こんにちは、データプラットフォームチームの鳥山(@to_lz1)です。エンジニアの皆さん、自分のチームのパフォーマンス、計測していますか?
DevOps Research and Assessment(DORA)の2019年のレポート により、開発チームのパフォーマンスを示す指標として提唱された「Four Keys」。この中に「デプロイ頻度」「変更のリードタイム」という指標があります。
『LeanとDevOpsの科学』など有名な書籍で取り上げられたこともありFour Keysそのものが広く知られるようになりましたが*1、この度Classiでもこれらの指標を可視化するダッシュボードを構築し、社内提供を始めました。
計測の事例がインターネット上に多くある中でも、
- 横展開を極力容易にするための設計
- リリースをしてみてから「実際に役に立てる」までの工夫とフォローアップ
といった辺りに独自性があるかと思うので、その内容について本記事で紹介していきます。
「変更のリードタイム」の定義
まず最初に、「変更のリードタイム」の定義について整理しておきましょう。
Googleのブログ 中には「commit から本番環境稼働までの所要時間」と表現されていますが、単純なようでいてさまざまな「定義の揺れ」を引き起こしています。例えば、以下のような議論があります。
「本番環境稼働まで」というのは明確なのですが、「commit から」というのがどうにも曖昧で、よくわからないのです。なにかの時間を測るには start と end が必要ですが、この start にいくつかの解釈があるのです。*2
ここでいうstartの解釈には、以下のようなものがあります。
- 開発チケットが作られた日時
- 開発チケットが IN PROGRESS 相当のステータスになった日時
- 担当者が実装を完了し Pull Request (以下、PR) を出すための commit をした日時
- PR のレビューやQAが終わり、あとは deploy を待つだけの merge commit をした日時
そして、どれが正解か?というと実は難しいです。先に引用した記事を読む限り、最も原義に近いのは「あとは deploy を待つだけの merge commit をした日時」だと思われます。しかし、それでは「マージからデプロイまでが自動化されているか(≒DevOpsの練度)」を測ることはできても「PRのマージまでに何が起きているのか」は見えてきません。我々開発者からすると、現代において「開発生産性」を測るには不十分な印象が否めないのではないでしょうか。
筆者は「どれが最適かは計測のしやすさや理解のしやすさにより、組織ごとにカスタマイズした定義を用いれば良い」という立場に立っています。今回の取り組みでは、最終的に以下の2つの指標を組み合わせて使うことにしました。
- 開発者がPRを出してから、マージされるまでの時間
- mainブランチにマージされた全てのコミットの、作成からデプロイ完了までの時間
「開発者がPRを出してから、マージされるまでの時間」が長くなっている場合は、PRを出してからレビューするまでのプロセスに課題があると考えられます。例えば、
- PRの粒度が大きすぎる
- 開発者のタスクが多すぎてレビューの時間や知識移転の時間が十分に取れていない
などです。
「開発者がPRを出してから、マージされるまでの時間」は短いのに、「mainブランチにマージされた全てのコミットの、作成からデプロイ完了までの時間」が長いという場合は、PRを出す前、またはPRのマージ後に課題があると考えられます。例えば、
- 開発着手してからPRを出すまでに要件の確認が多く発生している
- マージしてからデプロイするまでが適切に自動化されていない
などです。このように、「指標に大きな増減があった時に、何かチームの健康状態に関する情報が得られそうか」という点を意識しながら指標を設計・改善していきました。
実際に作ったもの
現時点では、Redashを使って開発チームにダッシュボードを公開しています。

複数のリポジトリを選択できるようにしている点は特徴的かと思います。

