こんにちは、エンジニアの鳥山です。
Classiでは、2024年の12月ごろから当時最新であったGemini 1.5 Proを用いた議事録生成ツール「Turing」を開発、リリースし、社内のメンバーに使ってもらっています。
本記事では、
- リリースからおよそ半年経った今、Turingはどの程度普及したのか
- 利便性や運用性の向上のためにどんな継続的改善をしたのか
の大きく2点に焦点を当てて紹介し、最後にTuringの成功要因についても考察します。
モデルのアップデートや新技術の発表が毎週のように起きる昨今、個人的にはAIをプロダクトに取り入れることのみならず、社内ツールとして使うことにも大きな可能性を感じています。
本記事は単体でもお読み頂けますが、Turingのアーキテクチャなどより詳細な部分にご興味をお持ちの方は、ぜひ前述のブログ記事も併せてお楽しみください。
Turingはどの程度普及したのか
Turingは社内のGoogle Workspaceユーザー(以下、botユーザー)と連携しているため、「このユーザーがどれくらい会議に呼ばれたか」を見るとおおよそどれくらい議事録の自動生成が使われているか分かります。
直近のbotユーザーのカレンダーは、おおよそ以下のような状態でした。
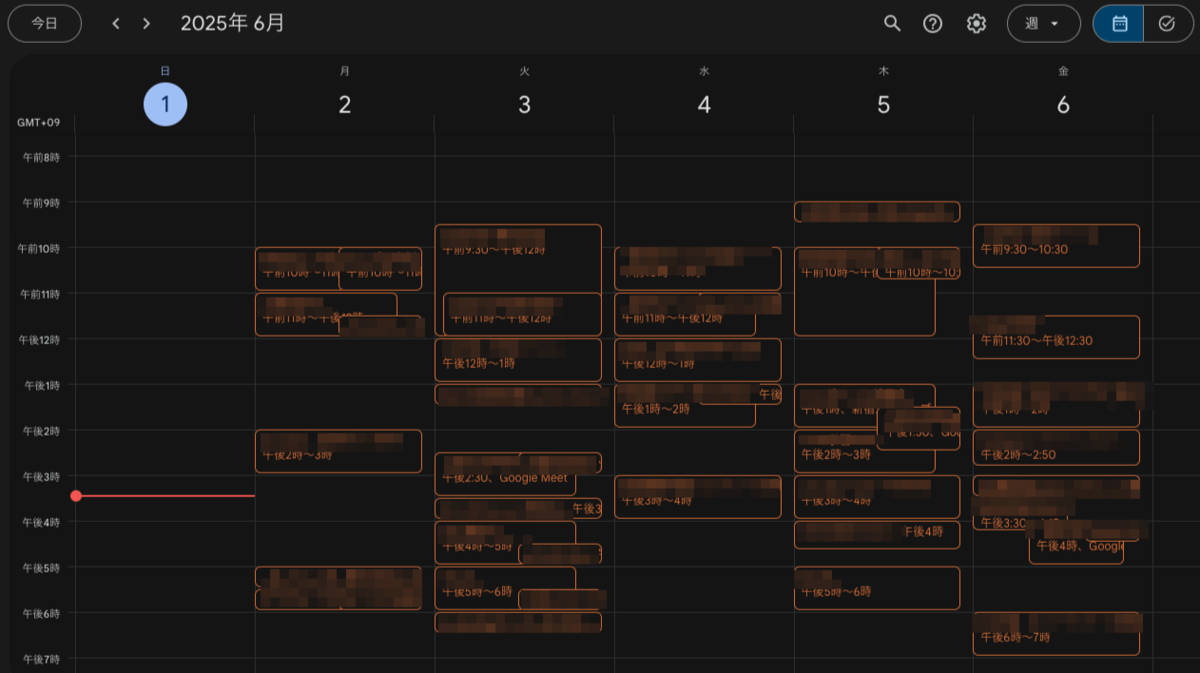
私も改めて見て驚いたのですが、なんと週に40近い会議でTuringが利用されています。利用者層もエンジニア陣だけにとどまらず、セールス、プロダクト、更には経営陣が行う事業推進会議など幅広いユーザー層や様々な場面において利用されています。数だけで見れば、完全に社内の「当たり前」のツールとしてポジションを確立したと言えるでしょう。
また、本記事の執筆に当たって利用者にアンケートも取ってみたところ、NPS1の項では以下のような回答が得られました。
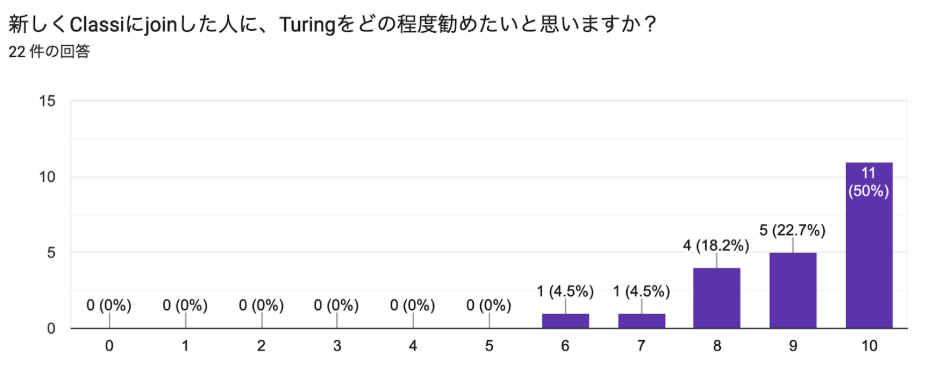
NPSを計算すると、71.4という並外れた数値を叩き出しました2。社内のメンバーに聞いているため甘い数値になっているのは否めませんが、Google Meetデフォルトでの文字起こしが日本語対応する3など、代替サービスが台頭しているにもかかわらずこれだけの評価を得たことは、社内にも一定のインパクトを与えられたと言ってよいのではないでしょうか。アンケートの自由回答では、
非常に助かっておりこのままお金を取れるレベルと思います
FY24社内No.1の業務改善施策ではないかと
という嬉しいコメントも頂きました。
利便性や運用性の向上のための工夫
初期リリースから実施したアップデートをいくつか紹介します。
Slack任意チャンネルへの投稿
リリース当初、Turingの利用は専用のSlackチャンネルでのやり取りに限っていたのですが、ある日「生成議事録の投稿チャンネルを選べると嬉しい」という要望を弊社役員から頂きました。
この要望をメンバーがすぐにキャッチしてくれ、次のスプリントでさっそく新機能としてリリースすることができました。
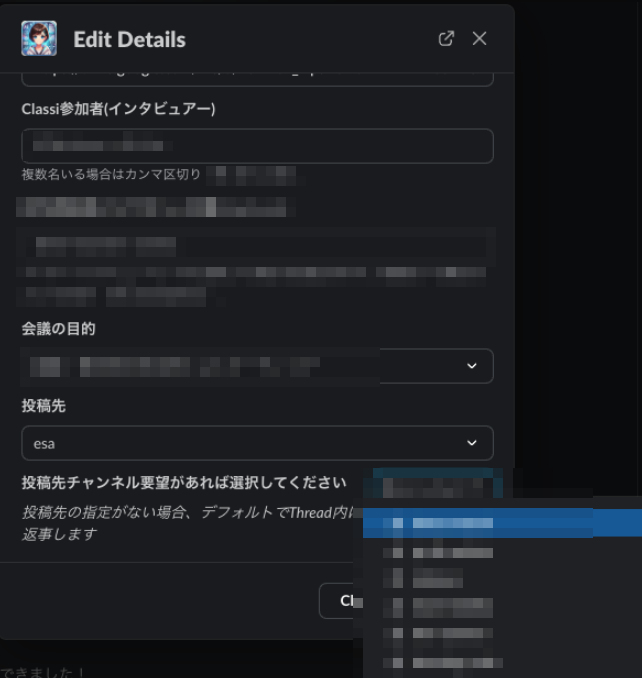
余談ですが、役員レベルでもカジュアルにSlack上で要望を出し、エンジニアメンバーがそれをシュッと拾って実装する、こういったフラットさとスピーディさはClassiで働く上での魅力だと常々思います。
サーバサイドではSlackアプリ開発フレームワークであるBolt4を、そしてモーダルに表示するコンポーネントとしてはBlock Kit中の conversations_select を使用しています。
Select menu element | Slack Developer Docs
サーバサイドでは、以下のようにSlack画面上の操作に応じたハンドラーを記述し、画面コンポーネントを定義したJSONを返却します。
