フロントエンドエキスパートチームのlacolacoです。 この記事ではアプリケーション監視プラットフォームのSentryをClassiの中でどのように活用しているかを少し紹介します。Sentryの運用に悩んでいる方の参考になれば幸いです。
Sentryの用途
Classiでは大きく2つの目的でSentryを利用しています。ひとつはアプリケーションのエラーの監視(以後エラー監視と呼びます)、もうひとつはWebフロントエンドのパフォーマンスの監視(以後パフォーマンス監視と呼びます)です。
Sentryは多くのプログラミング言語用にSDKがあり、Classiでは主にJavaScriptとRubyのSDKを利用してフロントエンド・バックエンド両方のエラー監視を行っています。パフォーマンス監視は最近利用しはじめたのですが、バックエンドではもともとDatadogによる監視をしていたので、Sentryのパフォーマンス監視はフロントエンドだけで利用しています。
エラー監視の運用
Classiはプロダクトを開発運用するためのいくつかのクロスファンクショナルチームが構成されており、その各チームでエラー監視を運用することを推進しています。
エラー監視はやるべきとわかっていても運用を継続するのが難しいものです。その大きな原因は導入初期のエラーのノイズ、いわゆるS/N比の低さです。エラー監視のためにずっとSentryの画面を見つめているわけにはいきません。エラーの発生を検知して迅速に対応するにはアラートの整備が欠かせませんが、導入初期はアラートが多すぎて通知されるのが日常化してしまいがちです。そのため、アラートの整備と同時にS/N比を向上していく取り組みも同時進行することが重要でした。
Classiでエラー監視の運用を定着させるために最初にやったのは運用ガイドの作成です。運用ガイドには次のことを書いています。
Slackでのアラート監視
Sentryのアラートの通知先としてSlackを使うことと、その通知を見逃さないようにするためのポイントを書いています。
- 自分のチーム専用のアラートチャンネルへ通知すること
- チャンネルの通知設定を「すべての新しいメッセージ」にしておくこと
- 通知が来たら必ず何らかの対応(以後トリアージと呼ぶ)をすること
トリアージ
エラー監視のS/N比を改善していくために重要なのがトリアージの作業です。トリアージでは、その内容がどうであれ同じイシューが一定期間アラートされないようにします。具体的なトリアージの内訳は次の3つです。
- 判断を先送りする
- 対応しないことを決める
- すぐ対応する
判断を先送りする場合、チームで決めた一定期間(1-2週間ほど)そのイシューを無視します。Sentryには条件付き無視の機能があり、一定条件の間はアラートの対象外にできます。すぐには対応できませんが、アラートは止めつつそのエラーの存在をあとで思い出すことができます。
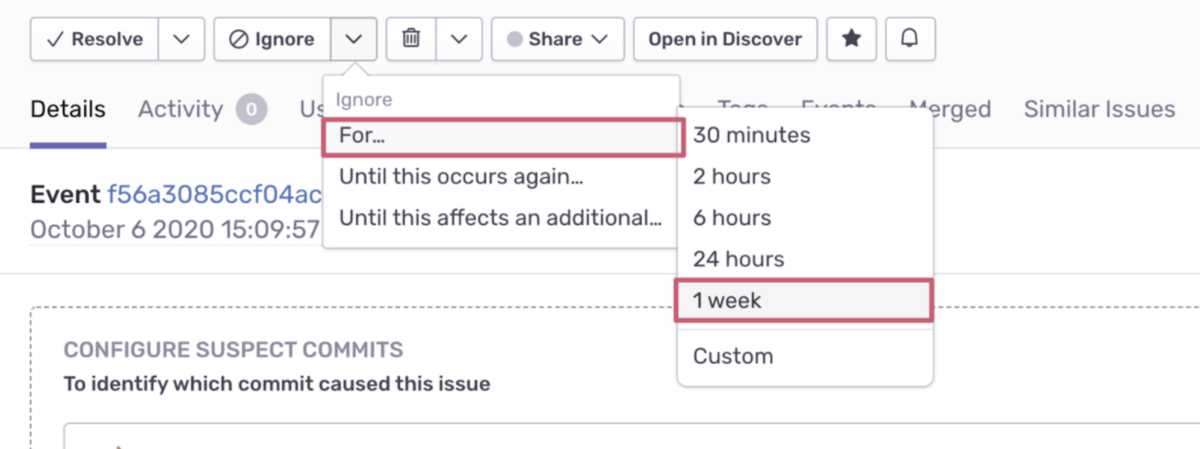
エラーの解決が見込めない、外的要因によるものであるなど、チームとして当面の間対応しないことを決めた場合は、通常の無視を選びます。直ちに対応することになった場合は、対応完了するまで(たとえば次スプリントまで)はアラートが出ないように条件付き無視を使うとノイズが減ります。
エラー収集の最適化
また、そもそもSentryに送信されるエラー自体を最適化していくためのガイドも作成しています。SDKの初期化設定によって対応しようがないエラーの収集を防ぐことができるため、S/N比を改善しながらSentryの課金クォータを節約することもできます。 この最適化については公式ドキュメントの Manage Your Event Stream, a Guide | Sentry Documentation をベースにして社内向けにチューニングしました。
チーム横断的なトレンドの追跡
各チームがエラー監視を運用していくことを推進する一方で、Classi全体でのエラーのトレンドも追跡しています。具体的には、毎週Sentryから送られてくるWeekly Reportの共有と、毎月の社内向けレポートの作成をしています。
毎週のWeekly Reportでは一週間でどのプロジェクトのエラーが多かったかがわかります。7日間の推移を見ながら、その推移が身に覚えがあるものかどうかを振り返り、もし把握していないエラーの増加があればチームに持ち帰って深堀りしてもらうようにしています。
毎月の社内向けレポートでは、SentryのDiscover機能を使って全プロジェクトの中での上位エラーを報告しています。Discoverはビジネスプラン以上になるとプロジェクトを跨いだ検索ができるようになってかなりパワーアップします。まるで別物のような使い心地です。
エラーへの対応でどのチームがうまく行っていて、どのチームが難航しているのかを俯瞰できることでフロントエンドエキスパートチームとしても支援の優先順位付けがしやすくなりました。
パフォーマンス監視
Sentryのフロントエンドパフォーマンス監視機能は Web Vitals の指標にも対応して非常に使いやすくなりました。
パフォーマンス監視は計測自体はできるようになったものの、これをどう活用するかについてはまだ道半ばであり、どのような運用が各チームの活動をサポートするものになるかを考えている最中です。たとえばリリースの前後でパフォーマンスの劣化がないかを確認することや、極端なパフォーマンス劣化をアラートすることなどをフロントエンド運用のガイドラインとしてまとめていきたいと考えています。
まとめ
エラー監視の観点を中心に、ClassiでSentryをどのように運用しているかを紹介しました。運用は持続的に機能し続けることが求められますから、手間のかからず、なおかつ効果の高い運用方法を今後も模索していくつもりです。 もしSentryの運用に力を入れているチームがあればぜひもっと詳しい話をしながら意見交換してみたいので lacolaco 宛にDMなどいただけると嬉しいです。 それではまた!