Classi で提供している学習トレーニング機能を裏で支えているコンテンツ管理システム ( 以下、内部 CMS ) では、バックエンドに GraphQL を採用しています。 この GraphQL は Classi 内の様々なシステムで広く利用されています。
内部 CMS の開発チームでは、この GraphQL スキーマの API ドキュメントを自動生成して GitHub Pages でホスティングしています。
GitHub Pages は GitHub Actions ワークフローを作成するだけで簡単に静的サイトをデプロイすることができます。また、 Classi では GitHub Enterprise Cloud を利用しており GitHub Pages のアクセス範囲を制限することもできるため、社内向けドキュメントも安全にホスティングすることが可能です。
GitHub Pages でホスティングすることで社内メンバーはいつでも簡単に API ドキュメントを参照できるため、チーム内外を問わず GraphQL スキーマに基づいた議論やコミュニケーションを円滑にする上で非常に役に立っています。
API ドキュメントの自動生成には Magidoc を使用しています。
この記事では Magidoc を利用して GraphQL スキーマから API ドキュメントを自動生成し、生成したドキュメントを GitHub Pages でホスティングする方法を紹介します。
Magidoc について
Magidoc は GraphQL スキーマから API ドキュメントを自動生成するためのツールです。API ドキュメントは HTML 形式で生成されます。
- リポジトリ : magidoc-org/magidoc
- 公式サイト : magidoc.js.org
実際にどのようなドキュメントが生成されるのかは以下のサイトで確認できます。
Magidoc の使い方
1. インストール
Magidoc CLI は npm パッケージとして提供されているため、 npm コマンドでインストールできます。
# グローバルにインストールするコマンド例 $ npm install -g @magidoc/cli@latest
インストールが完了すると magidoc コマンドが実行できるようになります。
$ magidoc --help Usage: Magidoc [options] [command] Magidoc CLI helps you build beautiful and fully customizable GraphQL static documentation websites in seconds. Options: -V, --version output the version number -h, --help display help for command Commands: generate [options] Generates a full static website using a template. Using this command gives you access to a limited range of customization. If you wish to customize the website further than what is available, use the eject command. preview [options] Preview the documentation website generated with the generate `generate` command. dev [options] Starts a development server with hot-reload as changes occur to watched files. eject [options] Ejects from Magidoc basic template configuration, to allow for full customization of the template. This will initialize a folder from a template of your choice, which can then be modified however you wish. help [command] display help for command
もちろん npx コマンドで実行することもできます。
$ npx @magidoc/cli@latest --help
2. 設定ファイルを作成する
Magidoc の設定は magidoc.mjs というファイルに記述します。
// magidoc.mjs
export default {
introspection: {
type: "sdl", // スキーマをファイルから読み込む場合は "sdl" を指定する
paths: ["schemas/**/*.graphqls"], // スキーマファイルのパスを指定する
},
website: {
// テンプレートを指定する
// v6.1.0 時点でデフォルトで用意されてるのは "carbon-multi-page" のみ
template: "carbon-multi-page",
// Web サイトのルートパスを指定する
// Public な GitHub Pages の URL は https://<オーナー名>.github.io/<リポジトリ名>/ のようになるので、
// ここには "/<リポジトリ名>" を指定する必要がある
siteRoot: "/example-repository",
},
};
他にも様々な設定が用意されています。以下はその一例です。
- URL から GraphQL スキーマを読み込む
- 設定ファイルに直接 GraphQL スキーマを記述する
- カスタムページを追加する
- etc.
詳細については公式ドキュメントをご参照ください。
3. API ドキュメントを生成する
magidoc generate コマンドで API ドキュメントを生成することができます。
$ magidoc generate
# npx を使用する場合
$ npx @magidoc/cli@latest generate
生成されたドキュメントは ./docs/ ディレクトリに出力されます。
( 出力先は設定ファイルで変更可能 )
docs/ ├─ index.html ├─ _app/ │ └─ ... ├─ introduction/ │ └─ ... ├─ mutations/ │ └─ ... ├─ queries/ │ └─ ... └─ types/ └─ ...
