みなさん、こんにちはこんばんは。Classiの基盤バックエンドチームでプロダクトや機能を越えてサーバサイドを中心に困り事を手広く解決する仕事をしている![]() id:aerealです。
id:aerealです。
今回の記事ではClassiのパフォーマンス改善のため取り組んでいるdronと呼ばれるクラウドネイティブなcron代替 (Cloud Native Cron Alternative) の開発について、運用を見据えてどのような考慮を重ねたのかを紹介します。
背景と課題
dronの説明をするにあたって、現行の非同期処理システム (以下、現行システム) の用途と抱えている課題について簡単に紹介します。
現行のワークロード
主な用途はサービス内通知の送信です。AppleやGoogleのスマートデバイス向けプッシュ通知サービスへ適切なペイロードを送る仕事が大半です。
個々のジョブが要するコストは小さくとも、同時に大量に要求されるためそれなりに計算機資源を消費するという性質があります。
主な用途は通知と述べましたが、これを単純にat least onceな実行モデルのシステムに載せ変えると二重・三重に通知が送信されえます。 通知はトランザクション処理ほどクリティカルな影響をもたらしませんが、エンドユーザーをインタラプトする機能ですからナイーブな実装は利用者の負担にもなります。
加えて未来の時間に所与のペイロードでジョブを実行するという予約実行の仕組みがあり、これの移植も求められます。
課題
DBにやさしくない
Classiの各種データは中央のRDBMSで管理されており、各コンポーネントが読み書きしています。
Webテストの結果や校務記録などコアとなる機能のデータが集まっており、この中央DBの負荷が上がるとClassiの機能すべてに影響があります。 現行システムはこのサービスの根幹ともいえる中央DBをキューとして利用しています。
しかし、これは望ましい用途ではないと考えられます。
Webアプリケーションにおいてリクエストを受けてレスポンスを返すライフサイクルから外れて非同期で処理を実行するモチベーションは概ねレスポンスタイムの向上を図るという一点に集約されると言ってよいと思います。 しかし、データストアを共有していることから現行システムが中央DBを通じてClassiのサービス全体のパフォーマンス劣化を及ぼしうる状況にありました。
アプリケーションのレコードとJOINするようなこともなく同じDBにキューを用意する必然性は無いので、とにもかくにも中央DBの利用をやめたいところです。
スケールアウトの困難なアーキテクチャ
一般にキューを利用した非同期処理システムでは、実行されるジョブの性質に合わせてスケーラビリティを確保するためキューを分離したり、実行環境をスケールアップ・スケールアウトさせることがパフォーマンス改善の手として挙げられます。
現行システムは前述のように中央のRDBMSを利用しPHPで書かれた独自のデーモンとして実行されています。 排他処理は考慮されていないため、素朴にデーモンの実行数を増やすと競合が起きえます。
さらに悲しいことに実行されるジョブの実装もただ一度 (exactly-once) 実行されることを期待しているため、よしんばPHPのデーモンを改修したとしても数あるジョブの実装をひとつひとつ丁寧に排他制御しなければいけず現実的とはいえません。
方針
exactly-onceマナーでの実行、ジョブの予約の実現など複雑かつワーカーとして複雑な責務は凝集させ、各ジョブの実装 (= 知識) は各チームに担ってもらうことで梃子を効かせつつ分権を狙います。
