは、データエンジニアの石井です。 先日公開した記事「社内向けのデータ基盤から集計結果をReverse ETLしてサービスに組み込んだ話」で、ダッシュボード機能のリリースにより、Classiのデータ基盤が「社内用データ基盤」から「ユーザー影響あるシステムの一部」へ進化した話をしました。「ユーザー影響あるシステムの一部」への進化に伴い、データ基盤の品質担保は必要不可欠です。今回は、データ基盤の品質向上に取り組んだKANTプロジェクトについてご紹介します。
KANTプロジェクト
背景・課題
Classiのデータ基盤がユーザー影響あるシステムの一部になる前、つまり社内用データ基盤だった頃には以下のような課題がありました。
- データ基盤の状態把握
- マルチクラウドにおけるデータ基盤全体の状態把握ができていなかった
- データ基盤の実行状態(SUCCESS, FAIL, RUNNINGなど)の把握が、大量にSlack通知されているのみで全体像をつかめていなかった
- 結果として、データ連携がうまくできていなかったことが社内ユーザーからの連絡でわかったり、気づかないまま放置されたりすることがあった
- データ基盤の安定性
- 「データ基盤が安定している」という状態を明確に「定義」できていなかった
- それゆえ、定義されていないものは「計測」もできていなかった
- 計測したメトリクスをもとにした効果的な改善サイクルを回すことができておらず、どのような優先順位で「改善」を実施していけばよいかわからない状態だった
- データ基盤の処理の連続性
- 後段のGoogle Cloud側から前段のAWS側の処理の状態を把握できていなかった
- それゆえ、AWS側からGoogle Cloud側へ処理が移る部分で、処理が終わっているであろう時間にスケジュール実行する実装になっていた
- 最悪の場合、AWS側の処理が未完了の状態でGoogle Cloud側の処理が始まるとエラーとなりデータ連携が止まってしまう状態であった
目的
KANTプロジェクトの目的は以下の2点です。
- Classiのデータ基盤のジョブの実行状態の収集・集約・把握・監視および実行制御を責務としたデータ基盤監視システム(KANT)の構築(Classiではデータ関連のシステム基盤には哲学者の名前をつける慣習があります。)
- KANTで集約した情報をもとに、SLA/SLOを定め、KANT外のBIツールで可視化し、改善アクションを行う
KANTの構築
アーキテクチャ

実装内容
前提として、既存のデータ基盤では、Amazon RDSからAmazon S3にデータを出力する処理をAWS Glueで、S3→Google Cloud Storage→BigQuery部分の処理をCloud Composerで行っています。KANTが収集する実行状態はこの2箇所となります。データ基盤の詳しい実装にご興味があればこちらの記事で紹介しています。(Classiのデータ分析基盤であるソクラテスの紹介)
ジョブの実行状態の収集・集約
Glueの実行状態
