こんにちは。開発本部の遠藤です。
ClassiではAmazon ECSをアプリケーション実行環境として利用しています。
ECSの各種メトリクスをDatadogを使ってモニタリングしながら、日々安定稼働しているかどうかをチェックしています。
そのうちの一つの重要なメトリクスとして、ECSのFargate TaskのCPU利用率が過度に高まっていないか、があるのですが、ある時期、CPU利用率が100%を超えてしまっていて「一体なにが起きてるんだ??」と疑問を持ちました。
今回はそれについて深堀りしてみたので、ニッチなトピックですが紹介したいと思います。
ECS Fargate TaskのCPU利用率が100%を超えて表示されている
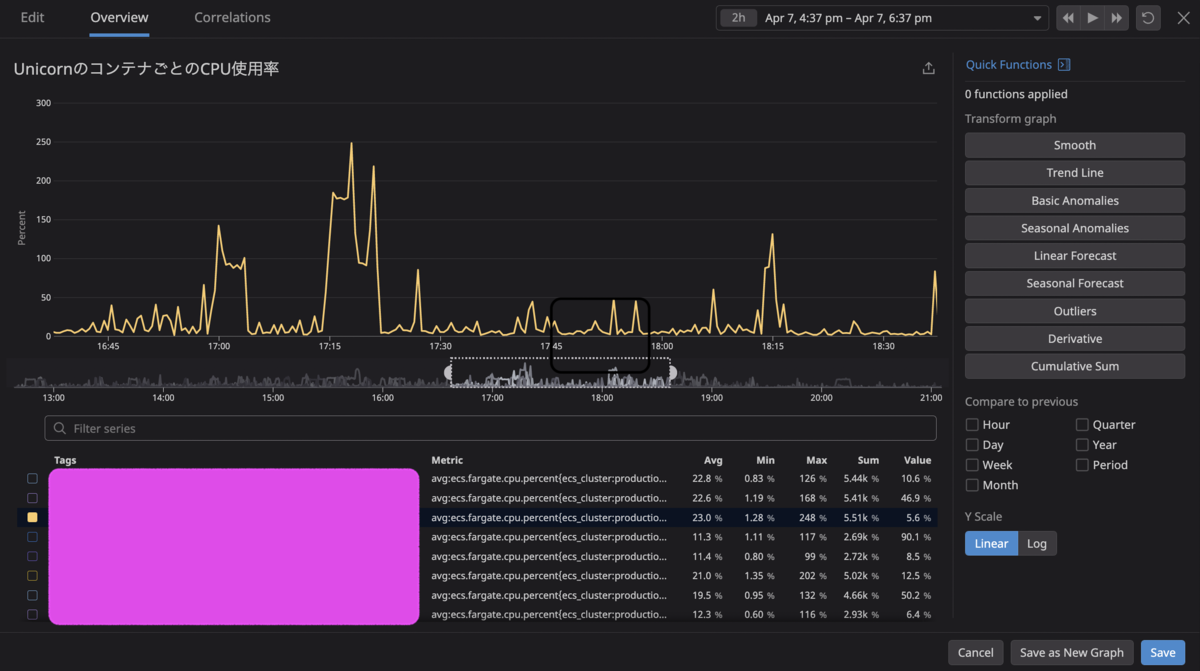
こちらが実際にCPU利用率が100%を超えてしまったときのグラフです。
