こんにちは、データAI部でPythonエンジニアをしている平田(@JesseTetsuya)です。普段は、PoCとデータをもってくる、というところ以外全部やる、というスタンスで開発業務を行っています。
日頃は、Flask1.1.4を利用していましたが、2021年5月11日にFlask2.0へのメジャーバージョンアップがありました。
メジャーバージョンアップということもあり、多くのアップデート項目がありました。そこで、特に日頃の業務に関わりそうなアップデートについて当記事にまとめていこうと思います。
Flaskとは?
Flaskは、PythonistaのArmin Ronachertによって2010年に初回リリースされました。いまでは、 Armin Ronacherを筆頭にPalletプロジェクトと言う名前でFlaskを含む、Flaskに関連する各ライブラリのメンテナンスがPalletプロジェクトメンバーによって行われています。
Flaskは、WSGI準拠のPythonマイクロWebフレームワークです。Djangoのようなフルスタックフレームワークとは違い、決まったディレクトリ構成もなければデフォルトでのデータベース機能やアドミン画面もありません。
GitHubのスター数も多く、JetBrain社の「Python Developers Survey 2020 Results」調査結果で人気ナンバーワンになっているそうです。
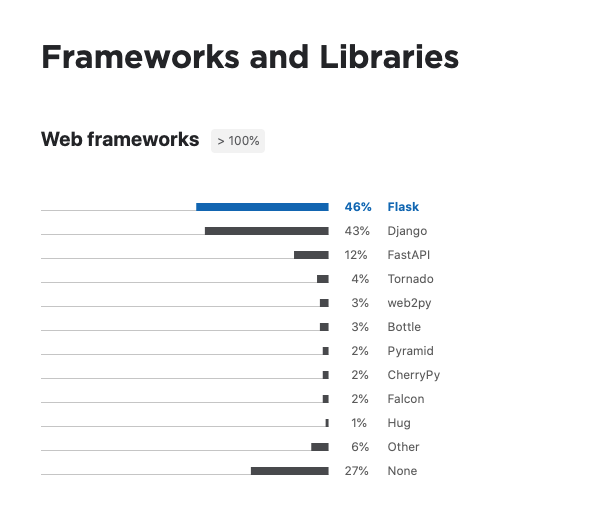
軽量のフレームワークであるため、手軽にWEB アプリケーション開発でもAPI開発でも利用しやすくなっています。WEBアプリケーション開発未経験者やPython初学者にとってとっつきやすいフレームワークだと思います。
データサイエンスの界隈では機械学習モデルを構築し、その結果を返すREST APIをFlaskで実装するというユースケースがよく聞かれます。
データサイエンスを担う人が手軽にREST APIを作るニーズが高まりをみせ、最近では、Fast APIというASGI準拠の非同期処理を得意とするStarletteをラッピングしたフレームワークの人気も台頭してきました。
Fast APIにあってFlaskにまだ実装されていない機能を実装したのが今回のFlask 2.0へのversion upに垣間みることができます。
では、Flask 2.0の各アップデート項目をみていきます。
Flask 2.0.xのアップデート項目
ざっと、日頃の私の業務で目にとまった項目をピックアップしました。その他のアップデートはこちらのリンクでご確認ください。
- Werkzeug 2.0, Jinja 3.0, Click 8.0, ItsDangerous 2.0 MarkupSafe 2.0へのアップデート
- Python 3.5以下のversionがサポート対象外に
- Blueprintのネスト記法対応
- Routingがよりシンプルにかけるように
- Configファイルの読み込み方法の変更
- タイプヒント対応
- 非同期実装が対応
- Werkzeug 2.0のmultipart/form-data の改善により、大きいファイルのアップロードが15倍速に
Flask 2.0.1とFlask 1.1.4の書き方の比較確認
まずは、Flask 2.0.1とFlask 1.1.4でのRouting、Blueprint、config.from_json()、async defの書き方について比較しながら確認してきましょう。
全て一つのapp.pyモジュールとして実行できるようになっています。
初めてFlaskにふれる方は、下記のコマンドを実行し、各スクリプトをapp.pyにコピペして挙動を確認してみてください。
$ touch app.py
$ pip install Flask
$ pip install "Flask[async]"
$ export Flask_APP=app.py
$ flask run
Routingの確認
from flask import Flask, Blueprint
app = Flask(__name__)
app.config["JSON_AS_ASCII"] = False
api = Blueprint("api", __name__, url_prefix="/flask")
@api.get("/v2")
@api.post("/v2")
def flask2():
return "こちらは、Flask 2.0.1です。"
@api.route("/v1", methods=["GET", "POST"])
def flask1():
return "こちらは、Flask 1.1.4です。"
app.register_blueprint(api)
わざわざ、httpメソッドを引数内に指定する必要がなくなりました。このRoutingの書き方は、Fast APIと同様です。
Nested Blueprintの確認
from flask import Flask, Blueprint
app = Flask(__name__)
