こんにちは、プロダクト開発部の藤田です。
今回は Amazon ECS(以下、ECS) と AWS Step Functions(以下、Step Functions) を組み合わせた「ワンショットタスクの実行基盤」についてご紹介します。
「ワンショットタスク」とは、指定されたコマンドやスクリプトを1度だけ実行して、終了するタスクのことです。
このようなワンショットタスクは「プライベートネットワークの内側にあるリソースへのアクセスが必要な、非定型的な操作」を実行する際などに用いられます。
例えば、プライベートネットワークの内側にある DB に対して、以下のような作業をエンジニアが実施する際に、ssh を利用して踏み台サーバーに接続して、決められた手順書を実行する・・・といったような場面を想像していただければ、イメージしやすいと思います。
DB にテーブルを追加するための migration 実行
DB のマスターデータにレコードを追加
DB の特定のテーブルのレコードの一斉置換
DB の不要になったデータの一斉削除
実行したい操作の内容や時期も不定であり、作業に必要な踏み台サーバーは常にプロビジョニングされている必要はありません。
一方で、一般的には、商用環境に対するあらゆる操作の監査ログを収集・保持するというガバナンス要件があります。
これらの要件を満たすワンショットタスクの実行基盤を ECS と Step Functions で構築しました。
また、今回構築した「ワンショットタスクの実行基盤」は実行するスクリプトのランタイムに基本的に依存しない汎用的な仕組みであるため、参考になれば嬉しいです。
本記事の Appendix に Terraform コードの例を添えて、具体的な構築方法をご紹介します。
ワンショットタスクの仕組みが必要な背景
我々のチームでは Go 言語で実装された Web API の開発と運用を行っており、対象の API は ECS サービスとして実行されています。
この Web API は GraphQL を採用しており、GraphQL schema の管理方法については以下の記事でも紹介されているのでご参照ください。
また、データストレージとして Amazon Aurora を採用しています。
日々、機能の拡充や改善を進めていく過程で、DB のテーブル定義の追加・変更が求められたり、別のテーブルへのデータ移行や不要データの削除などが必要になったりすることもあります。
これまではこのようなデータのメンテ作業が発生した際は
エンジニアが作業手順書を作成する
エンジニアが作業手順書をレビュー・承認する
(二人以上のエンジニアがダブルチェック用に立ち会いながら)エンジニアが ssh を利用して踏み台サーバーに接続して、手順書の内容を実行する
といった作業を行っておりました。
しかしながら、上記のような運用では、本番の踏み台サーバーに ssh で接続するためには事前に管理部門からの承認が必要でそれらの手続き完了までに一定のリードタイムが必要となります。
仮に管理部門から承認されたとしても、ssh を利用して踏み台サーバーに接続した後は作業者が持っている権限の限りではどのような操作も行えてしまうので、作業ごとに最小限の操作を許可する設定を入れるといった複雑な運用をしない限りは、本当の意味でセキュリティ上安全とは言えません。
また、事前に作成した手順書を指定された順番通りに実行する際も、手順書のコピペミスなどのヒューマンエラーが発生する可能性は否めません(そのためのダブルチェックではありますが)。
上記のような理由からかもしれませんが、実際、自分自身もデータのメンテ作業が必要な機能改修に着手する際の心理的ハードルは高く感じていました。
この状況に課題を感じ、データのメンテ作業を安全に単純化できる仕組みの構築を進めることとなりました。
ワンショットタスクの仕組み構築の方針
go run コマンドで ECS タスクとして実行できる形にする
前述した通り、我々のチームでは Go 言語で実装された Web API を ECS 上でホストしており、ECS 上で稼働している API 用の ECS タスクはデータの読み書きを行っているため、データのメンテ作業の対象となる DB と接続している状況です。
つまり、API 用の ECS タスクと同様の条件下で、実行するコマンドだけをデータのメンテ作業用の内容に書き換えて実行することができます。
Go 言語では go run <スクリプトのファイル> で、実行したいプログラムをビルド&実行できるため、データのメンテ作業の種類ごとにスクリプトを実装して、ECS タスク上で go run を実行させることは容易でした。
また、API を実装しているリポジトリでは CI/CD を構築しており、テスト対象が API からデータのメンテ作業用のスクリプトに変わったとしても、想定する振る舞いを検証することに対してハードルはありませんでした。
スクリプトの実行前と実行後のデータの変化さえも単体テストで検証できる上、スクリプトの実装やテストケースの網羅性をコードレビューの中でレビューできる点が、開発者にとって非常に良い体験となっています。