Classiは大きな機能ごとに開発チームを分ける、フィーチャーチームに近い体制を取っています*3。更にこの中で、「あるチームが複数のリポジトリを管理する」といったことも当たり前です。それ故に、「チームごとにリポジトリを選べること」「複数のリポジトリを横断してデータを可視化できること」が必須の要件だったのでこのような実装にしました。
また、ダッシュボード下部には「直近マージされたPRの一覧」もあります。
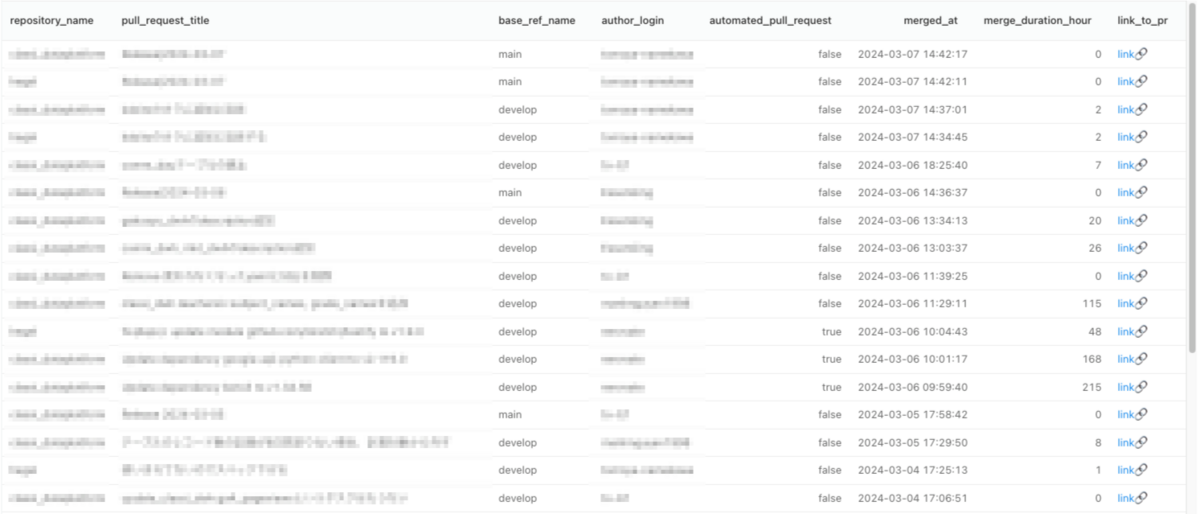
RedashのTableは、デフォルトではクエリ結果に含まれるhtmlをエスケープせずそのままレンダリングするため、これを利用してPRへのリンクを付けています*4。以下のようなクエリで手軽に実現できるので便利です。
select repository_name, pull_request_title, base_ref_name, author_login, automated_pull_request, merged_at, merge_duration_hour, '<a target="_blank" href="https://github.com/{organization_name}/' || repository_name || '/pull/' || pull_request_number || '">link🔗</a>' as link_to_pr from `four_keys.merged_pull_requests` where repository_name in ( {{ Repositories }} ) and merged_at >= date_sub(current_date('Asia/Tokyo'), interval 14 day) order by merged_at desc
設計と利用技術
パイプライン全体の構成図は以下の図のようになっています。

Classiには多数のリポジトリがありますが、巨大な開発組織ではないのでマージされるPRの数は週に数百オーダーといったところです。このため、データプラットフォームチームで運用しているCloud Composerをバッチ実行基盤とし、日次でデータをPullするようなアーキテクチャを選択しました*5。
認証には、 GitHub App として発行したインストールアクセストークンを用いています。有効期間が短いトークンを処理の都度発行するため、セキュリティレベルを保ちながら、PATを人手で更新するようなtoilをゼロにできます。
また、データの収集には GraphQL API を採用しました。GitHubのGraphQL APIは実務では初めて触ったため最初はスキーマの理解が大変でしたが、公式に提供されている GraphQL API Explorer の利便性が素晴らしく、効率よく理解を深められました。
取得したデータはjsonlファイルとしてGCSに保存し、 Cloud Storage BigLake Table として参照しています。図中の点線部分がこれにあたり、実体となるテーブルをわざわざ作らなくてもjsonlファイルをSQLで即座にクエリできるので、大変便利な機能です。Connectionという概念を挟んでいることで権限の管理もしやすく、これも使ってみて嬉しいポイントでした。
BigLake Tableは メタデータキャッシュ という機能を持っており、特に大量のファイルを扱うようなケースでクエリを効率的に処理してくれます。しかし、メタデータキャッシュが更新されるまでは新たに追加されたファイルがクエリできないなど、面倒な点もあるので、今回のようなユースケースではバッチ処理の都度BigLake Tableを再作成してしまうのも手かと思います。我々のチームでは以下のようなコードで毎回の処理の最後に create or replace external table 文を流しています。
if __name__ == "__main__": # ... (省略) gql_client = get_gql_client() pull_requests_file_name_suffix = "merged_pull_requests" data = extract_pull_requests(gql_client, date_from, date_to) upload_blob(data, pull_requests_file_name_suffix) create_or_replace_external_table(pull_requests_file_name_suffix) # ... (省略)
