こんにちは、最近データエンジニア業を多くやっているデータサイエンティストの白瀧です。
これまでClassiのデータ基盤は、Reverse ETLをしたり監視システムを導入したりとさまざまな進化をしてきました。しかし、Classiプロダクトが発展するとともにデータ量が増加し、これまでのデータ基盤では耐えられない状態に近づいてきました。
そこでデータ基盤の一部(DBからのExportを担う部分)のリアーキテクチャを実施したので、この記事で紹介したいと思います。
概要
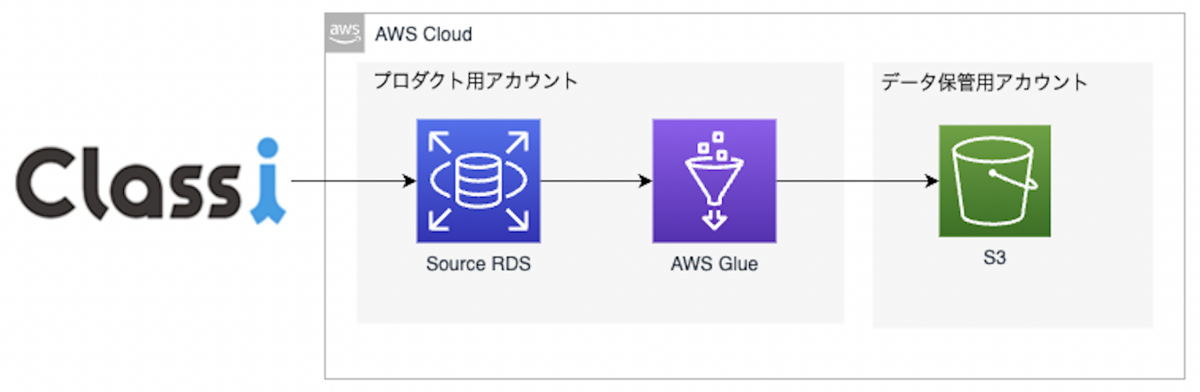
Classiのデータ基盤では、Amazon RDSからAmazon S3へJSONで出力し、その後GCS→BigQueryという流れでデータを送り、BigQueryからもBIツールやReverse ETLなどで使っています。詳細は、Classiのデータ分析基盤であるソクラテスの紹介 - Classi開発者ブログを参照してください。
AWS Glueを使ってRDSからS3に出力していた基盤から、AWS BatchとスケジューラーにGoogle CloudのCloud Composerを使った基盤にリアーキテクチャしました。 主な変更点は以下になります。
- 並行処理を管理しやすくするためにバッチ処理を実装する言語をPythonからGolangに変更した
- CloneしたRDSに接続することで負荷増加によるサービス影響が出ないようにした
【リアーキテクチャ前】
【リアーキテクチャ後】

リアーキテクチャによる費用と処理時間の効果は以下のようになりました。
| 項目 | 効果 |
|---|---|
| 費用 | およそ75%の削減 |
| 一連の実行完了までにかかる時間 | 6時間/日→2時間半/日 およそ60%時間削減 |
| Jobのトータル実行時間 | 110時間/日 → 10時間/日 およそ90%時間削減 |
この記事で話すこと・話さないこと
この記事で話すこと
- 構築したアーキテクチャについて
- リアーキテクチャを実施することになった経緯と課題
- 課題を改善するための技術選定と対応
- リアーキテクチャによる効果
話さないこと
- 各SaaS・クラウドに関する説明
- 選ばなかった選択肢の詳細設計
課題
データ基盤のS3へのExport部分には下記のような課題がありました。
- AWS Glueのメモリ不足によるJobエラーが時々あった
- 1Jobあたりの実行時間が長いため、障害復旧に時間がかかり一度エラーが起きるとサービス影響が出てしまう
- ローカルでの開発スピードが出ない構成で、アジリティが低い状態であった
- サービスとRDS Clusterを共有していて、Export処理による負荷が高すぎることでサービスに影響が出たことがあった
これまで障害ごとに対応していましたが、データの規模と需要が大きくなるにつれてビジネスに影響が出ることが増えてきて根本解決する必要性が高まりました。
AWS Glueのままで上記の課題を改善しようと考えた時に、以下のような問題がAWS Glue(v1,2)特有で起きていました。
- テーブルごとにAWS Glue JobとAWS Glue TriggerのTerraformリソースを作成していたため、Terraformの実行に時間がかかる