AWS Lambdaで実装し、1時間おきにGlueのジョブの実行状態を取得し、Cloud Loggingに送っています。Glueのジョブの中でログを送らず、Lambdaでの外形監視をしている理由はジョブだけでなくGlue全体の監視を行うためです。例えば、何らかの理由でトリガーが発火せずジョブが実行されなかった場合、ログが送られず実行状態を把握できない、といったことを防ぐためです。収集したログはCloud LoggingのLogs Routerを使い、BigQueryに集約しています。 メトリクスは各ジョブの開始時刻と終了時刻、実行ステータスを収集しています。なお、ある処理が何月何日の実行分として動いているのかという日付も取得したかったのですが、ジョブとしてはこの情報は保持しておらず、取得は断念しました。
Cloud Composerの実行状態
Cloud Composerの処理のログをCloud Loggingに出力しています。収集したログはCloud LoggingのLogs Routerを使い、BigQueryに集約しています。メトリクスは各タスクの実行日(execution_date)、開始時刻(start_date)と終了時刻(end_date)、実行ステータスを取得しています。
ジョブの実行状態の監視
監視は、「Glueのエラー監視」「データ基盤の連携遅延監視」の2パターンを実装しています。
Glueのエラー監視
Cloud ComposerのDAGで実装しています。DAGは、ジョブの実行状態を集約したBigQueryを定期的に確認し、エラーがあればSlackへ発報するようにしています。以前は、Glueからのエラー発報ができておらず、後段の処理のCloud Composerが動かないことでようやく気づくという状態でしたが、KANT実装後はGlueのエラーにも気づくことができる状態となっています。
データ基盤全体の遅延監視
上記と同様、Cloud ComposerのDAGで実装し、ジョブの実行状態を集約したBigQueryを定期的に確認します。データ基盤がプロダクトレベルになるにあたり顧客に遅延なくデータを届けられるよう、各処理ごとに「〇〇時までに処理が完了している」というSLOを定め、そのSLOを満たしていない場合に遅延アラートをSlackに発報するようにしています。
ジョブの実行制御
前述のように、以前は前段のGlueの実行状態にかかわらず、後段のCloud Composerをスケジュール実行していました。KANT実装後は、Cloud Composerの1つ目のDAGの前に新たなDAGを追加しています。新たなDAGは、ジョブの実行状態を集約したBigQueryを見に行き、Glueの処理が完了しているかを確認します。Glueの処理が完了していれば、既存のデータ基盤の1つ目のDAGをキックするように実装しています。
可視化とその効果
可視化は、集約したBigQueryをデータソースとしTableauで行いました。以下で可視化の一部をご紹介します。
Glueの各ジョブ、Cloud Composerの各タスクの実行時間の可視化
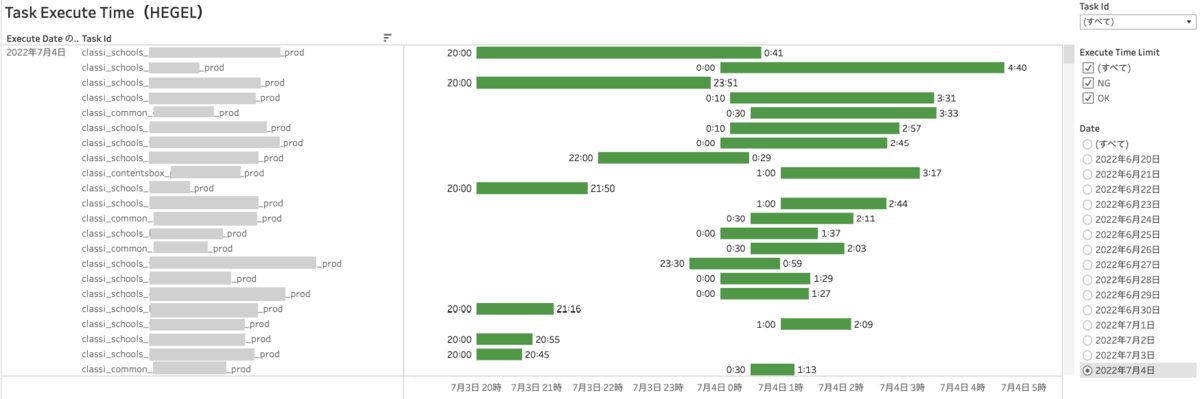
GlueとCloud Composerの処理ごとの実行時間を可視化しました。可視化以前は数百ある処理ごとに開始時刻と終了時刻をSlack通知で垂れ流しているのみだったところ、現在では以下の情報をまとめて表示でき、一目で全体像が把握できるようになりました。
- 各処理の開始時刻と終了時刻