def create_or_replace_external_table(file_name_suffix: str) -> None: bigquery_client = bigquery.Client(project=DATAPLATFORM_PROJECT_ID) query_job = bigquery_client.query( f""" CREATE OR REPLACE EXTERNAL TABLE `{DATAPLATFORM_PROJECT_ID}.github.{file_name_suffix}` WITH CONNECTION `{DATAPLATFORM_PROJECT_ID}.{BIGQUERY_CONNECTION_NAME}` OPTIONS( format ="NEWLINE_DELIMITED_JSON", uris = ['gs://{BUCKET_NAME}/*_{file_name_suffix}.jsonl'], max_staleness = interval 1 day, metadata_cache_mode = AUTOMATIC ); """ ) # wait for job to complete. _ = query_job.result()
工夫した点
以下では、開発や導入推進における工夫点を紹介します。
「1行のPRで導入できる」体験設計
序盤から全リポジトリを収集対象にしても良かったのですが、データ量が膨れ上がっても困るため、「利用者側からPRを出してもらって対象リポジトリをOpt-in的に追加していく」という方式を取りました。
リポジトリの追加作業が大変では誰も使ってくれないということが容易に予想できるので、実際の変更は対象リポジトリ名の配列に要素を追加するだけで済むようにしました。

このPRは実際に利用者側のチームメンバーから出して頂いたものです。場合によってはデータの過去遡及反映が必要ですが、これもデータプラットフォームチーム側で一度ジョブを流せば完結するような設計にしています。これらのプロセスを簡略化したことで案内や運用も非常にやりやすかったため、アプローチとして正解だったと思っています。
ベストプラクティスの緩やかな強制
ダッシュボードには「デプロイ頻度」のウィジェットもありますが、チーム横断で計測するには妥当性と実現性のある「デプロイの定義」を決めなければなりません。

これについては、開発初期から「GitHub Environmentを用いた、”production”という名前が付いた環境に対するDeploymentだけを計測対象とする」という方針を定めました。
GitHub Environmentは、環境ごとの変数の定義や、きめ細やかなレビュー・デプロイ時の制約を設定できる便利な機能です。
導入もGitHub Actionsのyamlに1行書くだけと非常に簡単なので、新たに導入してもらう場合でもコストパフォーマンスが良いだろうと判断しました。
Googleのブログでは、プラットフォームエンジニアリングに関して以下のような記述があります。
組織において有用な抽象化を行い、セルフサービス インフラストラクチャを構築するアプローチです。散乱したツールをまとめ、デベロッパーの生産性を高める効果があります。
作ってみてから思ったことではありますが、このように緩やかにベストプラクティスを推進する設計もまた、プラットフォームエンジニアリングの一例と言えるかもしれません。
実利用の現場への入り込み
パイプラインとダッシュボードの初期開発は2週間程度で完了しましたが、実際に利用を普及させるまでには宣伝と利用者ニーズを踏まえた改善が欠かせません。
これについてはどのチームにアプローチするのが良いかマネージャとも相談し、対象のチームに可能な限り深く入り込んで活用のチャンスを探りました。具体的には、
- そのチームのミーティングに参加して普段のデータに対する接し方を見る
- リードタイムを集計する既存の取り組みについて聞き、課題感を知る
