はじめに
ClassiのPythonエンジニアで AL(アダプティブラーニング)チームのエンジニアリードの工藤 (id:irisuinwl) です。こんにちは。
最近のマイブームは寿司を握ることです。
さて、今回の記事ではアダプティブラーニングエンジン CALE の進化について書きたいと思います。
CALEとは、ざっくりいえば生徒の解答履歴を分析して能力を推定し、成績向上に役立つ問題を推薦するレコメンドエンジンです。
詳しくは以前の記事を参照ください:
Classiでは今年、新機能である学習トレーニング機能(以下、学トレ)をリリースしました。
学トレの一つに「AIが一人ひとりに合わせたおすすめ問題を提示する」機能があり、そちらでCALEが使われています。
元々学トレリリース前ではWebテスト機能にて個別最適学習を実現するためのレコメンドを行っており、そのロジック実現のためCALE v1.0は利用されていました。
今回、学トレでのおすすめ問題機能を実現するにあたって、CALEを進化させるため、CALE v2.0 を開発しました。
この記事では、CALE v1.0からv2.0へどのように進化したかを紹介します。
概要
CALE v1.0 ではリリース後の運用を通して、以下の課題が見つかりました。
- Kubernetes の運用負担が大きい
- 複雑なユースケースから生じる複雑なAPIエンドポイントとデータモデル
- 当初の期待に対して過剰で複雑なストレージ構成とサービス構成
それに対してCALE v2.0では複雑にならないように以下のようにアーキテクチャ変更・開発の工夫をしました。
- アプリケーション基盤の変更: Google Kubernetes Engine (GKE) から Amazon Elastic Container Service (ECS) へと移行
- ユースケースの抽出とAPIエンドポイントの簡素化: ユースケースを課題配信・問題解答・レコメンドの3つを抽出、v1では8つあった API エンドポイントをv2では3つに絞り込みました。
- ストレージ構成の変更: MySQL + Firestore + Google Cloud Storage (GCS) から MySQLのみの構成へと変更
- サービス構成の統合: APIサービスとレコメンドロジックサービスの分離構成を統合し、モジュラーモノリスへと変更
結果としてシンプルなアーキテクチャを実現することができ、効果として以下のリードタイム短縮とレイテンシー改善をすることが出来ました
- リリースまでのリードタイム中央値: 289時間 -> 129時間
- 課題配信API p95 平均レイテンシー:
- v1:258ms -> v2: 26.8ms
- 問題解答API p95 平均レイテンシー:
- v1: 413.7ms -> v2: 103.8ms
- レコメンドAPI p95 平均レイテンシー:
- v1: 497.5ms -> v2: 28.6ms
従来のアーキテクチャ
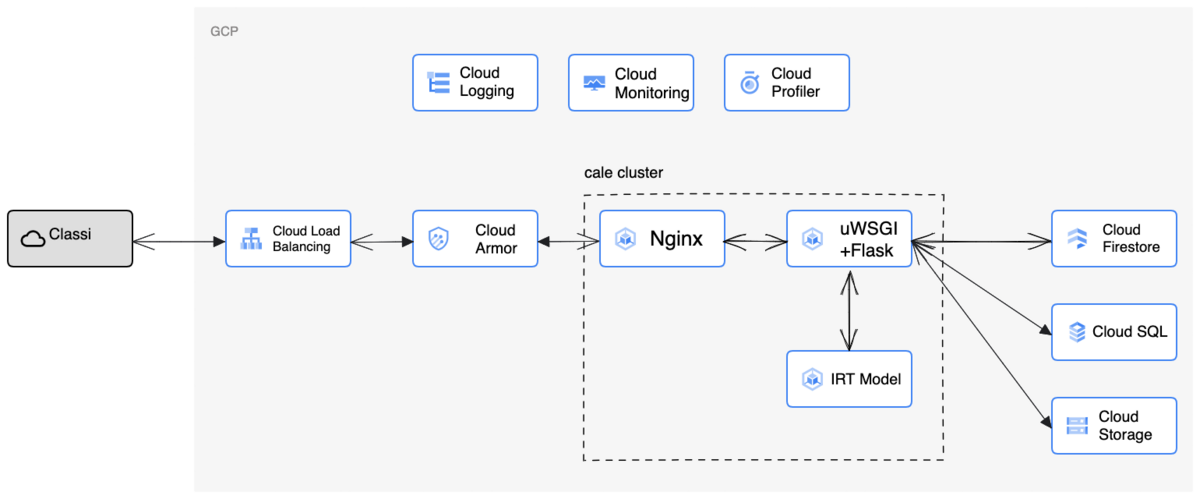
従来、CALEのアプリケーション基盤は全てGCP上で構築されており、AWS上のClassiサービスと通信していました。
- アプリケーション基盤: Google Kubernetes Engine
- ストレージサービス: Cloud SQLとCloud StorageとFirestore