更に、チームでワンショットタスクで実行するスクリプトをコードレビューするため「事前にチームでレビューしたコードのみが実行される」という点が保証されます。
加えて、ECS タスクで実行する場合はタスクにアタッチする IAM Role で権限制御も容易であるため、セキュリティ面も改善されていると言えます。
ワンショットタスクを簡単に実行できるようにする
ECS の RunTask API では、実行する ECS クラスターや ECS タスク定義の指定も可能ですし、containerOverrides で実行する command も override できます。
そのため、この時点でデータのメンテ作業の作業者が ECS の RunTask の API を実行する(もしくは aws cli で run-task を実行する)ことで、実装・レビュー済みのスクリプトを ECS タスクとして実行可能になっています。
ただし、RunTask 呼び出しの際に指定すべきパラメーターが数多くあるため、そこにもヒューマンエラーの余地が多くあります。
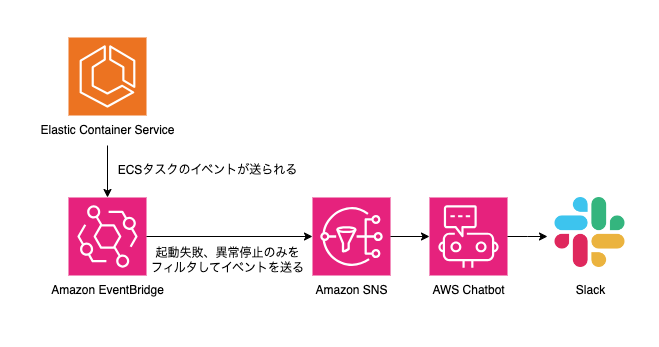
そこで、ECS の RunTask の呼び出しを Step Functions を介して行うようにします。
Step Functions ではこちら で記載がある通り、ECS の RunTask の呼び出しを標準のステップとしてサポートしており、与えられるパラメーターも ECS の RunTask API に準じています。
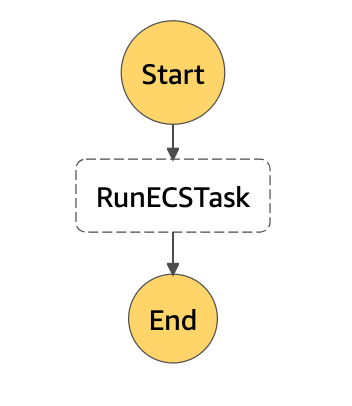
構築する Step Functions の全体像は下図の通りです。
Step Functions の全体像
作業者が Step Functions を起動して、RunECSTask というステップを実行して、終わるといったシンプルなものになっています。
また、作業者が Step Functions を起動する際に渡す引数のイメージは下図の通りです。
Step Functions の実行画面
“commands”: [“cmd/sample/main.go”] といった引数のみで、go run で実行したいスクリプトのパスのみを指定するといったこれまたシンプルなものになっています。
実際は RunTask を実行するためには、以下のパラメーターを指定する必要があります。
実行する ECS クラスター
使用する ECS タスク定義
ECS タスクを実行する際の Subnets や SecurityGroup といった NetworkConfiguration
ただし、上記のパラメーターは我々のチームの運用においては毎回変更・指定したいものではないため、作業者が都度意識するべき設定ではありません。
そのため、これらの設定は Step Functions の定義の中にハードコーディングして、Step Functions の実行者が意識するのは「実行したいスクリプトのパスのみ」という設計が開発者の体験として負担が少ないという結論になりました。
Step Functions でワンショットタスクを実行する際のメリット
データのメンテ作業用のスクリプトを go run で実行できる形で実装する
Step Functions で ECS のタスクの実行を簡単にできるようにする
上記の2つの方針で構築を進めた結果、我々のチームでは Go 言語でスクリプトを実装し、実装したスクリプトのパスを引数に Step Functions を実行するだけでデータのメンテ作業を簡単に、かつ、安全に進めることができるようになりました。
他にも、この仕組みを使った運用にはメリットがあります。
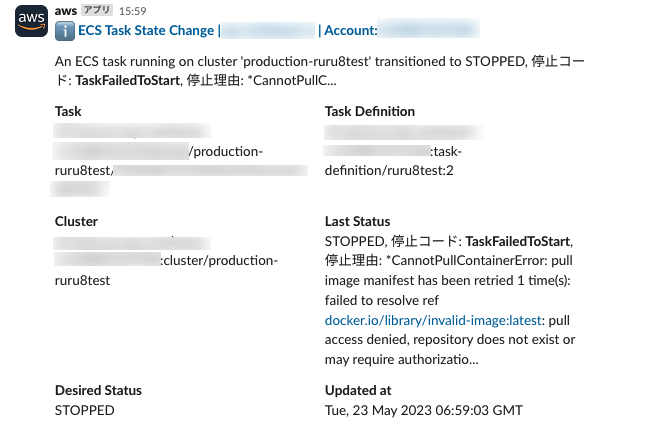
データのメンテ作業の履歴の保存
Step Functions は標準で下図のように実行の履歴が残ります。
Step Functions の実行記録
この履歴はそのまま、データのメンテナンス作業の作業履歴として扱うことができます。
履歴一覧の時点で、開始と終了の日時と成否のステータスが分かります。
更に、各実行の詳細も下図のように確認が可能で、Resource から実際に実行された ECS タスクへのリンクに飛ぶことができます。
(※下図では説明の都合上、一部のステップを除外して表示しています)
Step Functions の実行詳細例
ECS タスクの設定で Amazon CloudWatch Logs(以下、CloudWatch Logs) 等に実行スクリプトのログを出力するようにしておけば、後から当時の実行ログを参照することも可能です。
また、Step Functions の各ステップの実行ログを CloudWatch Logs に出力することも、AWS X-Ray にトレースを送信することもできます。
つまり、データのメンテナンス作業に関わる記録は、必要な設定さえ行えば AWS のサービスを利用して残すことができるのです。
他のチームへの知見・仕組みの共有しやすさ
我々のチームに限らず、Classi 社内では API などは ECS を使ってホスティングすることが多いです。