そのために:
- 各ジョブの実装はプライベートなHTTPエンドポイントとして再実装される
- リクエスト、レスポンスの形式などアプリケーションプロトコル策定は基盤バックエンドチームが主導する
- 再実装は各ジョブのオーナーを持つチームに依頼する
- dronは各ジョブのHTTPエンドポイントを呼び出すところまでを責任境界とする
……とします。
設計
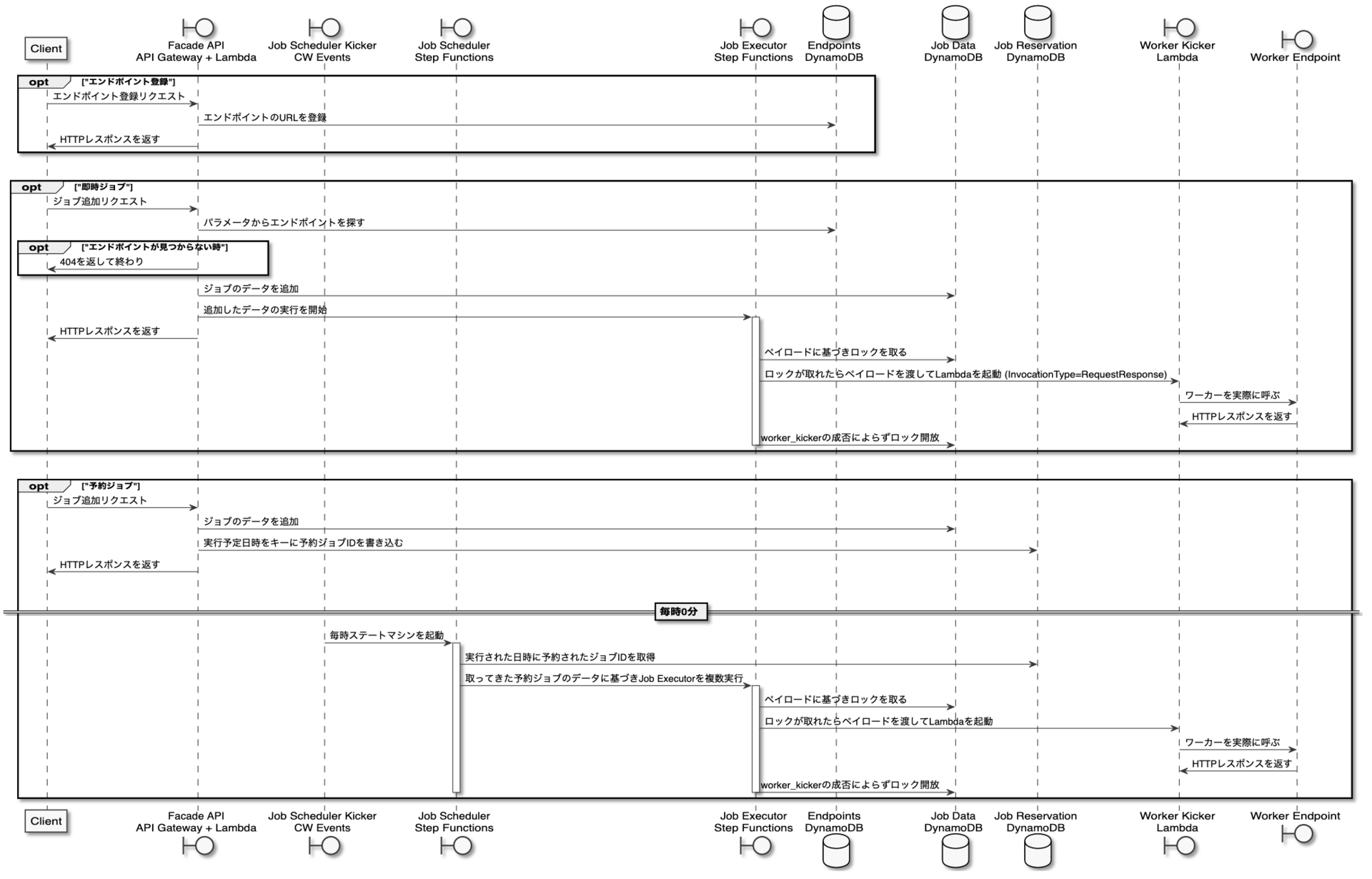
コンポーネント概説
Facade
- クライアントが行える操作をHTTP APIとして提供する
- API Gateway + Lambdaで実装される
Job Executor
- ジョブを実行するStep Functionsのステートマシン
- Lambdaの呼び出しが統合されているだけではなくDynamoDBのGetItem/PutItem/UpdateItemなどの各種API呼び出しがLambdaを起動することなく直接行えるのでコードの削減やレイテンシの点で優位性がある
- 失敗可能性のある処理のリトライや状態遷移を移譲することでアプリケーションを素朴に保てる
- 並列実行に制約はほぼなく、スケーラブルである
Job Scheduler
- CloudWatch Eventsで毎時起動されるStep Functionsのステートマシン
- Job Reservationからジョブ情報を取得、Job Executorを並列に実行する
Endpoint Data
- Worker EndpointのURLを保存するDynamoDBのテーブル
- 一度登録されたURLは変更できない
- 新しいURLを用いる場合は新しいエンドポイントとして登録する
- 過去のある時点のジョブがどのURLへアクセスしえたかを追跡しやすくするため
- ジョブの実行要求ごとに任意のURLを受け取る場合、瑕疵により誤ったURLであってもその妥当性を判断できない
- 事前にURLを登録し、ジョブの実行要求にはエンドポイントの識別子を含めると登録済みかどうかでtypoなどの瑕疵を発見できる
- 将来的にこのテーブルを拡張して最高並列数を持たせたり、URLテンプレートとしてFacadeへの一度の実行要求から複数のURLへジョブを実行できる含みを持たせている
Job Data
- ジョブの情報を保存するDynamoDBのテーブル
- 一度挿入されたらクライアントの操作によって削除・更新はされない
- 不変データとすることで過去の状態を再現する手間がなくなり調査がしやすくなる
- Job Executorによってロックとして機能する実行中フラグと完了時刻は更新される
Job Reservation
- ある日時に実行すべきジョブを保存するDynamoDBのテーブル
- 日時を過ぎても各アイテムは更新や削除されないので、あるジョブが確かにある日時に予約されたかはあらゆる時点から追跡可能
Worker Kicker
- Lambdaとして実装される
- URLとHTTPメソッド、リクエストボディを与えられ適切なタイムアウトを設定してHTTPリクエストをWorker Endpointへ送信、レスポンスを返す
Worker Endpoint
- 各ジョブの実際の処理を行うHTTPエンドポイント
- Endpoint Dataは少なくともひとつのWorkerに対応する
- 各利用者アプリケーションの一部として構築される
