この記事はClassi developers Advent Calendar 2021の24日目の記事です。
こんにちは、データAI部でPythonエンジニアをしている平田(@JesseTetsuya)です。普段は、PoCとデータをもってくる、というところ以外全部やる、というスタンスで開発業務を行っています。
今回は、Flask App Builderでコンテンツマネジメントシステムとメタデータマネジメントシステムをさくっと作っておいたら、諸々あとから役立った話をしていきます。
コンテンツマネジメントシステムとは、WEBテストで利用する一部のコンテンツを管理をする社内用システムになります。メタデータマネジメントシステムとは、データ分析基盤のテーブル情報やカラム情報を管理するシステムになります。
まずは、それらシステムの土台となっているFlask App Builderの説明をしていきます。
Flask App Builderの概要
Flask App Builderは、Flask製のCRUDアプリケーションをさくっと作れるオープンソースです。
Flask App Builderのドキュメントはこちらです。インターフェースは、こんな感じです。

この画像は、リポジトリ内にあるサンプルの一つです。コードはここにあります。
上記のサンプル以外にも、それぞれのユースケースごとの機能が実装されたサンプルコードはここにあります。
Flask App Builderって何ができるのかを理解するには、下記のREADMEを読めば概要を理解できるかと思います。

下記コマンドでさくっと試してみることができます。 わかりにくい方は、こちらのyoutubeの解説動画をおすすめします。
(venv)$ pip install flask-appbuilder (venv)$ flask fab create-app Your new app name: first_app Your engine type, SQLAlchemy or MongoEngine [SQLAlchemy]: Downloaded the skeleton app, good coding! (venv)$ cd first_app (venv)$ export FLASK_APP=app (venv)$ flask fab create-admin Username [admin]: User first name [admin]: User last name [user]: Email [admin@fab.org]: Password: Repeat for confirmation: (venv)$ flask run
データのCRUD、検索処理、ユーザーの認証、権限管理のようなフルスクラッチで実装すると手間がかかる機能はデフォルトで用意されており、UIも見やすい状態になっています。
このFlask App Builderをカスタマイズして、コンテンツマネジメントシステムとメタデータマネジメントシステムの開発からインフラ設計・構築までを一人でさっと作ってみてどのように役に立っているのかを書いていきます。
まずは、コンテンツマネジメントシステムです。
コンテンツマネジメントシステムの概要
作ったものは、こちらです。 コンテンツ情報が一覧できる画面の写真です。他にももっと閲覧できる画面は、あります。

最初は、Google Kubernetes Engine(GKE)の1クラスターまるごと使っておりましたが、インフラコスト的に贅沢すぎましたので現在は、他のアプリケーションもデプロイされているGKEクラスターの社内用ツールのnamespaceを切ってそのnamespace内のpodにデプロイしています。
既に機能が揃っているのでさっとモックを作って見せながら要件をヒアリングしつつ、開発していきました。
他チームからデータや機能の要望があれば、改善を都度行っています。
コンテンツのマスターデータ以外にもWEBテスト機能に必要なデータへのCRUDができるようになっています。
では、コンテンツマネジメントシステムを作って何が嬉しかったか、という話をします。
コンテンツマネジメントシステムをつかった課題解決
コンテンツマネジメントシステムをつかった課題解決は、以下です。
課題
- 生徒が解く問題のマスター情報を別のチームがエクセルで管理しており、最新の状態の中身を確認するのに手間だった。
解決
- 一通りのWEB上で問題マスターデータに対してCRUD、検索、フィルター、並び替え、ファイルアップロードなどの機能を追加することで、Excelファイルの散在やコミュニケーションコストや日頃の調査やデバック工数を減らすことができた。
開発工数
オープンソースなのでアプリケーション自体は、無料.
アプリケーション実装に2, 3人日、インフラ構築に2週間ぐらい。
その他役立ったこと
- QA実施の際にQAチームにデータ確認をしてもらうのに役立った。
- WEBテスト機能の開発者がデバックするや仕様確認する際に役立った。
本来の調査やデバックならば、エンジニアが踏み台サーバーにはいってそこからmysqlコマンド叩いて確認してなどの作業が必要ですが、このコンテンツマネジメントシステムのおかげで、さくっとテストデータを入れての確認などがしやすくなりました。
現在では、運用保守の状態で必要に応じて機能を追加していくというような状態です。 今後は、エンジニアバックグラウンドのない方でも利用しやすいようなUIにより改善していければと思います。
次に、メタデータマネジメントシステムのほうをみていきます。
メタデータマネジメントシステムの概要
作ったものは、こちらです。 テーブル名やカラム名は、BigQueryのAPIを叩いてデータ分析基盤から自動連携しています。Cloud Runにデプロイして利用しています。
各テーブルの役割情報やカラム情報などは、自分達で記入していきます。