生成されたドキュメントをローカルで確認するには magidoc preview コマンドを実行します。サーバーが起動し、 http://localhost:4000 からドキュメントを閲覧することができます。
$ magidoc preview
# npx を使用する場合
$ npx @magidoc/cli@latest preview
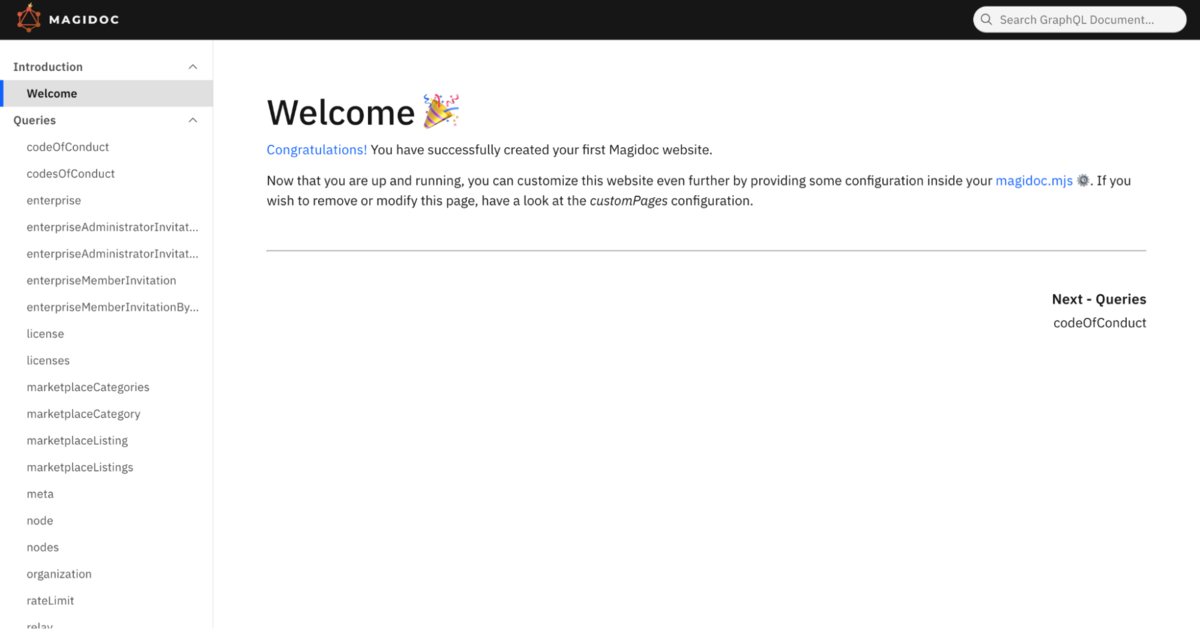
生成したドキュメントを GitHub Pages にデプロイする
GitHub Pages にデプロイするには以下の 2 通りの方法がありますが、今回は GitHub Actions からデプロイする方法を紹介します。
- ブランチからデプロイする
- GitHub Actions からデプロイする ← 今回紹介するのはこちら
それぞれの方法の詳細については公式ドキュメントをご参照ください。
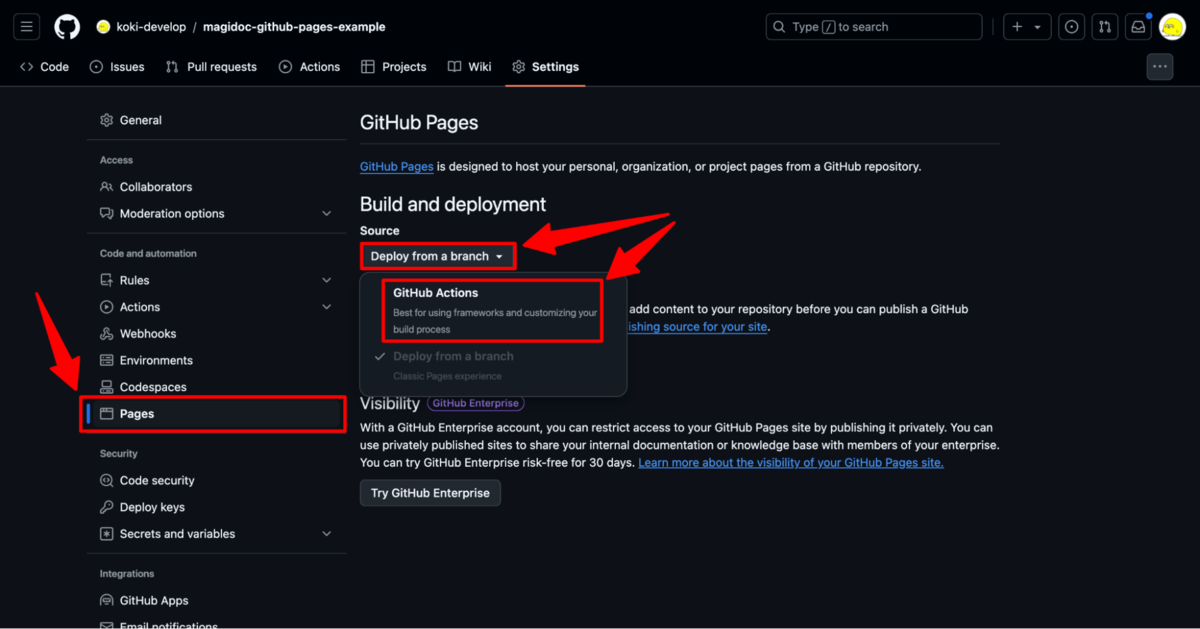
1. GitHub リポジトリの設定
GitHub リポジトリの Settings をクリックして設定画面に遷移します。
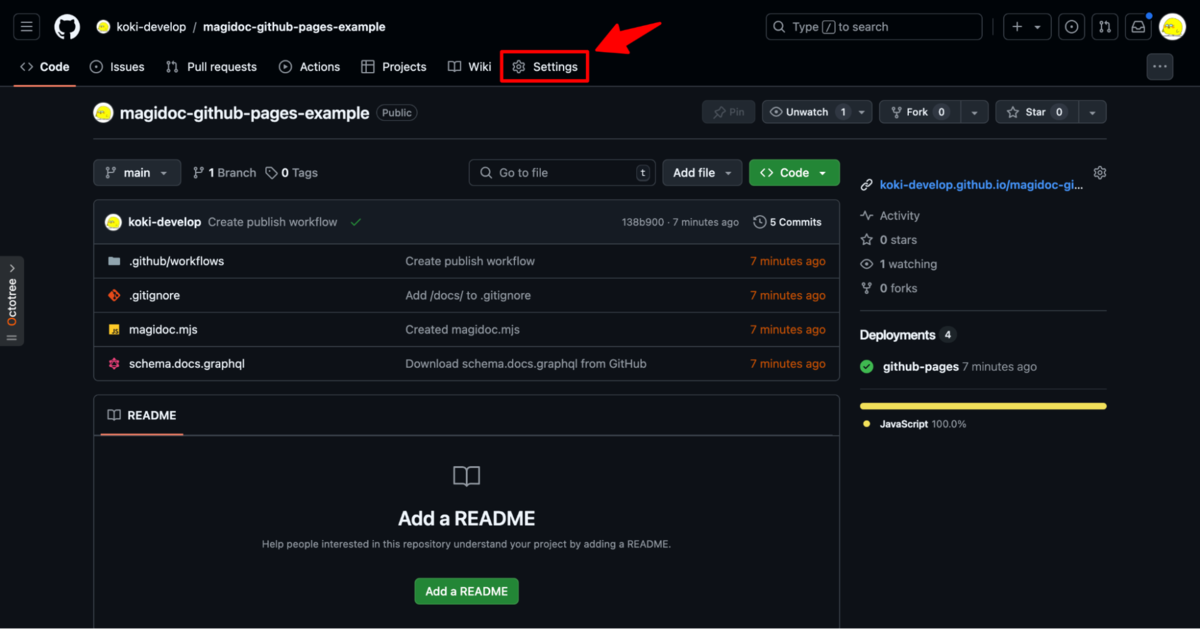
左サイドメニューから Pages をクリックして、 Source を GitHub Actions に設定します。