アプリケーション開発の技術スタックに関しては Ruby on Rails が多いのですが、Rails の場合でも事前に実装した rake タスクを ECS タスク上で実行可能ですし、他の言語に関しても同様の仕組みがあることが多いでしょう。
そのため、Step Functions の構築方法を模倣できれば、社内に関して言えば、基本的に実装のランタイムに拠らず今回のワンショットタスクの仕組みは他のチームでも採用しやすいです。
幸い、今回の Step Functions は Terraform を使ってコード化して管理可能なので、既に Classi 社内でも他のチームにも知見を共有して、使ってもらっています。
この記事の最後に appendix として Terraform のサンプルコードを載せていますので、記事を読んでくださった皆様のチームでもご活用いただけると幸いです。
Appendix
resource "aws_sfn_state_machine" "enjoy_ecs_run_task" {
definition = jsonencode ({
StartAt : "RunECSTask" ,
States : {
RunECSTask : {
Type : "Task" ,
Resource : "arn:aws:states:::ecs:runTask.sync" ,
Parameters : {
Cluster : “実行する ECS クラスターの arn”,
TaskDefinition : “実行したい ECS タスク定義の arn”,
LaunchType : "FARGATE" ,
NetworkConfiguration : {
AwsvpcConfiguration : {
SecurityGroups : [ “ECS タスクを実行する際の SecurityGroup”] ,
Subnets : [ “ECS タスクを実行する際の Subnets”]
}
} ,
Overrides : {
ContainerOverrides : [
{
Name : "ecs-task-run" ,
"Command.$" : "$.commands"
}
] ,
}
} ,
End : true
}
}
} )
role_arn = aws_iam_role.enjoy_ecs_task_run.arn
name = "enjoy-ecs-task-run"
type = "STANDARD"
}
data "aws_iam_policy_document" "assume_role_step_functions" {
statement {
actions = [ "sts:AssumeRole" ]
effect = "Allow"
principals {
type = "Service"
identifiers = [ "states.amazonaws.com" ]
}
}
}
data "aws_iam_policy_document" "enjoy_ecs_task_run" {
statement {
effect = "Allow"
actions = [ "ecs:RunTask" ]
resources = [ “実行したい ECS タスク定義の arn”]
}
statement {
effect = "Allow"
actions = [
"ecs:StopTask" ,
"ecs:DescribeTasks"
]
resources = [ "*" ]
}
statement {
effect = "Allow"
actions = [
"events:PutTargets" ,
"events:PutRule" ,
"events:DescribeRule"
]
resources = [ "arn:aws:events:{$region}:{$accountID}:rule/StepFunctionsGetEventsForECSTaskRule" ]
}
}
resource "aws_iam_role" "enjoy_ecs_task_run" {
name = "enjoy-ecs-task-run-state-machine-role"
assume_role_policy = data.aws_iam_policy_document.assume_role_step_functions.json
}
resource "aws_iam_role_policy_attachment" "enjoy_ecs_task_run" {
role = aws_iam_role.enjoy_ecs_task_run.name
policy_arn = aws_iam_policy.enjoy_ecs_task_run.arn
}
resource "aws_iam_policy" "enjoy_ecs_task_run" {
name = "enjoy-ecs-task-run-state-machine-policy"
policy = data.aws_iam_policy_document.enjoy_ecs_task_run.json
}