- AWS Glue独自のリソース(Data Catalog, AWS Glue Connection)を使わないといけないため、ローカルでの開発スピードが出ない構成だった
- データ基盤全体のスケジューラーがGlueのスケジューラーとCloud Composerのスケジューラーで分かれていた
- スケジューラーが複数あり管理しにくかった
- Glue側のスケジューリングが1テーブルごとに実行時間をずらす職人技になってしまっていた
私たちがAWS Glueをうまく使いこなせてなかった部分もありますが、AWS Glueの特徴であるマネージドな環境でのApache Spark実行とデータカタログとの連携など、どれも私たちが求めているものではありませんでした。
上記からAWS Glueを使い続ける意味もないので、アーキテクチャレベルで変えた方が良いと判断し、リアーキテクチャの方向で検討を始めました。
技術選定と対応
前提・制約
リアーキテクチャを検討する上での前提と制約について紹介します。
- ClassiのRDSは学校ごとにDBが存在するマルチテナント構成
- Reverse ETLの実施によるデータ基盤としての制約
- 前日分のデータが朝8時時点で連携完了していること(つまりデイリー更新は必須でストリーミングは必要ない)
- RDSから取り出す段階でマスキング処理をする必要がある
Reverse ETLについての詳細は、社内向けのデータ基盤から集計結果をReverse ETLしてサービスに組み込んだ話 - Classi開発者ブログを参照してください。
To beと開発方針
To be としては以下を満たすようなデータ基盤にしたいと考えました。
- データ容量に対してスケーラブル
- マルチテナントに対応したExport処理
- 開発しやすい環境
上記を満たす選択肢の1つにModern Data Stackがありますが、社内の既存ルールとマルチテナント構成であることから採用は難しいと判断しました。
Exportを実行する基盤として、必要な要素ごとにAWS Glueで担っていた役割を以下のように分解しました。
- アプリケーションを実行する基盤
- スケジューラー + 依存関係管理
- アプリケーション実装
- 役割は、Connection管理、オーバーヘッド対処、メモリを抑える、テーブルスキーマの管理
- RDS
- サービスに影響出ないように分離する
それぞれについて技術選定と具体的な対応方法を紹介します。
アプリケーションを実行する基盤
アプリケーションを実行する基盤はAWS Batchを選択しましたが、その他にも以下の選択肢を検討しました。
- ECS
- Lambda
Lambdaは、リアーキテクチャ前にボトルネックとなっていたメモリ不足と時間制約から厳しいと判断しました。
ECSの特徴であるリクエストの即時性などは必要なく、ECSクラスタの構築が手間だったりとECSは全体的にオーバースペックと感じました。
上記に対してAWS Batchでは、名前の通りバッチ処理ワークロードに最適化しており、ジョブキューで優先度をつけられるため、Reverse ETLで使用するテーブルを優先的に連携することができることもメリットとして挙げられ、アプリケーション実行基盤はAWS Batchを採用しました。
スケジューラー + 依存関係管理