2. GitHub Actions ワークフローを作成する
GitHub Actions から GitHub Pages をデプロイするには以下の 2 つのアクションを利用します。
- actions/upload-pages-artifact
- GitHub Pages にデプロイするファイルをアップロードするアクション
- actions/deploy-pages
- アップロードしたファイルを GitHub Pages にデプロイするアクション
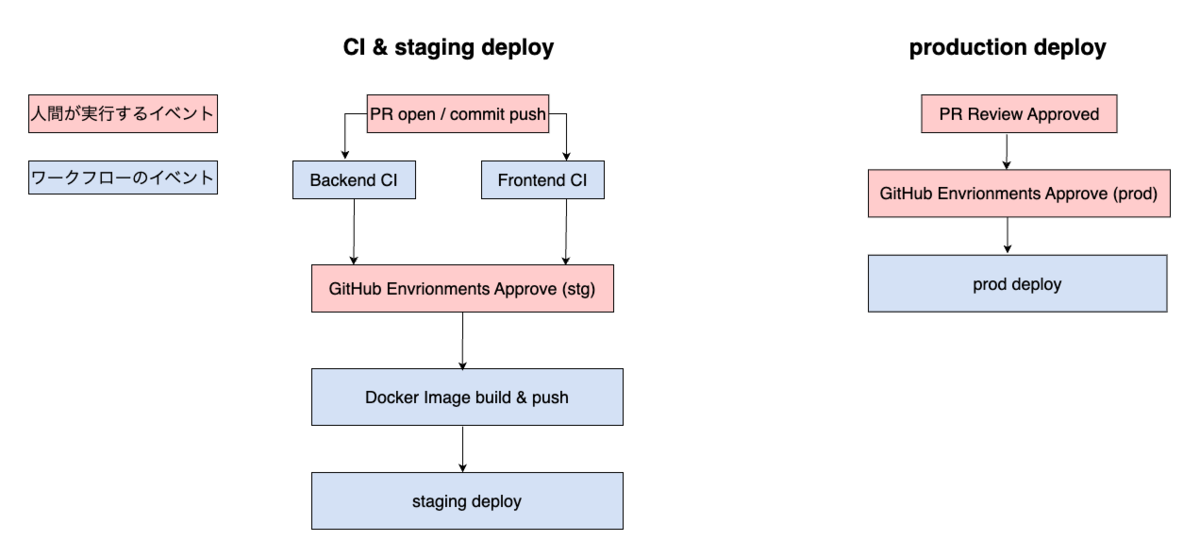
ワークフローは以下のようになります。この例では、 main ブランチに変更が push されるたびに GraphQL API ドキュメントを生成して GitHub Pages にデプロイします。
name: Publish API Docs on: push: branches: - main jobs: publish-api-docs: runs-on: ubuntu-latest permissions: contents: read # actions/deploy-pages に必要な権限 # 参考: https://github.com/actions/deploy-pages#security-considerations pages: write id-token: