こんにちは。エンジニアの遠藤です。
Classiでは、Datadogを使ってシステムの各種メトリクスをモニタリングし、異常があればSlackにアラート通知を飛ばすように設定しています。
今回は、AWSのECSのタスク数に関するアラート通知の設定を変更する機会があり、そのとき何を考え、どう変更したのかという日々の運用の様子を紹介したいと思います。
もともとの設定
あらゆるECSのサービス(以後、サービス)のタスク数について、
aws.ecs.service.desired - aws.ecs.service.running
が5以上になればアラート通知を飛ばすように設定していました。
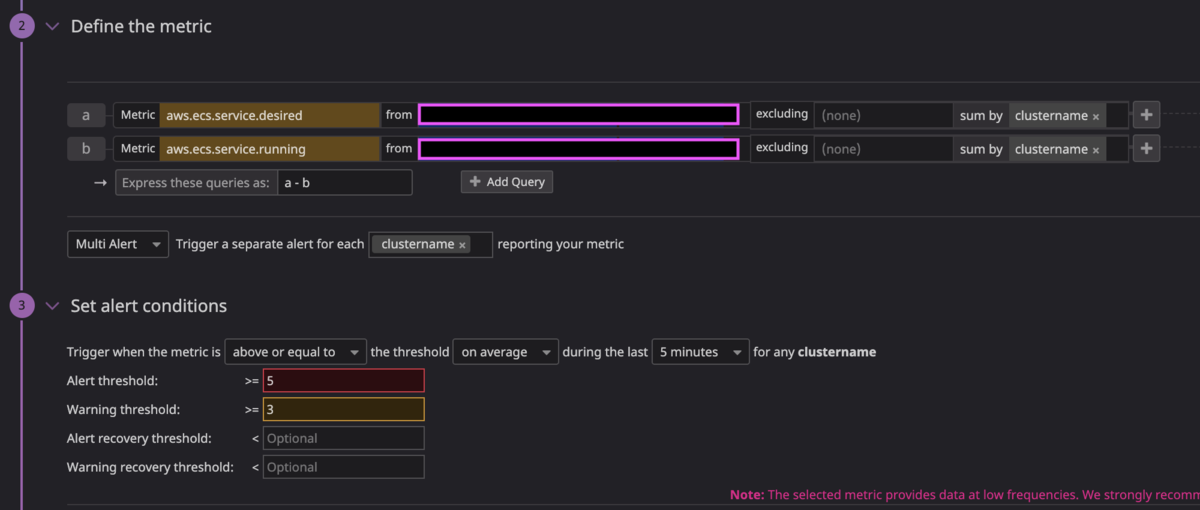
理由としては、例えばサービスAについては desired task が 10 で設定されていて、サービスBについては desired task が 20 で設定されていたとしても、上記の設定であれば問題なく異常(予期せぬ稼働タスク数の減少)を検知できて、汎用性があるからです。
問題
しかし、あるサービスでタスクのスケジュールベースのオートスケールを設定したとき、上記の設定では問題が発生するようになりました。
そのサービスのタスクは、17:00になると10 -> 30 にスケールアウトし、 18:00になると 30 -> 10 にスケールインします。
先のタスク数のモニタリング設定では、17:00に必ず aws.ecs.service.desired - aws.ecs.service.running = 20 となるので、毎日 17:00 にアラート通知が飛ぶようになってしまいました。
これだとアラート通知がオオカミ少年化しているので、なにか対策をしたいところです。
対策
一案として、上記のサービスのみ通知先のSlackチャンネルを変更し、もともと通知を飛ばしていたアラート用のチャンネルからノイズを取り除きつつ、別チャンネルで検知するという対応が考えられました。
ただ、温度感の高いアラート用チャンネルに通知されなくなるので、本当に予期せずタスク数が減少していることを検知する機会を逃すかもしれず、不安です。
何を監視・検知したいのかを改めて考える
そこで「何を監視したいんだっけ?」に立ち返って考えてみると、結局、検知したいのは予期せぬタスク数の減少です。
シンプルに、そのタスク数の減少をモニタリングすればいいのでは?という考えに至りました。 結果的に、以下のように設定しました。
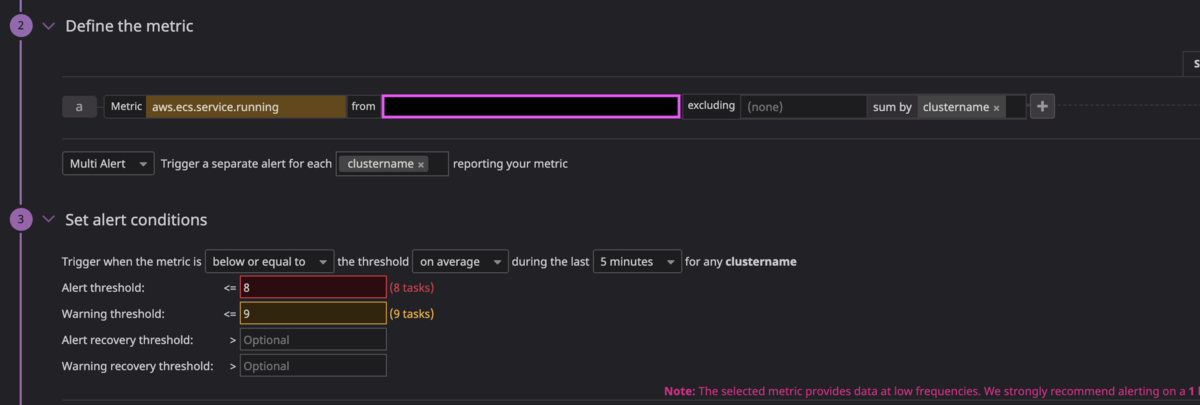
通常稼働しているタスク数は10であるサービスなので aws.ecs.service.running が8以下になったとき、アラート通知を飛ばすように設定しました。
(ちなみにこのサービスについては Blue/Green デプロイをしているので、デプロイ時に稼働中のタスク数が瞬間的に10を下回ることはありません)
このモニタリングの設定は汎用的ではありませんし、タスク数の定義を変更するたびにアラートの閾値を変更する必要があるという若干のトレードオフはありますが、目的は十分に達成できるので採用しました。
まとめ
Datadogのモニタリングの小さな設定変更ですが、タスク数の予期せぬ減少は致命的な障害が起きている可能性が高いので、注意深くメンテナンスしていく必要があります。
Classiでは、今回のような運用の改善をポジティブに捉える文化が根付いていて、日々継続的な改善に取り組んでいます。
ほんの一例ですが、事例としての紹介でした。
これからもこういった日々のメンテナンスを怠らず、積極的に改善していけたらと思います。