from jinja2 import Environment, FileSystemLoader from slack_bolt import App # Initialize Slack app app = App( token=os.environ.get("SLACK_BOT_TOKEN"), signing_secret=os.environ.get("SLACK_SIGNING_SECRET"), ) # Modal handler # Interactivity handler for button click @app.action("open_modal") # action_id defined in the button payload def open_modal(ack, body, client): ack() user_name = body["user"]["username"] channel_id = body["channel"]["id"] message_ts = body["container"]["message_ts"] data = json.loads(body["actions"][0]["value"]) values = { "video_link": data.get("video_link", ""), "interviewers": data.get("participants", ""), "ref_links": ",".join(data.get("ref_links", [])), "private_metadata": json.dumps( {"user_name": user_name, "channel_id": channel_id, "message_ts": message_ts} ), } modal_view = load_slack_modal("slack_modal_template.j2", values) try: client.views_open(trigger_id=body["trigger_id"], view=modal_view) except SlackApiError as e: print(f"Error opening modal: {e.response['error']}") def load_slack_modal(template_path, values): file_loader = FileSystemLoader(searchpath="./") env = Environment(loader=file_loader) template = env.get_template(template_path) rendered_template = template.render(values) print(rendered_template) return json.loads(rendered_template)
slack_modal_template.j2 の中で以下のようなセクションを含めて views_open の引数に渡すだけで上述したような体験が実現できます。このようにBlock Kit部分をjinjaテンプレートを用いて管理すると、変数の埋め込み等もしやすく便利です。
{ "type": "section", "block_id": "channel_select_section", "text": { "type": "mrkdwn", "text": "*投稿先チャンネル要望があれば選択してください* \n\n _投稿先の指定がない場合、デフォルトでThread内に返事します_" }, "accessory": { "type": "conversations_select", "placeholder": { "type": "plain_text", "text": "Select a channel" }, "action_id": "channel_select_action", "filter": { "include": ["public", "private"] } } }
インスタンス起動時刻の最適化
TuringのバックエンドにはCloud Runを利用していますが、Slackとの常時接続が必要な関係上、インスタンスを常時1台起動しておかないといけないという弱点があります。
とはいえ、休日や夜間にまで動かし続けておく必要はありません。この点については、小さなCloud Run Functionを実装して適当な時間に落とし、費用を最適化するような仕組みを実装しました。