write environment: name: github-pages url: ${{ steps.deployment.outputs.page_url }} steps: # setup - uses: actions/checkout@v4 - uses: actions/setup-node@v4 with: node-version: 20 # build - run: npx @magidoc/cli@latest generate # publish - uses: actions/upload-pages-artifact@v3 with: path: ./docs - uses: actions/deploy-pages@v4 id: deployment
GitHub Pages へのデプロイが完了すると https://<OWNER>.github.io/<REPOSITORY> から API ドキュメントを閲覧できるようになります。
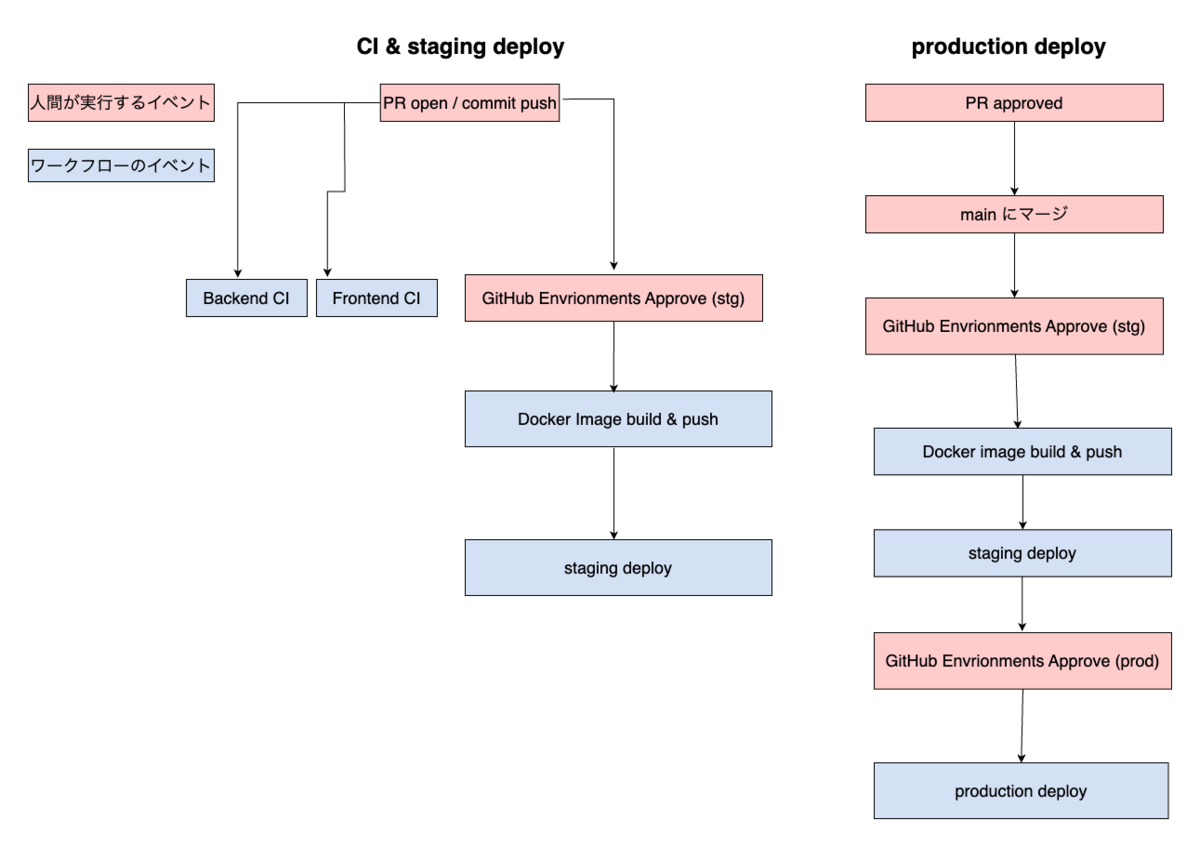
冒頭で紹介した内部 CMS の GraphQL API ドキュメントのデプロイでは、実際には以下のようなワークフローを作成しています。内部 CMS の GraphQL スキーマのリリースには googleapis/release-please-action を利用しているので、 release_created output を参照することで「新しいバージョンがリリースされるたびに API ドキュメントを更新する」ということを実現しています。
name: Release Please on: push: branches: - main jobs: release-please: runs-on: ubuntu-latest outputs: release_created: ${{ steps.release-please.outputs.release_created }} steps: # ...省略 - uses: googleapis/release-please-action@v4 id: release-please with: release-type: node publish-api-docs: needs: - release-please # 新しいリリースが作成されたときに API ドキュメントを更新する if: ${{ needs.release-please.outputs.release_created == 'true' }} # ...省略
まとめ
リッチな API ドキュメントがあるとテンションが上がります。
よりイケてるドキュメントにするために設計や説明文もしっかり書こうという気持ちになりますね。モチベーション大事。