などです。後者に関しては先日の別記事でも紹介がありましたが、チームの振り返り会の中でリードタイムなどの指標をうまく使っている事例があると分かりました。
PRの粒度が大きい場合や複雑な場合にリードタイムがかなり伸びるということがわかりました。
開いた時に難しそうだと感じるPRは、レビューを後回しにするのではなく、ペアレビューチャンスだと思うようになりました
この取り組みを更に支援すべく、当該チームがシェルスクリプトとスプレッドシートで集計していた指標をダッシュボードにも盛り込み、既存オペレーションからの移行を推進しました。
この結果、チームメンバーからも「手動でぽちぽち計測しなくてもよくなったのでとても楽になって助かった」といったフィードバックをもらえました。
今後の展望
指標を追加する
本記事中でもFour Keysという言葉を何度も使ってきました。当初は「Four Keysをいい感じに可視化しよう」という意図もあったのですが、現在のところは「デプロイ頻度」と「変更のリードタイム」のTwo Keysしか測っていません。
デプロイの頻度と変更のリードタイムは速度の指標であり、変更障害率とサービス復元時間は安定性の指標*6
とも言うように、現在計測できているのは「速度の指標」だけということになります。
とはいえ、変更障害率とサービス復元時間が安定性を測る上で最適かと言うと、また議論の余地があると思っています。このため、ダッシュボードにはこれらの指標をしばらく実装する予定はありません*7。
Classiでは現在、SREチームがSLI/SLOの整理と策定を進めてくれている*8ため、これらの取り組みと合流するなどの道も考えられます。筆者としては、「開発チームの気づきを適切に促すこと」がまず第一目的であり、その目的に合致する指標を都度磨き上げていけば良いだろうと考えています。
より定量的な成果に繋げる
今のところ得られたフィードバックはポジティブながら定性的なものが多く「成果」としては弱いです。PRのマージまでの時間を見るのも良いですが、理想を言えば、デプロイ頻度や変更のリードタイムまで含めて向上できたか、更にはリリースした機能が実際にユーザに届くようなインパクトを出したか、という点を語ることこそが重要ではないでしょうか。
そうした会話が当たり前になるためには、メンバー個人の成長も、エンジニアという枠を超えたチームの成長も必要かもしれません。そのような気づきと議論を促進できる指標が何か発見できれば、それを速やかに可視化して提供するのもデータエンジニアの今後の役割だと思っています。
まとめ
Classiの開発チームの「速さ」を測定し、可視化し、気づきを得るためのダッシュボードについて、技術的な面と利活用の面からお話ししました。
Classiでは開発者の体験を良くするために技術を駆使するエンジニアも、最高の開発者体験を享受しながら教育業界に価値を生み出すチャレンジをするエンジニアも、絶賛募集中です。興味をお持ちになった方は、ぜひカジュアル面談や面接に応募してみて下さい!
*1:four keysリポジトリは2024年1月にアーカイブされており、率直なところハイプサイクルの幻滅期に至った感覚はあります
*2:https://zenn.dev/junichiro/articles/481b6a0658ba03
*3:現体制が選択されるに至った背景はこちらの記事でお読み頂けます https://tech.classi.jp/entry/2023/08/31/100000
*4:もちろんサニタイズはされます。ref: https://redash.io/help/user-guide/visualizations/table-visualizations
*5:扱うデータが膨大であれば、イベント駆動でデータをPushする構成が望ましいでしょう
*6:https://cloud.google.com/blog/ja/products/gcp/using-the-four-keys-to-measure-your-devops-performance
*7:指標の元になるデータを「あらかじめ収集しておく」ことは言うまでもなく重要です。この観点で言うと、障害報告をチーム横断で管理するスプレッドシートが存在するので、少なくとも「サービス復元時間」は容易に算出できます。