アプリケーション基盤の変更
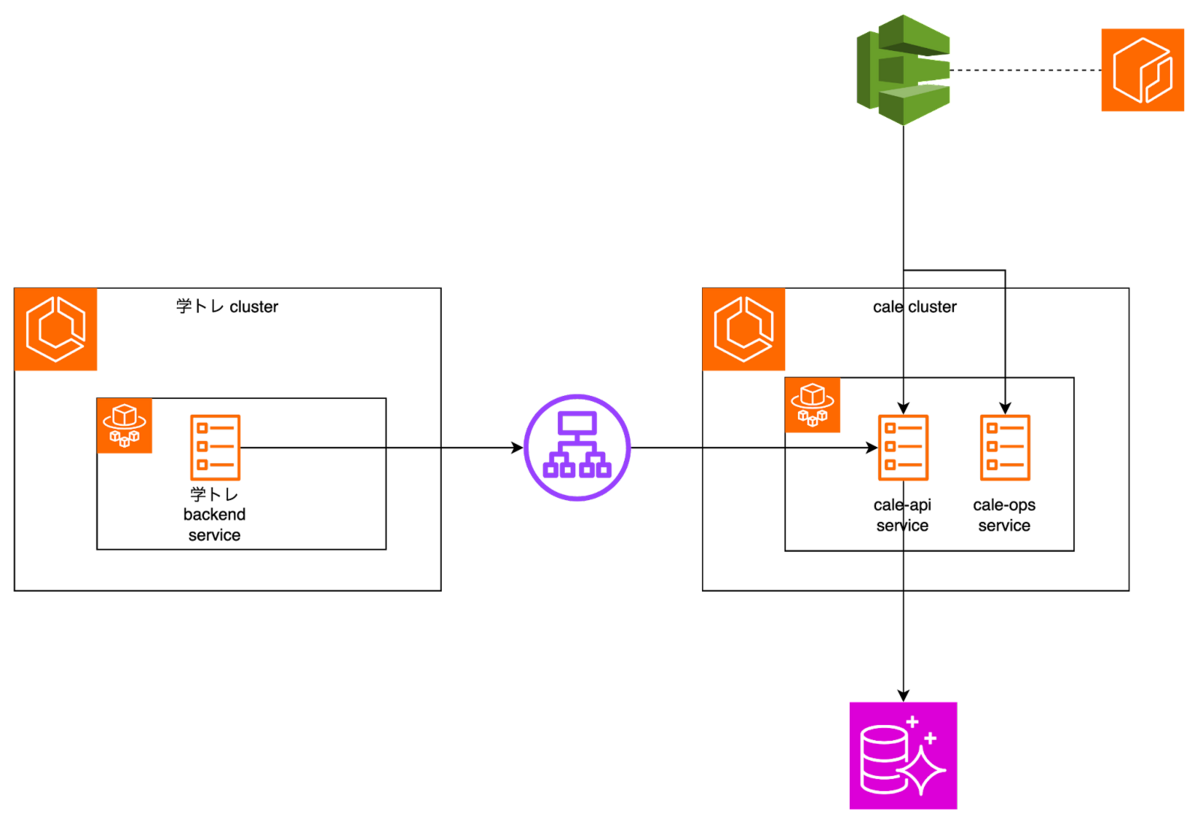
CALE v2.0 ではアプリケーション基盤をGKE から ECS へと移行しました。
移行を決定した背景
CALEで当初GKEを選定した理由としては以下のとおりです。:
- データ基盤がGCPにあるため、データプロダクトであるCALEもGCPに置くと良いと考えた
- CALEの利用が大規模であっても問題ないことや、様々なデータプロダクトを構築することを期待し、高いスケーラビリティと柔軟性を期待してKubernetesを導入した
しかし、下記の理由から当初期待していたスケーラビリティは必要ありませんでした。
- 実際にはCALEの運用もあり、新規データプロダクトを0から開発し、すぐにリリースできない
- CALEの利用規模は平均DAUは数千人と中規模である
一方、Classi の主要サービスはAWS上に構築されており、異なる技術スタックを用いることで、システムの管理をより複雑にしていました。
また、 Kubernetes 運用スキル習得の学習コストが予想以上に高く、CALE開発チーム外へスキルを広げることが困難でした。
そして、リリースした現状を顧みると、大規模なスケーラビリティは不要で、Classiのエンジニアが誰でも運用可能なインフラを構築する方が良いだろうと考えました。
それらの理由から GKE を ECS にする意思決定をしました。
移行作業
具体的な作業はGKEからECS Fargateへの移行、そしてCloud SQLからAmazon Auroraへの移行を行いました。
そして、CALE v1.0を廃止する予定でしたので、初期段階ではFirestore, GCS の移行はしませんでした。
移行作業は全体として約3ヶ月を要し、結果として重大な障害はなく、移行することが出来ました。
ユースケース設計とAPI設計の変更
CALE v2.0 の開発では、ソフトウェアエンジニアが要求定義の段階から検討に参加し、ユースケースの設計をして、API設計・実装を行いました。
CALE v1.0 のAPIでは、様々な要求の整理が甘かった結果、実現したいことに対して複雑な実装となってしまいました。
この状況を反省し、CALE v2.0では、企画段階から参画し、アダプティブラーニングに関する利用体験のオーナーシップを持ち、開発をしようと考えました。
学習トレーニング機能のユースケース設計
学トレのユースケース設計は、開発ディレクターと協力し、慎重に行いました。
ここで、我々はClassiで提供する課題配信の学習体験を再定義しました
- (課題配信)先生が生徒に解いてもらいたい課題を選択し、配信する
- (問題解答)生徒は配信されたテスト課題を回答する
- (おすすめ問題演習)生徒は、テスト課題を解いた結果から、より成績が向上する問題の候補を提案され、そのうち一つを選択して解答する
この体験からCALEの提供するおすすめ問題演習という体験は、学トレが提供する学習体験全体の一部であることを認識し、全体の体験と整合性のあるアダプティブラーニングの体験を考えました。
特に、課題配信からおすすめ問題を解くという体験に関しては、我々ALチームが主体となりユースケース設計を行いました。
レビュープロセスとして、開発ディレクター、ALチームリーダー、学トレ開発リーダーの三人で不足した要求が無いかを確認しました。