import os from google.cloud import run_v2 def handler(request): # get request data req_json = request.get_json() project_id = os.getenv("GOOGLE_CLOUD_PROJECT") service_name = req_json["service_name"] location = req_json["location"] if "location" in req_json else "asia-northeast1" min_instance_count = req_json["min_instance_count"] # create a client client = run_v2.ServicesClient() get_service_request = run_v2.GetServiceRequest( name=f"projects/{project_id}/locations/{location}/services/{service_name}" ) service = client.get_service(request=get_service_request) service.scaling.min_instance_count = min_instance_count update_service_request = run_v2.UpdateServiceRequest( service=service, update_mask={"paths": ["scaling.min_instance_count"]} ) operation = client.update_service(request=update_service_request) result = operation.result() return "success"
あとは、同じCloud Run関数に所定の時間で望むインスタンス台数を送信するCloud Scheduler Jobを作ればよいです。Terraformの実装例は以下です。
resource "google_cloud_scheduler_job" "scale_in" { description = "Turing scale in job" name = "turing-scaler-scale-in" project = local.project region = "asia-northeast1" schedule = "0 23 * * 5" # FRI 23:00 JST time_zone = "Asia/Tokyo" http_target { uri = google_cloudfunctions2_function.turing_scaler.service_config[0].uri http_method = "POST" body = base64encode(jsonencode({ "service_name": "slack_app", "min_instance_count" : 0 })) headers = { "Content-Type" = "application/json" } # ...(中略) } resource "google_cloud_scheduler_job" "scale_out" { description = "Turing scale out job" name = "turing-scaler-scale-out" project = local.project region = "asia-northeast1" schedule = "0 6 * * 1" # MON 6:00 JST time_zone = "Asia/Tokyo" http_target { uri = google_cloudfunctions2_function.turing_scaler.service_config[0].uri http_method = "POST" body = base64encode(jsonencode({ "service_name": "slack_app", "min_instance_count" : 1 })) headers = { "Content-Type" = "application/json" } # ...(中略) }
こうした工夫もあって、Turingは社内の利用増にも関わらず概ね数万円/月の範囲で運用ができています。企業向けの議事録生成サービスはいくつかありますが、それらと比較してもほぼ同程度以下の費用かと考えています。