Datadogのメトリクスは ecs.fargate.cpu.percent です。なお、container_id でコンテナごとにグルーピングして表示しています。
下記図で示すように、AWSの CloudWatch Logs Insights を使用して、上記コンテナが稼働しているECS Fargate Taskの CpuReserved と CpuUtilized をもとにCPU利用率を計算してみると、およそ50%ということがわかります。
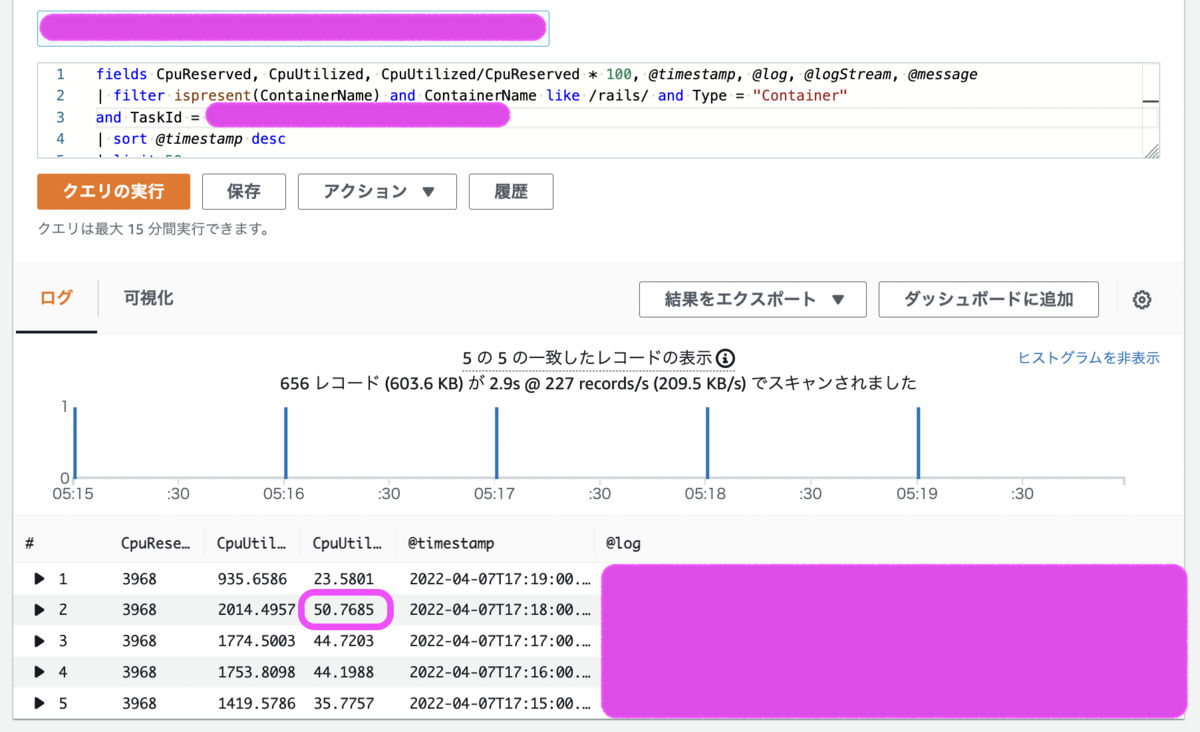
この違いはどこから来ているのか、あるいはDatadogにCPU利用率が100%を超えうるというバグが存在しているのか、Datadogのメトリクスの算出方法を追って探ってみたいと思います。
DatadogはCPU利用率をどう算出しているのか
Datadogで表示されているこの ecs.fargate.cpu.percent というメトリクスはどのような計算式で算出されているのでしょうか?