- 条件を満たせばClassiが直接管理しないHTTPエンドポイントをWorker Endpointとすることもできる (例: Twitter API)
運用時の考慮事項
追跡・トレーシング
ジョブの追加や実行が成功したか・どのクライアントがどのジョブを追加したかといった情報は顧客の問い合わせに対応したりデバッグを目的としてX-RayによるトレーシングおよびStep Functionsによる実行ログに保存されるのでそれを利用できます。
ジョブの追加および実行の完全な追跡はX-Rayの制限により最大30日間に、ジョブの実行の部分的な追跡はStep Functionsの制限により最大90日間に制限されます。
- 短期間ではX-RayでFacade→Job Executorの実行開始まで追跡できる
- 短〜中期ではStep Functionsの実行履歴を辿るとJob Executor→Worker KickerおよびJob Scheduler→Job Executorの実行が追跡できる
- 2020/9/14のアップデートでStep FunctionsもX-RayをサポートするようになったのでJob Executor/Job Schedulerの実行も含めて追跡可能
命名
cronの次を目指す ('c'.succ + 'ron') ということでdronと名付けました。
これまでに述べてきた既存システムの置き換えではcronの定期実行という仕組みは必須ではなくまた現時点で実装もされていないにも関わらずcron alternativeを標榜しているわけは exactly-onceで処理を実行するシステムの難しさ に着目し、cronはこれを部分的にせよ解決していたことに由来します。
cronのexactly-once実現はSPOFを持ち込むことと表裏一体ですので、クラウドサービスを活用し可用性を高めつつ実現することで既存のワークロードからの容易さが社内の利用者に伝わることも願っています。
おわりに
システムのパフォーマンス改善という大きなミッションのためには、時には個々のコンポーネントの置き換えといった大胆な手段をとる必要があります。
こうした大胆な判断をとる意義と必要性を理解した上で、ニューカマーの私にプロジェクトのリードを任せてもらえる、攻めと守りにメリハリのついた健全な技術決定のできる組織になっていると実感し楽しく思っています。
サービスの改善という大目標への道程はまだ始まったばかりですし、もっと言えばマイルストーンはあっても終わりなどないのですが、それでも大事な一歩に少なからず貢献できたと自負しています。
付録: Cloud Native Cron Alternativeとわたし
元々筆者はqronというAWS上で上記に似たシステムを構築するためのAWS CDKライブラリを開発・公開しています。
ちょうどClassiに参加してどんなプロジェクトを担当しようかという話をする中で、この記事で挙げた課題・プロジェクトが候補に上がっており当初はレビュアーとして「こういった解決策があるよ」と提案する立場でしたが、先行してライブラリを作っていたこともあり主担当となりました。
qronについてYAPC Kyoto 2020で発表予定でしたが、COVID-19の拡大に伴いイベントの開催が見送られたこともあってこのアイデアについて紹介する機会が見つけられず残念に思っていたこともあり、実運用へ投入した事例を紹介できるならという思いもありました。
本当に偶然が重なった結果ですが数奇な巡り合わせを感じずにはいられません。 よって命名時にもqronをインスパイアした名前にしました。