parent_api = Blueprint("api", __name__, url_prefix="/parent")
child_api = Blueprint("api", __name__, url_prefix="/child")
@parent_api.get("/")
def parent_flask2():
return "Hello Parent Flask 2.0.x"
@child_api.get("/")
def child_flask2():
return "Hello Child Flask 2.0.x"
parent_api.register_blueprint(child_api)
app.register_blueprint(parent_api)
このアプリケーションを起動してhttp://127.0.0.1:5000/parent/とhttp://127.0.0.1:5000/parent/child/にアクセスしてそれぞれ確認してみてください。
Blueprintは、もともと大きいアプリケーションを開発する際にファイル分割、ディレクトリ分割をして各モジュール間の疎結合状態をたもつための機能でした。
Blueprintのネスト化の対応により、各モジュールを各役割・責務ごとに束ねてルーティングをする際、更にもう1階層上のレイヤーでの各役割・責務ごとに各モジュールを実装し、ルーティングの紐付けがしやすくなりました。
from flask import Flask, Blueprint
app = Flask(__name__)
parent_api = Blueprint("api", __name__, url_prefix="/parent")
@parent_api.route("/", methods=["GET", "POST"])
def parent_flask1():
return "Hello Parent Flask 1.x"
@parent_api.route("/child/", methods=["GET", "POST"])
def child_flask1():
return "Hello Child Flask 1.x"
app.register_blueprint(parent_api)
flask 1.1.4で同じコードを書いてみると、違いが明らかにわかりますね。
一方で、ただでさえ、Flaskの場合はディレクトリ構成に悩むことが多く、これでさらに考えうるディレクトリ構成のパターンが増え悩むことが増えてきますね。
config.from_json()の確認
...
...
app.config.from_file("config.json", load=json.load)
app.config.from_file("config.toml", load=toml.load)
app.config.from_json("config.json")
...
...
たまに書くことがあり、自分で間違えそうということでメモ感覚で追記しておきます。
ふーん、こうなったんだ、という感じで大丈夫かと思います。
非同期処理の確認
最後に非同期処理の確認です。Python自体は、Python3.5以降からネイティブなコルーチンが実装されており、非同期処理の実装が可能でした。
しかし、Flask 1.xでは、フレームワークとしては対応しておらず、ルーティングにコルーチン関数を書いて実行しても対応していないためエラーがでておわるだけでした。
Flaskが非同期処理に対応していないため、FastAPIを選択した方も多いのではないでしょうか。
それが、今回のFlask2.0へのversion upで対応されました。
色んな書き方があるかとおもいますが、一番わかりやすい書き方でみていきます。
from flask import Flask, Blueprint
import time
import asyncio
app = Flask(__name__)
async_api = Blueprint("async_api", __name__)
async def async_get_data(name, sec):
print(f"{name}: started")
await asyncio.sleep(sec)
print(f"{name}: finished")
return f"{name}:{sec}sec"
@async_api.get("/")
async def flask_async():
start = time.time()
results = await asyncio.gather(
async_get_data("TaskA", 1),
async_get_data("TaskB", 3),
async_get_data("TaskC", 2),
async_get_data("TaskD", 1),
async_get_data("TaskE", 2),
)
print(results)
print(f"process time: {time.time() - start}")
return "All async tasks are finised !!"
