はじめに
こんにちは、Pythonエンジニアをしてます工藤( id:irisuinwl )です。 この度、Classi独自のアダプティブラーニングエンジンである Classi Adaptive Learning Engine (CALE) をリリースしました。
自分は主にCALE開発において、レコメンドを行うエンジン部分のバックエンドを担当しました。 今回の記事では、0からレコメンドシステムを開発し、システムが安定稼働する品質を実現したノウハウを紹介したいと思います。
CALEの概要
アダプティブラーニングとは、個別最適化学習のことを言います。 CALEでは、従来のClassiでのテスト機能である先生から生徒へのテストを配信、テスト解答に加えて、テスト終了後に生徒のそれぞれの理解に応じて問題を出題し、そのテストについて生徒それぞれの理解を深めるための機能を実現しました。
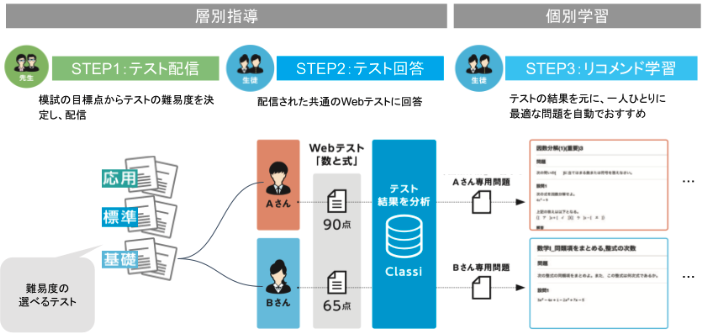
アーキテクチャ
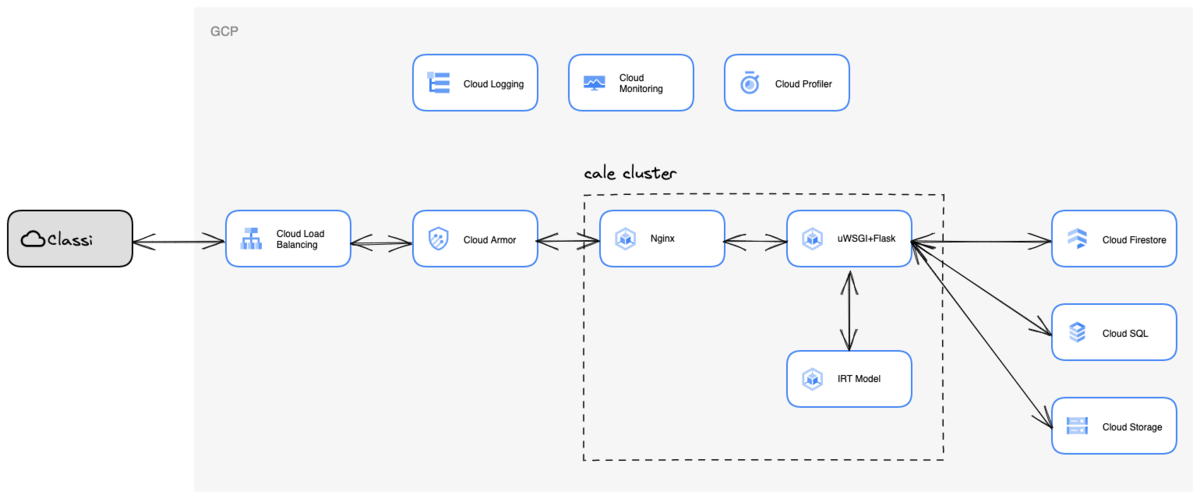
CALEは Google Cloud (Google Cloud Platform, 以下 GCP) 上で構築されており、アプリケーション基盤としてGoogle Kubernetes Engine (以下 GKE) を使っております。
推論するためのモデルとAPIのpodは分離し、モデル開発とAPI開発の責務分割および、将来的に様々なモデルによって推論できるように設計をしました。
レコメンドエンジンのAPI部分はFlaskを用いて実装しており、ストレージには Firestore, Cloud SQL, Cloud Storage を利用しております。
工夫した点
CALEは新規システムであり、個別最適化学習を実現するレコメンドエンジンの要求仕様や、良いレコメンドの体験など、見えない部分が多いです。そのため、システムが安定稼働すること、つまりシステムの品質を守ることを重視しました。 以下ではシステムの品質を高める上で、工夫したTipsを紹介していきます。
本記事で紹介する取り組みを実施することで、CALEでは
- valid rateが99.99%,
- 95%ile latencyが779ms
という安定したシステムを実現することができました。
テスティング
テストを書くことは品質を保つ点において重要です。 CALEでは以下のテストをおこなっていました。
- ユニットテスト
- インテグレーションテスト
- 負荷テスト
- QA
ユニットテスト、インテグレーションテストではPythonのテストフレームワークであるpytestを用いてテストしました。
コードカバレッジはQAチームと相談し、C1 Coverageを選択しました。最終的にカバレッジを95%以上高めることができました。
負荷テストは、LocustというPythonの負荷テストライブラリを用いて実装しております。
各API呼び出しのユースケースに対して、今期想定されるユーザー利用数から負荷のテスト設計・実装を行い、ビジネスサイドに近いプロダクトオーナーを含めてレビューを行いました。 また、レイテンシが高まる観点として、登録したユーザー数、レコメンドされる問題数、蓄積された解答数といった、データ量を観点に入れて負荷テストの設計・実装を行いました。
Locustの詳細な使い方は以前自分が書いた こちらの記事 を参考に頂ければ幸いです。
QAではAutifyを使って、実際にユーザーを想定したユースケースのE2Eテストを定期実行しました。E2Eテストの自動化によって、アジリティ高くデプロイすることが出来ました。
運用・監視
運用・監視はCloud Operationsの内、以下を利用しました。
- Cloud Logging
- Cloud Monitoring
- Cloud Profiler
特にCloud LoggingのPython clientがv3.0.0 になってからさまざまな情報を構造化ロギングすることが出来、使い勝手が良かったです。