スケジューラーではGoogle CloudのCloud Composerを採用しました。 ここで検討した選択肢は以下でした。
- Step Functions (AWS)
- Cloud Composer (Google Cloud)
- 自分たちで作る(AWS Lambda + なにかしらのDB)
改めてスケジューラーの役割を整理すると以下になります。
- AWS Batch Jobを実行する
- AWS Batch Jobのstatusを管理する
- タスク間の依存関係を管理して、依存しているジョブが終了するまで実行を待つ
Step Functionsでは、依存関係が複雑になると実装も複雑になってしまうことを懸念しました。また、DBのデータを元に動的にAWS Batch Jobを生成する必要があり、難しいと判断しました。
Lambda + DBでこれを実現する設計・実装のコストが想定したよりも高くなりそうと見積りました。
Cloud Composerは後続であるS3→GCS→BigQueryの実行を管理しており、スケジューラーをデータ基盤全体で1つにまとめることのメリットが大きく、かつ年単位で運用してきたノウハウがあったことからCloud Composerを採用しました。
アプリケーション実装
このセクションでは、アプリケーションを実装する言語の技術選定とリアーキテクチャ前の課題を実装の工夫で解決したことについて紹介します。
パフォーマンスを向上させる
RDSの負荷が高かった原因はDBとのConnection数が多すぎたからでした。リアーキテクチャ前のアプリケーション実装言語であるPythonでConnection管理を実装をする方針もありましたが、Golangの方がConnectionを管理しやすいパッケージが存在し、かつgoroutineとchannelを使うことでメモリを圧迫しにくい実装が容易と判断しました。
さらに、Rubyの会社の手札にGoを加えるまで - Classi開発者ブログにあるように社内にGolangを書くことができるエンジニアがいるため、データエンジニア以外もこのシステムを開発できるというメリットもあり、アプリケーションを実装する言語はGolangを選択しました。
またJobの粒度も見直しました。リアーキテクチャ前は1Jobの単位がテーブルでマルチテナント横断の設計にしていたため、DB数×テーブル数分のDB接続切り替えが必要でしたが、1Jobの単位をDBにしたことで接続の切り替えが必要なく、オーバーヘッドが起こらない設計にしました。
Export対象のカラム変更を容易にした
Export処理を実行するために必要な情報は以下になります。
- カラム定義に対応する構造体
- マスキング対応を含めたSQL
これらの情報はDDLやActive RecordがDBマイグレーション時に生成・更新するスキーマファイルからgo generateで生成するようにしました。 これにより新規DB追加にも既存DBのスキーマ変更にも対応しやすいデータ基盤になりました。
RDS
サービスに影響を出さないために、RDS Cloneを実行しCloneされたRDSに接続するようにしました。 RDS Clone以外に検討した選択肢は以下がありました。
- DB snapshot
- binary logによる Replication
- DB dump
- S3にApache Parquet形式でExport