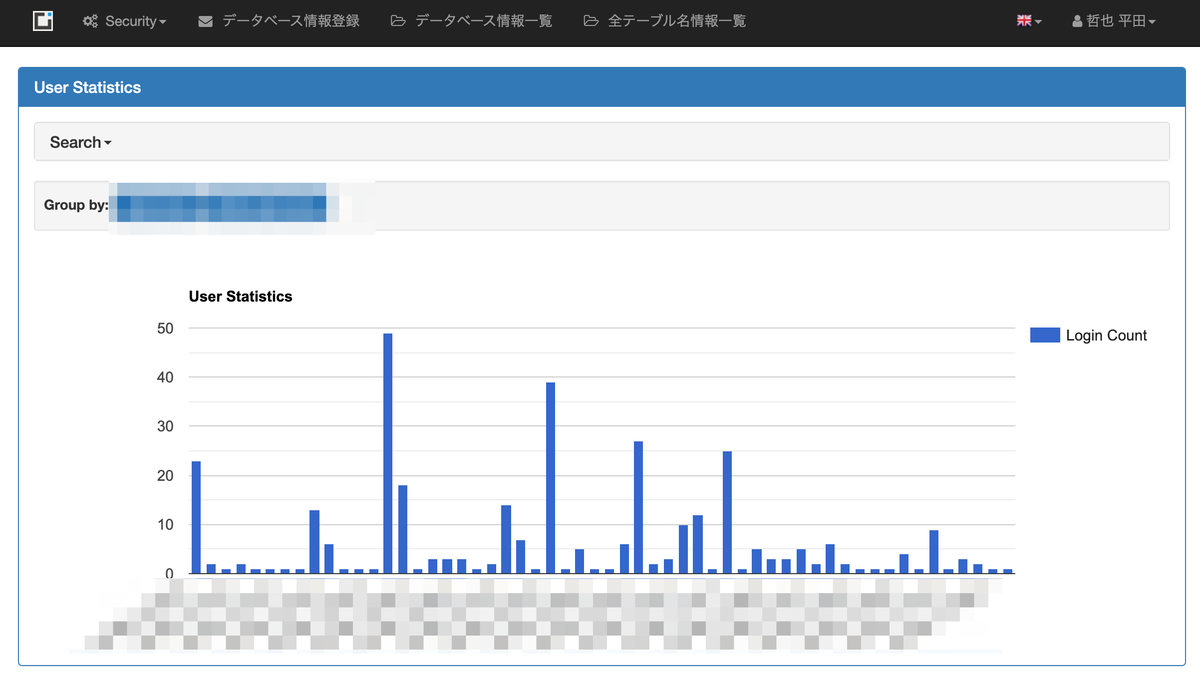
ログイン数などの統計情報もいい感じにカスタマイズしやすいコードになっています。 しかし、Redashなどのダッシュボードで見てしまうため、あまりつかっていません。
メタデータマネジメントシステムをつかった課題解決
コンテンツマネジメントシステムをつかった課題解決は、以下です。
課題
- データ分析基盤を開発する前にそもそもの現状のRDBのテーブル・カラム情報が整理されていなかったので、一人で調べたり、各機能の担当者に話しを聞いて情報をかき集めてエクセルにまとめていました。ただただ、それがつらかった。
解決
- データ分析基盤との自動連携を実装することで自分でテーブル名やカラム名やデータ型から記入する必要はなくなりました。検索性やユーザビリティは、あがりました。
開発工数
オープンソースなのでアプリケーション自体は、無料.
アプリケーション実装に2, 3人日、インフラ構築に2週間ぐらい。
その他役立ったこと
担当以外のデータをデータ分析基盤でみるときや、ダッシュボード作成の際のクエリを書く時にどんなテーブル情報やカラム情報があって、どんな意味があるのかを理解するのに役立つようになった。
そもそも、どんなデータがあるのかわからないという人にとって理解の手助けになった。
テーブル情報やカラム情報は、都度入力していく必要があります。
その施策として、もくもく会を開催したり、チームの定例で10分だけもくもくと手を動かす時間をもうけていきました。
進め方は、meetのブレイクアウトセッションを利用して3,4人のグループに分けて、お互に情報をかけ集めながらやっていきます。
9人でもくもく記入していくと10分で大体一つのデータマートの50%ぐらいのテーブル情報とカラム情報は、記入しきることができます。
このチームでは、3つのデータウェアハウス含めたデータセットのテーブル情報とカラム情報を埋めていきました。一つのデータセットあたり20 - 30ぐらいのテーブルがあります。
これら全て埋めるのに、大体10分のもくもく会を5,6回ほどやると必要なテーブル情報とカラム情報をうめることができました。
エクセルに私一人で記入している時は、カラム情報まで記入できず、なおかつ2つのデータセットのテーブル情報まで記入するのが限界でした。
まとめ
アプリケーション実装よりもインフラ構築の方が工数がかかっています。
これは、当時の私のGKEとCloud Runの仕様の知識不足も影響しているかと思いますが、全体としても早く安く作れたCRUDアプリケーションなのではないかと思います。
また、世の中には、既製のCMSやメタデータマネジメントシステムのOSSは多くあるかと思いますが、機能が多すぎるとか、クリティカルな制約があったりするものです。必要最低限の機能をさくっと安く作るには、こういったフレームワークは最適です。
FlaskのみでWEBアプリケーションを開発してみたいという方は、2022年1月24日発売の「Python FlaskによるWebアプリ開発入門 物体検知アプリ&機械学習APIの作り方 」という私が執筆した書籍の一読をおすすめします。
また、Classiでは、Pythonエンジニア募集中です。ご興味ある方は、下記のリンクからの応募をお待ちしております。