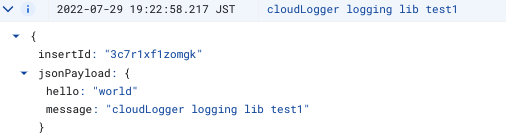
以下のようにextra引数に値を入れることでログのjsonPayloadに値を入れることが出来ます。
import logging from google.cloud.logging.handlers import CloudLoggingHandler import google.cloud.logging client = google.cloud.logging.Client(project="test-project") handler = CloudLoggingHandler(client) # setup_logging(handler) cloud_logger = logging.getLogger('cloudLogger') cloud_logger.setLevel(logging.INFO) cloud_logger.addHandler(handler) data_dict = {"hello": "world"} cloud_logger.info("cloudLogger logging lib test1", extra={"json_fields": data_dict})
上のコードを実行すると、以下のようにログが出力されます。
また、運用と開発を両立するために SLI/SLO を設定しました。 GCP が提供している SLI/SLOに関するドキュメント を参考に、以下の流れで作成しました:
- 利用ユースケースをまとめる
- 利用ユースケース (クリティカルユーザージャーニー)の一覧化
- ユースケースごとの影響度合いを考える
- データ分析
- 各ユースケースにおける処理の性能を測る
- 現状の利用状況に対して、厳しく設定するのか、緩く設定するのかを考える
- SLIの設計
- 上記で洗い出したユースケースごとに設計する
- ユーザーがサービスを問題なく使えるために見るべき数値は何かを指標に落とす
- SLOの設計
- ユーザーがサービスを問題なく使えるために指標をどの程度にすれば良いかを考える
そして、考えた基準をCloud Loggingのログベース指標でメトリクスを取得し、Cloud Monitoringのサービス経由でSLI/SLOに設定しました。
Kubernetesやインフラの運用テスト
開発環境で運用のテストも行いました。 テストの手順としては先述したLocustでのシナリオテストを常に行いながら、インフラの構成変更、スケーリングなどをテストし、ダウンタイムが生じるかを確認しました。 基本的には考えられる運用を列挙して、その洗い出した項目をテストをしました。 以下がその項目の一例となります。
- 高負荷を掛けて、GKEのオートスケーリング時の挙動をテストする
- クラスタのアップデート
- ノードのアップデート
- 誤ったイメージをpush, rollbackする
- Cloud SQLのフェイルオーバー
- 稼働中のモデルデプロイ
このテストをすることにより、スケーリング時のダウンタイムが発見でき、Kubernetesの Pod Terminate時のベストプラクティス に従い、対処することが出来ました。
まとめ
アダプティブラーニングエンジンであるCALEの高いシステム品質を実現する取り組みを紹介しました。
100%安定したシステムを実現することは不可能にせよ、今回の記事で紹介した
- 利用に則したテストを行う
- SLI/SLOといった品質の基準をビジネスサイドおよび開発者全体で合意をとる
といった取り組みを続けていれば、システムが運用できるか、期待するシステム品質の実現できるかが自ずと分かり、高い品質のシステムの実現を達成できると考えております。
Classi では学校教育の現場で使われる高い品質のサービスを実現していく必要があります。 レコメンドエンジンを初めとした全国の学校で利用される新しい教育×データ活用サービス、そして、教育現場で安定稼働するシステムを一緒に作っていきたいと思った方は是非、Pythonエンジニアにご応募ください!