その結果、「課題配信」、「問題解答」、「おすすめ問題演習」という3つの基本的なユースケースを特定することができました。
また、CALE v1.0 では、コンテンツディレクターによる管理画面での問題登録というユースケースがありました。
問題登録のユースケースは、学習トレーニングではコンテンツ管理システム *1 が開発されたため、CALE v2.0 のAPIでは考慮しなくて良くなりました。
成果物として、抽出したユースケースに関して、達成に必要なデータ概念や処理内容を記述したプロセス設計図を作成しました。
また、意思決定の過程を追跡しやすくするため、designdoc として全て文書化しました。
API設計の見直し
CALE v1.0では8つのAPIエンドポイントがありましたが、v2.0では先述の3つのユースケースに絞り込み、エンドポイントを設計しました。
また、問題登録についてもCALE v2.0のAPIエンドポイントとしては不要となりました。
この変更により、システムの複雑さを軽減し、開発者が迅速に機能を実装・改善できることを期待しました。
Open APIのAPI仕様書とAPI設計の意思決定を記した designdoc を作成し、学トレ開発チームとALチームでレビューしながらデザインしました。
データモデリングとストレージの変更
データモデリング
ユースケースを定義した後、データの概念および関係を明らかにするためにデータモデリングを行いました。
概念設計、詳細設計、物理設計の順序でデータモデリングを進めました。
- 概念設計では、おすすめ問題解答というユースケースにおいて、関連するシステムの全ての概念を記述しました。例えば、学トレにおける配信の概念などを全て記載しました。アウトプットは概念と関係の図となりました。
- 詳細設計では、概念設計でCALEに関係する概念のエンティティ図を書きました。
- 物理設計では、OR Mapper(SQL Alchemy)のModel Class実装と、マイグレーションツール(Alembic) のマイグレーションファイルの実装を行いました。
そして、モデリングにおける重要な意思決定は、designdocに記録しました。
また、モデリング時に判明した考慮されていないユースケースの変更は再度関係者との要求定義に関するコミュニケーションを行いました。
ストレージ構成の見直し
CALE v1.0では、アプリケーションとレコメンドロジックを分離し、負荷の高いワークロードを達成すること、スキーマの柔軟性を意図して、MySQLとFirestoreを使用していました。
しかし、v1.0をリリースし、その利用状況を観察した結果、レコメンドロジックにはスキーマ柔軟性が不要であることが明らかになりました。
また、コンテンツデータの管理にGoogle Cloud Storage (GCS) を使用しておりました。
しかし、コンテンツ管理システムからのデータ取り込み処理を行えば、GCSの使用は不要であることが判明しました。
そのため、CALE v2.0ではAurora MySQLのみのシンプルなストレージ構成へと変更しました。
サービス構成の変更
CALE v2.0ではv1.0では分離していたWeb APIとレコメンドロジックの2サービスを統合し、モジュラーモノリスのアーキテクチャへと変更しました。
CALE v1.0では、Web APIとレコメンドロジックを別々のサービスおよびコードベースとして管理していました。