app.register_blueprint(async_api)
出力結果
$ flask run
* Serving Flask app 'app.py' (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
TaskA: started
TaskB: started
TaskC: started
TaskD: started
TaskE: started
TaskA: finished
TaskD: finished
TaskC: finished
TaskE: finished
TaskB: finished
['TaskA:1sec', 'TaskB:3sec', 'TaskC:2sec', 'TaskD:1sec', 'TaskE:2sec']
process time: 3.00414776802063
Task A ~ Eまで順番に非同期で実行され、並列処理されているため、Task A、Task D、TaskC、Task E、Task Bの順番で処理が終わっています。
本来、同期処理で一つ一つ処理が終わるまで待って処理していると、全てのタスクが終了するのに9秒かかります。しかし、上記の非同期実装により、マックスでかかる3秒以内で全てのタスクが終了しています。これで非同期処理の挙動確認ができました。
次は、version間でパフォーマンスの違いがあるかどうかを念の為確認しておきます。
Flask 2.0.xのパフォーマンス確認
日頃は、Python製の負荷テストツールであるLOCUSTを利用していますが、まだFlask 2.0.xに対応していないため、Golang製の負荷テストツールVegetaを利用して軽く負荷をかけてどんなものか比較してみます。
先に結論を言うと、大きな差分はありませんでした。 とりわけ、フレームワーク全体のパフォーマンス改善のアップデート項目が明記されていたわけではなかったので悪くなっていなくてよかったという感じです。
Vegetaの使い方をみながら出力結果をみていきます。
Vegetaは、CLIコマンドで軽く負荷試験を実施するのに便利なのでどんなものか軽く知っておくだけでもいつか役に立つときがくるかもしれません。
では、パフォーマンス確認していきましょう。

画像は権利関係上使えなかったので、筆者が手書きしました。ベジータ様を書いたつもりです。
「カカロットォォォ、いくぞーーーー!おりゃーーーー!」
事前準備
*Macを前提にしています。
vegetaのインストール
$ brew update && brew install vegeta
$ go get -u github.com/tsenart/vegeta
下記では、Flask 2.0.1とFlask 1.1.4を比較するために2つのvenv環境が必要になります。
Flask 2.0.1用のディレクトリを作成し、下記のコマンドを実行してvenv環境を作成してください。
$ python3 -m venv venv
$ python3 venv/bin/activate
$ pip install Flask==2.0.1
Flask 1.1.4用のディレクトリを作成し、下記のコマンドを実行してvenv環境を作成してください。
$ python3 -m venv venv
$ python3 venv/bin/activate
$ pip install Flask==1.1.4
Flask 2.0.1の検証用コード準備
from flask import Flask, Blueprint
import asyncio
app = Flask(__name__)
api = Blueprint("api", __name__)
@api.get("/flask_v2")
def flask2():
return "Hello Flask 2.0"
app.register_blueprint(api)
Flask 1.1.4の検証用コード準備
from flask import Flask, Blueprint
import asyncio
app = Flask(__name__)
api = Blueprint("api", __name__)
@api.route("/flask_v1", methods=["GET"])
def flask1():
return "Hello Flask 1.x"
app.register_blueprint(api)
Flask 2.0.1とFlask 1.1.4 のパフォーマンス計測結果
負荷試験実行コマンド*
$ echo "GET http://127.0.0.1:5000/flask_v2" | vegeta attack -rate=500 -duration=5s | tee result.bin
$ echo "GET http://127.0.0.1:5000/flask_v1" | vegeta attack -rate=500 -duration=5s | tee result.bin
*5秒間500RPSで負荷をかけるコマンド
(rate: Request Per Second (RPS), s: second)
負荷テスト実行結果レポート確認
レポート作成コマンド
$ vegeta report result.bin
Flask 2.0.1の出力結果
Requests [total, rate, throughput] 2500, 500.22, 338.90
Duration [total, attack, wait] 6.81s, 4.998s, 1.812s
Latencies [min, mean, 50, 90, 95, 99, max] 368.671µs, 369.698ms, 296.596ms, 569.892ms, 798.921ms, 2.191s, 4.202s