また、細かいですが社員向けのドキュメントをリリース初期から整備したり、利用上の諸注意についてまとめたSlackリマインダーを設定したりもしました。ここ最近は、こうした努力も手伝ってエンジニアへの問い合わせもグッと少なくなり、他のタスクに集中できている実感があります。
成功の要因、そして今後の展望
先述の通りGoogle Meetに文字起こし機能がリリースされたにも関わらず、なぜTuringが使われ続けているのか?というのは個人的にも大きな疑問でした。ここについてアンケートで聞いてみたところ、
- Google Meetの文字起こしと併用したことのあるユーザは回答者の3割程度である
- 併用したユーザも、要約の精度はTuringの方が高いと受け止めている
ということが分かりました。
私自身もTuringのヘビーユーザーなのですが、たしかにTuringは会議の決定事項とネクストアクションをまとめることに長けている印象があります。これは、以下のような章立てで議事録を出力するようプロンプトで指示してあることが大きいと考えています(プロンプト全体については公開できないため、あくまで抜粋です)。
## 背景と目的
## 主要な議論のトピック
- [議題1]
- [議題2]
## 各議題の結論とそれに至った理由・経緯
- [議題1]
- 結論: [結論]
- 理由・経緯: [結論に至った理由および経緯]
- [議題2]
- 結論: [結論]
- 理由・経緯: [結論に至った理由および経緯]
## 決定事項
- [決定事項1]
- [決定事項2]
## 未決定事項
- [未決定事項1]
- [未決定事項2]
## 次のステップやアクションアイテム
- [アクション1]
- [アクション2]
これに対し、Meetの文字起こしはあくまで「誰がいつどのような意見を表明したか」にフォーカスしている印象があります。これは両ツールの目的の違いであり、単に精度の良し悪しで測れるものでもなさそうです。例えば、明確な意思決定を目的としない読書会や1on1のような場面では、私自身もむしろMeetの文字起こしを使いたいと考えるようになっています。
Turingは、もともとユーザーヒアリングに特化させることを目的に開発が開始されました。実際には意思決定を目的とする会議でより広く普及しており計算外の部分もありますが、「特定ユースケースに特化したプロンプトを考えることで汎用的なツールを越える価値が生み出せた」というのは今後にも繋がる良い成功体験だったのでは、と思います。
また、Slackや、社内で扱う各種情報共有サービスとの連携ができるところもTuringが高く評価されている要因でした。こうした、「AIと他のサービスをエンジニアリングでつなげる」ことも今後間違いなくエンジニアがやるべき重要な仕事の一つになるでしょう5。
ある日Meetの文字起こし機能が大幅にアップデートされて爆発的に普及し、Turingはお役御免になる。そんな未来も遠からず来るかもしれません。ですが、私はそれでも全く問題ないと考えています。むしろ、生成AI関連技術がどんどん更新を続けるこの時期に今回の案件に挑戦することで、
- 社内に生成AIイケてるよね!という機運を作れた
- チーム内にGeminiを扱う上での知見を蓄積できた
といった成果が得られたことが大きかったと思います。ここで得られた技術力と社内からの信頼を活かし、今後もGeminiをはじめとした生成AIとより良く付き合っていきたいと思う今日このごろです。
皆さまのチームでも、この事例が生成AIを用いた業務改善などのヒントになれば幸いです。最後までお読み頂きありがとうございました。
- https://www.nttcoms.com/service/nps/summary/↩
- 図中に表現できていませんが、有効回答が21件で、推奨者16名、批判者1名のため(16-1)/21と計算されます。日本では諸外国と比べてNPSが低く出やすく、マイナスの値になることが珍しくありません↩
- https://support.google.com/meet/answer/12849897?hl=ja↩
- https://tools.slack.dev/bolt-python/ja-jp/getting-started/↩
- n8nのようなツールや、Vibe Codingのような手法も出てきているため、どこまで「エンジニア自身のコードで」やるべきかについては議論の余地がありますが...↩