- 各処理に要した時間
- 各処理と他の処理との処理時間の比較
- 各処理の終了時刻が終了想定時刻より遅いのか否か
処理の状態を把握するだけではなく、実行に長時間要している処理や終了時刻が想定時刻を過ぎている処理をこのビューから把握し、該当する処理をチームで優先的に改善していきます。例えば、下図の終了時刻が想定時刻(AM6:00)を過ぎている処理に対し、分散処理の実装や開始時刻の調整を行い、実行に要する時間と終了時刻の改善をしました。


SLO/SLAの達成度の可視化
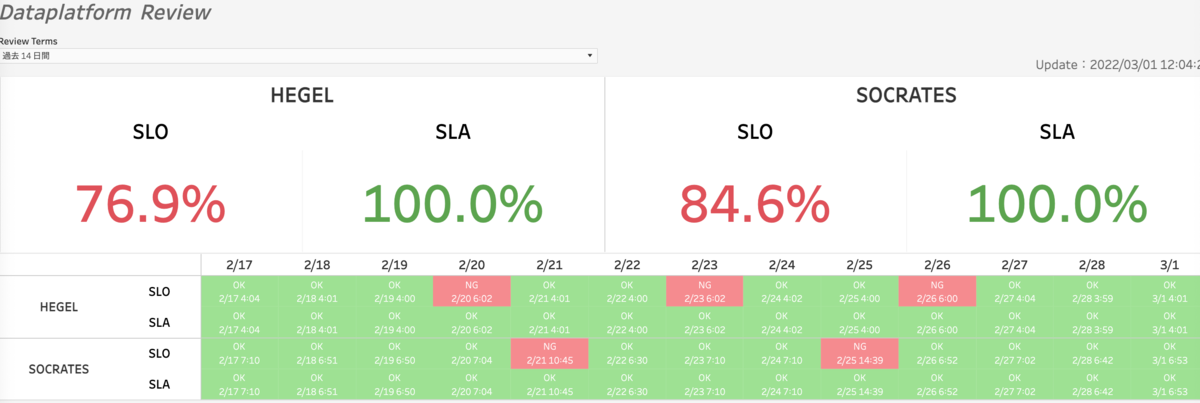
Classiのデータ基盤では、「◯◯時までに処理が完了している」というSLOと「障害の際にその日中に復旧させる」というSLAを定めています。上部にSLO/SLAを達成した日数の割合(%)を表示し、その下に日付ごとのSLO/SLAの達成状況を表示しています。HEGELの部分はGlueの処理を表し、SOCRATESの部分はCloud Composerの処理を表しています。 この可視化により、「現在のデータ基盤が安定しているかどうか」の共通認識をチームで持つことができるようになりました。
また、下の2つの図は2021/08時点(※)と、2022/06時点のSLA/SLOの達成状況です。前述の「Glueの各ジョブ、Cloud Composerの各タスクの実行時間」のビューや今回紹介しきれなかったその他のビューをもとに改善点の優先度をつけてデータ基盤の改善に取り組んでいった結果、データ基盤全体の連携速度が向上し、SLOが飛躍的に改善したことがわかるかと思います。
チームでは、2週間に一度のレトロスペクティブの際にSLO/SLAの達成率を確認しています。毎回改善されていくSLO/SLAに達成感を感じ、チームの士気が高まることもKANTプロジェクトの効果だと思っています。
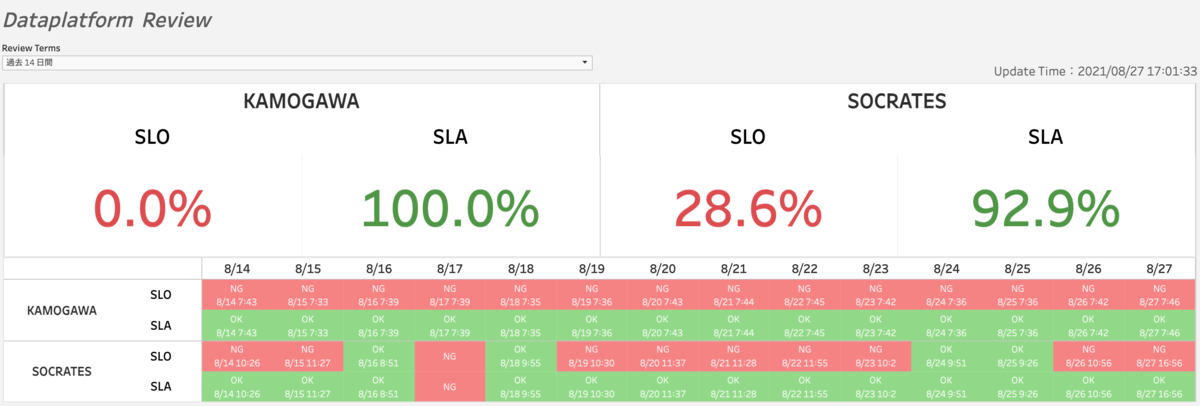
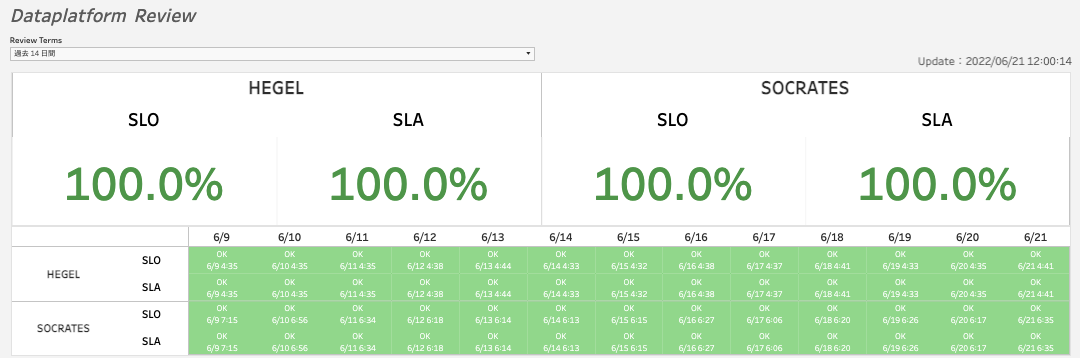
※KAMOGAWAはHEGELの前身です。千葉の鴨川が由来です(哲学者じゃないんかいw)。KANTで明らかになったGlue処理の問題点をリファクタした際にHEGELに生まれ変わりました。
データ監視基盤の進化とさらなる品質の向上に向けて
データ監視基盤は実行状態の収集・集約・把握・監視および実行制御が責務である、と冒頭で紹介しました。しかし、障害時の再実行や自動復旧など実行制御についてはまだ不十分な点があります。また、今回はデータ基盤の品質向上に取り組みましたが、この他にも、データ基盤で処理する中でデータの欠損や重複が発生していないか、データソースと同じデータが連携されているか、など連携されるデータそのものの品質向上にも今後取り組んでいかなければなりません。
上記のように「データ監視基盤」「品質」というキーワードだけでもまだまだやることはあります。 Classiのデータ基盤を開発しているチームでは、各人が主導するプロジェクトを持ちながらも時にはプロジェクトのスピードアップや各人のスキルアップを目的に、タスクを共有し協力して開発を行なっています。そういった環境でスキルアップをしてみたい方は以下よりご応募ください!