Bytes In [total, mean] 34620, 13.85
Bytes Out [total, mean] 0, 0.00
Success [ratio] 92.32%
Status Codes [code:count] 0:192 200:2308
Error Set:
Flask 1.1.4の出力結果
Requests [total, rate, throughput] 2500, 500.25, 364.51
Duration [total, attack, wait] 6.581s, 4.997s, 1.584s
Latencies [min, mean, 50, 90, 95, 99, max] 370.878µs, 296.992ms, 276.982ms, 458.868ms, 595.851ms, 1.038s, 4.02s
Bytes In [total, mean] 35985, 14.39
Bytes Out [total, mean] 0, 0.00
Success [ratio] 95.96%
Status Codes [code:count] 0:101 200:2399
Error Set:
各メトリックスのみかたは、下記。
- Requests
- total … 全実行回数
- rate … 秒間の実行回数
- Duration
- total … 負荷をかけるのに要した時間(attack+wait)
- attack … 全リクエストを実行するのに要した時間(total - wait)
- wait … レスポンスを待っている時間
- Latencies … それぞれ、平均、50%、95%、99%パーセンタイル、最大値
- Bytes In/Bytes Out … リクエスト/レスポンスの送受信のバイト数
- Success … リクエストの成功率(なお、200と400がエラーとしてカウントされない)
- Status Codes … ステータスコードのヒストグラム(0は、失敗)
- Error Set … 失敗したリクエストとその内容
「Flask 2.0よ、そんなものか、そんなにかわらんではないかっ、貴様っ!!」とベジータ様が申しております。
負荷テスト実行結果をヒストグラムで確認
さて、次はヒストグラムでみてみます。
ヒストグラムレポート作成コマンド
$ cat result.bin | vegeta report -type='hist[0,100ms,200ms,300ms,400ms,500ms]'
Flask 2.0.1の出力結果
Bucket # % Histogram
[0s, 100ms] 159 6.36% ####
[100ms, 200ms] 397 15.88% ###########
[200ms, 300ms] 728 29.12% #####################
[300ms, 400ms] 505 20.20% ###############
[400ms, 500ms] 336 13.44% ##########
[500ms, +Inf] 375 15.00% ###########
Flask 1.1.4の出力結果
Bucket # % Histogram
[0s, 100ms] 188 7.52% #####
[100ms, 200ms] 478 19.12% ##############
[200ms, 300ms] 976 39.04% #############################
[300ms, 400ms] 440 17.60% #############
[400ms, 500ms] 191 7.64% #####
[500ms, +Inf] 227 9.08% ######
「なにっ?!Flask 1.1.4のほうが若干安定してるようにみえるではないか、貴様っ!!」とベジータ様が申しております。
負荷テスト実行結果を時系列グラフで確認
時系列グラフのhtml生成コマンド
$ cat result.bin | vegeta plot > plot.html
$ open plot.html
Flask 2.0.1の出力結果
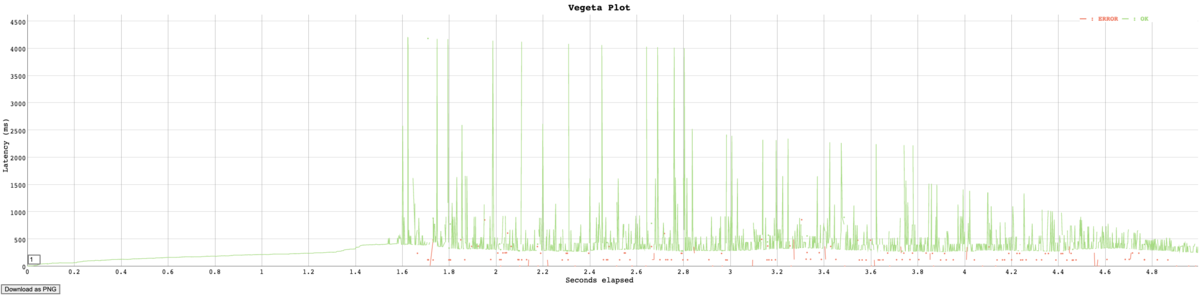
Flask 1.1.4の出力結果
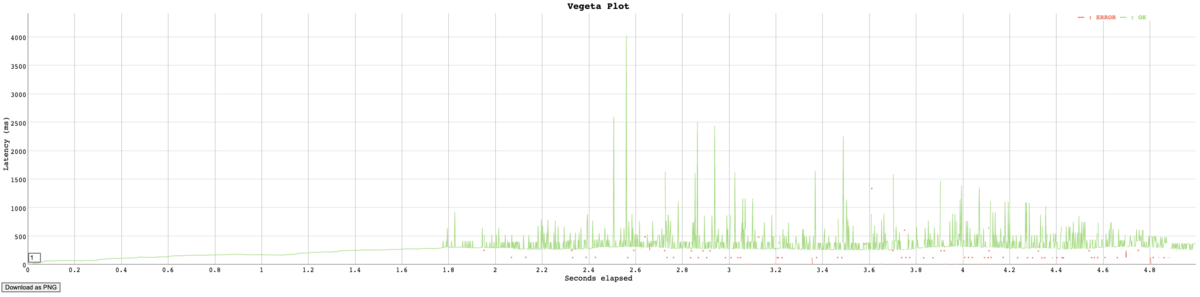
「はやくしろっ!!!! 間にあわなくなってもしらんぞーっ!!!」とベジータ様が申しております。
最後に
このようにベジータ様がおっしゃっていますが、実際のところ大きな差分はありませんでした。
Flask 2.0.xへversion upするか否かは、利用したいライブラリが対応しているか否か、非同期実装したいか否か、Blueprintをネストしたいか否か、で決めればいいと思いました。
しかし、まだ確認できていない箇所や気になる項目もあり、全ての項目について当ブログ記事にて書ききることができませんでした。
というわけで、私のFuture Workとして箇条書きにて下記に残しておきます。
- Fast APIとの書き方の比較をみる
- 非同期処理のパフォーマンスをFast APIと比較してみる
- multipart/form-dataの15倍速が本当にそうなったかをみる
- Vegetaで分散アタックする
- 今年度、どこかの国のPythonカンファレンスで上記の検証結果まとめを発表します
- Flask全般の使い方については、チュートリアルを今年度、どこかの媒体でまとめて発表します
データAI部では、PoCとデータをもってくる、というところ以外全部やるPythonエンジニアを募集しています。
全部とは?!が気になる方は、下記URLを確認して頂きカジュアル面談の応募お待ちしています!!
hrmos.co
Flask 2.0.xへのメジャーバージョンアップ関連資料