Datadogのドキュメント には Percentage of CPU used per container (Linux only) Shown as percent と記載されているのみでした。
ということでソースコードを読んで確認していきます。(以後参照するソースコードについては2022/05/23時点の最新の master/main ブランチのものとなります)
cpu_percent = (cpu_delta / system_delta) * active_cpus * 100.0 cpu_percent = round_value(cpu_percent, 2) self.gauge('ecs.fargate.cpu.percent', cpu_percent, tags)
このあたりで算出しているようです。
cpu_delta、 system_delta について見ていきます。
request = self.http.get(stats_endpoint)
stats = request.json()
for container_id, container_stats in iteritems(stats): if container_id not in exlcuded_cid: self.submit_perf_metrics(container_tags, container_id, container_stats)
submit_perf_metrics の中では以下のような処理を行っています。
# CPU metrics cpu_stats = container_stats.get('cpu_stats', {}) prev_cpu_stats = container_stats.get('precpu_stats', {}) value_system = cpu_stats.get('cpu_usage', {}).get('usage_in_kernelmode') if value_system is not None: self.rate('ecs.fargate.cpu.system', value_system, tags) value_user = cpu_stats.get('cpu_usage', {}).get('usage_in_usermode') if value_user is not None: self.rate('ecs.fargate.cpu.user', value_user, tags) value_total = cpu_stats.get('cpu_usage', {}).get('total_usage') if value_total is not None: self.rate('ecs.fargate.cpu.usage', value_total, tags) available_cpu = cpu_stats.get('system_cpu_usage') preavailable_cpu = prev_cpu_stats.get('system_cpu_usage') prevalue_total = prev_cpu_stats.get('cpu_usage', {}).get('total_usage') # This is always false on Windows because the available cpu is not exposed if ( available_cpu is not None and preavailable_cpu is not None and value_total is not None and prevalue_total is not None ): cpu_delta = float(value_total) - float(prevalue_total) system_delta = float(available_cpu) - float(preavailable_cpu) else: cpu_delta = 0.0 system_delta = 0.0
request.json で取得したレスポンスデータを使って計算していて
cpu_stats.system_cpu_usage と precpu_stats.system_cpu_usage の差分が system_delta であり、
cpu_stats.total_usage と precpu_stats.total_usage の差分が cpu_delta です。
では request.json はどのendpointにリクエストを投げて取得したデータなのでしょうか?
request = self.http.get(stats_endpoint)
stats_endpoint = API_ENDPOINT + STATS_ROUTE
API_ENDPOINT = 'http://169.254.170.2/v2' METADATA_ROUTE = '/metadata' STATS_ROUTE = '/stats'
http://169.254.170.2/v2/stats
これがendpointのようです。
タスクメタデータエンドポイントバージョン 2
169.254.170.2 v2 でググってみるとAWSのデベロッパーガイドがすぐに出てきました。
タスクメタデータエンドポイントバージョン 2 - Amazon Elastic Container Service
Amazon ECS コンテナエージェントのバージョン 1.17.0 から、さまざまなタスクメタデータおよび [Docker 統計]を、Amazon ECS コンテナエージェントによって指定される HTTP エンドポイントで awsvpc ネットワークモードを使用するタスクで利用できます。
169.254.170.2/v2/stats
このエンドポイントはタスクに関連付けられたすべてのコンテナの Docker 統計 JSON を返します。返される各統計の詳細については、Docker API ドキュメントの「ContainerStats」を参照してください。
つまりDatadogはこのAWSのタスクメタデータエンドポイントを叩いてデータを取得していて、返ってきているのはDocker 統計 JSONということです。
Docker Containers Stats
Docker API ドキュメントの ”ContainerStats” の箇所を見てみます。
Docker Engine API v1.41 Reference
詳細なレスポンスはドキュメントに記載されているので、ここでは気になるものをピックアップします。
先に出てきた cpu_stats です。
"cpu_stats": { "cpu_usage": { "percpu_usage": [ 8646879, 24472255, 36438778, 30657443 ], "usage_in_usermode": 50000000, "total_usage": 100215355, "usage_in_kernelmode": 30000000 }, "system_cpu_usage": 739306590000000, "online_cpus": 4, "throttling_data": { "periods": 0, "throttled_periods": 0, "throttled_time": 0 } },
疑問
DatadogはこのAWSのタスクメタデータエンドポイントを叩いてデータを取得していることがわかりました。 ではもともとの疑問であった100%を超えるCPU利用率の表示というのはDatadogのバグではないということになるのでしょうか?
もう一度Datadogの計算式を見てみます。
cpu_percent = (cpu_delta / system_delta) * active_cpus * 100.0
これをタスクメタデータエンドポイントのレスポンスのkeyを使用して表現すると以下のようになります。
((cpu_stats.total_usage - precpu_stats.total_usage)
/ (cpu_stats.system_cpu_usage - precpu_stats.system_cpu_usage))
* cpu_stats.online_cpus
* 100.0
response sample の percpu_usage のarrayのvalueの合計が total_usage のvalueと一致することから total_usage はその名の通りコンテナ全体のCPU消費時間を指しているはずです。
そうであるなら、 稼働しているCPUコア数を指す cpu_stats.online_cpus を乗算する必要性がどうしても見いだせず、以下の計算式で十分に思えました。
cpu_percent = (cpu_delta / system_delta) * 100.0
なぜ cpu_stats.online_cpus を乗算しているのでしょうか?