この設計の背景には、レコメンドロジックを自由に、かつ迅速に改変できることに期待を寄せていました。
しかし、Web APIとレコメンドロジックの両方を同時に開発して衝突する機会は少なく、当初想定したような高い柔軟性は必要とされませんでした。
一方で、複数のサービスを運用することに伴う複雑さ(例えばエラー調査の困難さやネットワーク障害時のエラーハンドリングなど)が顕著になりました。これらの課題は、当初の期待した開発のしやすさに比べて、過大なコストを要しました。
そのため、レコメンドロジックモジュールをWeb APIのサービスに統合し、よりシンプルなモジュラーモノリスのアーキテクチャに変更しました。
もちろん、過去に分割した構成で提供しているので、将来的に必要となれば、再びサービスを分割することも可能な形で統合を行いました。
この改修により、システムの複雑さを軽減し、開発および運用の効率を高めることができました。
実際、v2.0のリードタイム時間について、箱ひげ図の比較を見ると短縮されたことが見れます。

- 比較対象: v2開発前の期間(2022年4月〜2022年12月) vs v2開発後運用が落ち着いた1ヶ月後の期間(2023年7月〜2023年11月)
- 計測対象: Pull Request が作られてからリリースされるまでのリードタイム時間 (hour)
- リードタイムの中央値変化: 289時間 -> 129時間
まとめ
CALEのv2.0へのアップデートでは、様々なリアーキテクチャを通して、よりシンプルで効率的なシステム構成を実現しました。
結果として、リリースまでのリードタイム中央値を289時間から129時間の短縮を実現しました。
また、シンプルなアーキテクチャによる副次的効果として、v2.0では以下のレイテンシー改善を達成しました
- 課題配信API p95 平均レイテンシー:
- v1:258ms -> v2: 26.8ms
- 問題解答API p95 平均レイテンシー:
- v1: 413.7ms -> v2: 103.8ms
- レコメンドAPI p95 平均レイテンシー:
- v1: 497.5ms -> v2: 28.6ms
この変更は、特に大きなチャレンジをしたという訳ではなく、むしろ現実的で合理的なアプローチに重点を置いていました;
- システム依存関係の再評価: どの部分が分離されるべきか、または統合されるべきかを検討した
- ユースケース主導の設計: 分断すべきでない全体ユースケース設計に関与し、おすすめ演習レコメンドが中心となるようなユースケースはチームが主体となった
- 意思決定の透明性: 要求定義・設計・実装における重要な意思決定の過程をdesigndocとして残した
- シンプルなアーキテクチャ: 必要とされていない、または期待に応えられないと考えられるアーキテクチャは変更した
結果として、期待に適合したシンプルなアーキテクチャを作ることができ、また効果としてレイテンシーを小さくすることができました。
今後の展望としては、レコメンド機能の根幹である解答履歴データの管理方法を再考しています。
具体的には、学習トレーニング機能(学トレ)とCALEがそれぞれ独立して保存している解答履歴を、一元化して管理することを検討しています。これにより、データの整合性を高め、レコメンドロジック開発の柔軟性をさらに向上させることを目指しています。
*1:コンテンツ管理システムについては過去の記事を参照 tech.classi.jp