「S3にApache Parquet形式でExport」は実行時間が長すぎて実用的ではなく、「DB dump」はマスキングをするタイミングが要件を満たせないので選択肢から外しました。
残りの3つはそれぞれ検証の上、デイリー更新に十分な実行速度があり、かつ扱いやすかったのがRDS Cloneだったので決定打となりました。
リアーキテクチャの結果と効果
結果
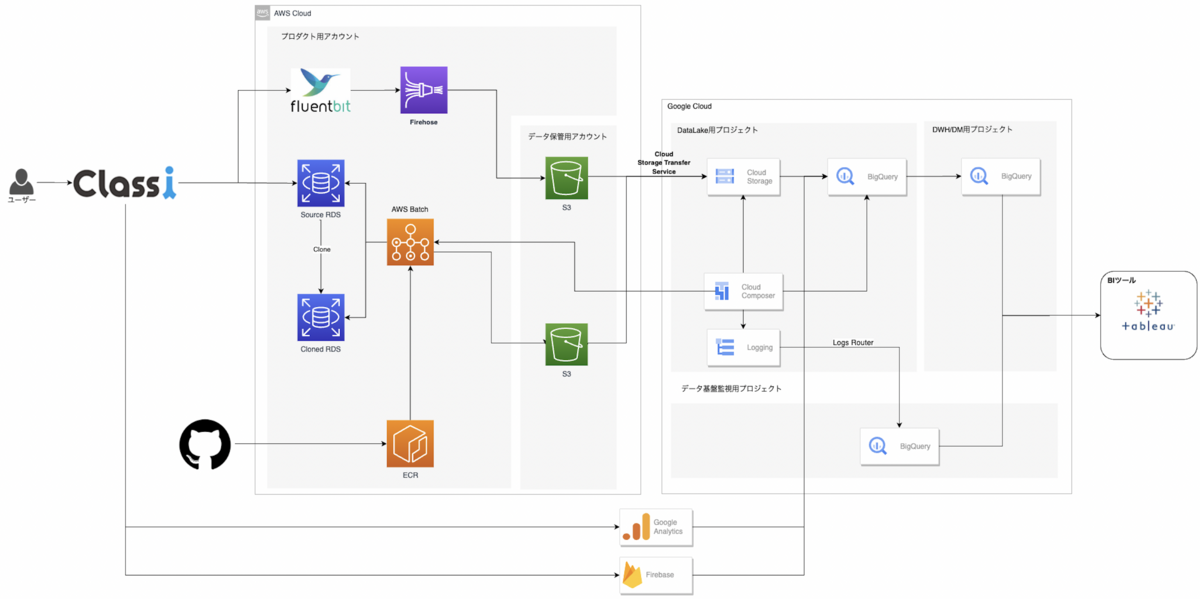
処理の流れは以下のようになります。
- RDSをCloneするAWS Batch Jobを実行
- CloneされたRDSのデータをS3にExportするAWS Batch Jobを実行
- CloneされたRDSをDeleteするJobをAWS Batchで実行
- 後続タスク(S3からBigQueryへの連携など)を実行
効果
冒頭で紹介した内容と重複しますが、まとめて紹介します。
リアーキテクチャ前後で最も効果が見られたのは費用と実行時間です。
| 項目 | 効果 |
|---|---|
| 費用 | およそ75%の削減 |
| 一連の実行完了までにかかる時間 | 6時間/日→2時間半/日 およそ60%時間削減 |
| Jobのトータル実行時間 | 110時間/日 → 10時間/日 およそ90%時間削減 |
削減費用の内訳はAWS GlueとRDSで半々でした。
実行時間が短くなったことで、障害が起きた場合の再実行による復旧の速度が格段に速くなりました。 また、費用と実行時間がともに大幅に抑えられたことで、デイリーよりも早いサイクルでのデータ更新も現実的になりました。
上記以外にもリアーキテクチャによって得られた効果があったので紹介します。
開発体験がよくなった
気軽にstaging環境で実行することができるようになりました。AWS Batch Jobを単体で動かしたい時はAWSのコンソールから実行でき、一連の実行はCloud Composerでトリガーすることができます。開発体験の大幅な改善により、リリース速度が向上しました。
データパイプラインのモニタリングがしやすくなった
リアーキテクチャ前は、RDSからS3まではAWS Glue、S3からBigQueryまではGoogle CloudのCloud Composerが実行管理をしていたため、マルチクラウドかつそれぞれにスケジューラーが存在していました。そのためエラー時にどこでエラーになって止まってしまっていたのかを把握するためにデータ基盤監視システムを導入していました。データ基盤監視システムについての詳細は、データ基盤の品質向上への取り組み - Classi開発者ブログを参照してください。
リアーキテクチャ後では、全てCloud Composerで実行管理するようになったことで、どこでエラーが起きたかはCloud Composerを見ればわかるためモニタリングがしやすい環境になりました。
さいごに
今回のリアーキテクチャによってデータの規模に対してスケーラブルなデータ基盤になり、拡張性も増しました。さらに処理速度も大幅に改善されたことでデイリーより早いサイクルでのデータ更新も現実的になりました。
しかしユーザーへの価値に繋げるためにやることがまだまだたくさんあるので、この辺りを今後取り組んでいきたいと思います。
興味がある方は以下よりご応募をお待ちしております!