そう思ってる人が他にもいた
そもそもDatadogがなぜこの計算式を採用しているのかというと、docker stats のそれに準じているからだと推測されます。
cpuPercent = (cpuDelta / systemDelta) * onlineCPUs * 100.0
そしてこの計算式について異議を唱えるissueがありました。
https://github.com/docker/cli/issues/2134
docker stats CPU shows values above 100%
I don't think there is a system monitor tool (linux or windows) that shows CPU usage above 100%. Conceptually, 100 percent means maximum value.
So what is the reason to multiply by the number of cpus? Seem that is not required because total_usage already accounts for them.
なおこのissueに対して明確な回答はなさそうでしたが、以下のようなコメントがあります。
This is not an issue. If you have N CPU cores, the CPU usage can be up to N * 100%.
これだけだと納得がいかなかったのですが、mobyのissueにそれらしい回答がありました。
https://github.com/moby/moby/issues/29306#issuecomment-405293005
That's not really something that can be changed easily, as it will break many users; this output was modelled after how top works on Linux; https://unix.stackexchange.com/questions/34435/top-output-cpu-usage-100
top コマンドをモデルにしているようです。
top command の Irix mode
言及されているリンクを見てみます。
linux - top output: cpu usage > 100% - Unix & Linux Stack Exchange
You are in a multi-core/multi-CPU environment and top is working in Irix mode. That means that your process (vlc) is performing a computation that keeps 1.2 CPUs/cores busy. That could mean 100%+20%, 60%+60%, etc.
Irix mode を知らなかったので調べてみます。
https://man7.org/linux/man-pages/man1/top.1.html
I :Irix/Solaris-Mode toggle When operating in Solaris mode ('I' toggled Off), a task's cpu usage will be divided by the total number of CPUs. After issuing this command, you'll be told the new state of this toggle.
Irix mode と Solaris mode があり、Solaris modeはcpu usageをCPUコア数で割った数が表示されるようです。 つまりdefaultのIrix mode はcpu usageをCPUコア数で割らないということを意味することがわかります。
これが docker stats のCPU使用率算出の計算式のモデルになっているようです。
まとめ
Irix mode ではcpu usageをCPUコア数で割らない値をCPU使用率として表示しています。 たとえばCPUコア数が4のサーバであれば、最大400%として表示され得るということです。
docker stats も Datadog の ecs.fargate.cpu.percent のメトリクスもこの表示方式を踏襲し、以下の計算式を採用していることがわかりました。
cpu_percent = (cpu_delta / system_delta) * active_cpus * 100.0
つまりわざわざCPUコア数を乗算することで、top コマンドの Irix mode でのCPU利用率の値を表現していたのです。
冒頭の疑問にやっとここで返ってこれるのですが、該当のECS Fargate Task はcpuを4096 = 4vCPU(CPUコア数:4) で設定し稼働させているので、100%を超える値が表示されていたということです。
なのでこのコンテナは実質的には4で割った値である 50 ~ 60% あたりで稼働していると考えてよさそうですし、CloudWatchで取得した値と近しくて納得感があります。
ただし、どのCPUコアがそれぞれ何%なのかまではわからず、いずれかが100%近くまでCPUを利用している可能性は大いにあり得るので、注意は必要です。
Datadogの ecs.fargate.cpu.percent で検索してもなかなか今回の事象について情報が得られなかったのですが、コードリーディングすることで納得感が得られ、とてもスッキリしました。
加えて、Datadogが実際なにをしているかを垣間見れたことでDatadogへの理解が深まり、芋づる式にECS、Docker、topコマンドについても知見を得られたので学びが多かったです。
同じような事象に遭遇し、疑問を持った方の参考になれば幸いです。