こんにちは、Classi株式会社 プロダクト開発部所属のid:kiryuanzu です!
2020年4月から新卒のエンジニアとして入社し、現在は学習記録でサーバーサイドエンジニアの業務を担当しています。
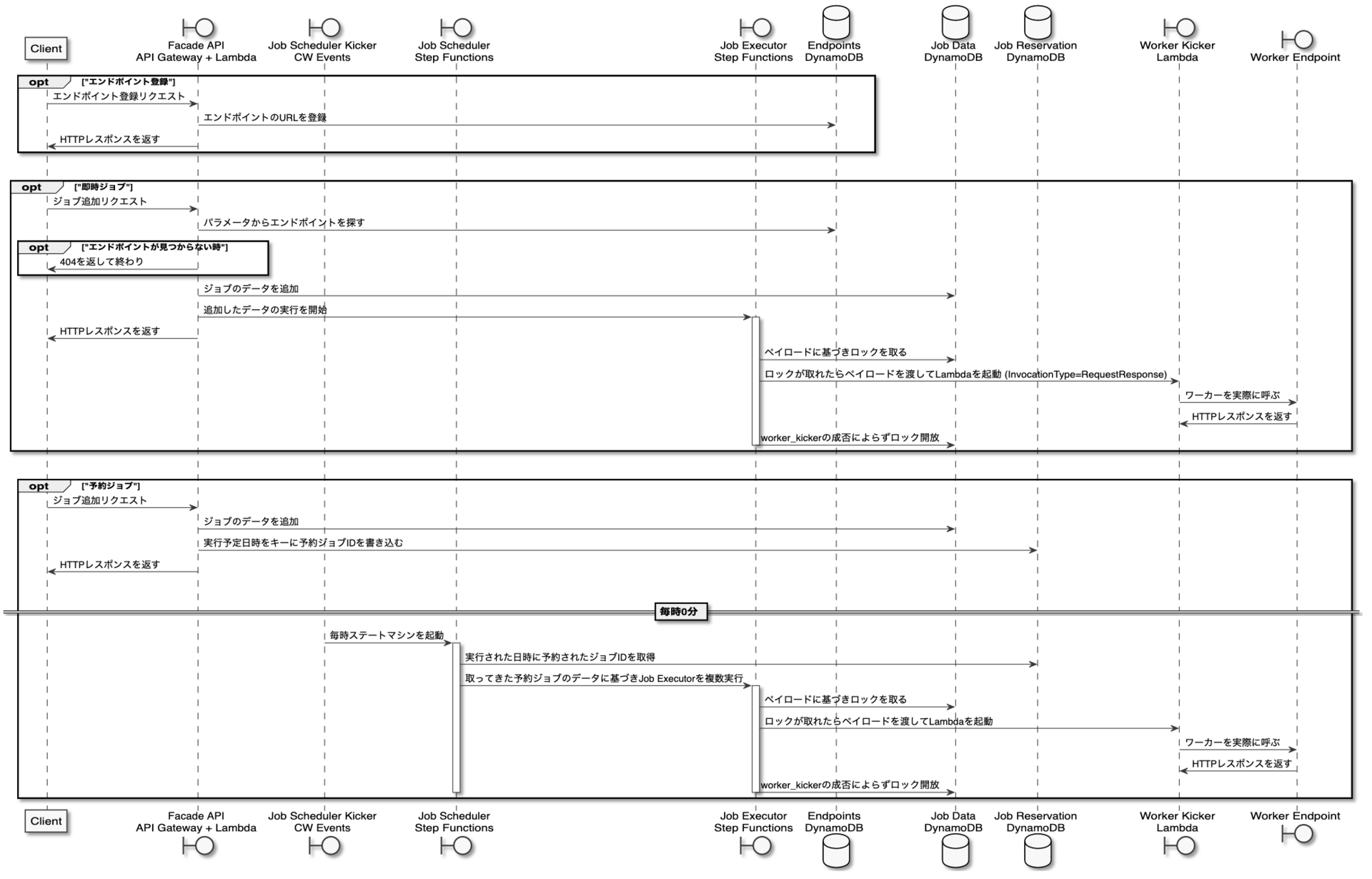
今回の記事では、Classiの中の部活動の一つとして運用されている「CTF café
」、そしてその部活の課外活動の一環として参加したHardening 2020のイベントの体験記を紹介します。
CTF café はじめました!
ご存知かもしれませんが、CTFとは「Capture The Flag(キャプチャー・ザ・フラッグ)」の略であり、フラグ(Flag)と呼ばれる隠された答えをセキュリティの知恵を駆使して探し出す競技のことです。競技の中身は、クイズ形式のものや実際にサーバを攻撃・防衛する形式といったものがあり多岐にわたります。
Classiの中にはセキュリティやCTFに興味を持つ方が多くいます。
過去のClassiのWantedlyの記事では、活動に関わっている野溝が女性限定のCTF大会「4-Girls CTF 2019」というイベントに参加した際の体験記を書いています。
www.wantedly.com
筆者自身も、入社前にこの記事を読んで「CTF、やったことないけど楽しそうだな〜、会社の中に詳しい人がいるのならちょっと触ってみようかな……!」と興味が湧き始めました。
そして、Twitterや入社後に作った分報チャンネルでCTF興味がある旨を呟いた後日のことです。「社内の有志を集めて一緒にCTFの問題を解いてみませんか!」と誘われ、CTFを始めるようになりました。
そのような流れを経て、社内のSlackに「#ctf」というチャンネルを立て毎週火曜のお昼にSlack callに集まる部活が誕生しました!その部活をCTF caféと呼んでいます。

CTF caféの主な活動内容はオープンに公開されているCTFの問題(ksnctf, cpawctf, picoCTFなど)を協力して解き合ったり、定期的に開催されるセキュリティ関連のイベントに参加するといったものです。
ずっとガチガチにやるといったものではなく、問題を解きつつ近況を交えた雑談を挟んだり、古のインターネット話に花を咲かせることも時折あります。
筆者自身、完全初心者ということもあり最初はどう解くか分からない問題も多かったですが、CTF経験者のメンバーからのアドバイスによって、次第に頻繁に出てくる暗号の解き方を理解したり、「こういう時はstringsコマンドでバイナリファイルの中身を見たらいいんだ!」とすぐに気付くようになりました。問題で用意されるパケットキャプチャを覗きたい時はWireSharkを使うのも慣れてきました。
まだまだ初心者ではありますが、「この時にはこのツール/コマンドを使おう」と頭の中で繋がるようになってきました。
また、OSINT(簡単に説明するとネットに公開された情報だけで目的の情報を特定する形式の問題です)をやるようになってからは迂闊に店名や特徴的な建物が写り込んだ地理写真をあげるのはできるだけ気をつけようと思うようになりました。
活動記録に関しては、メンバーの一人がesaの中でセンスあるタイトル付きで毎回まとめて社内に共有しています。
Hardening 2020 に行ってみた!
筆者がCTF caféに参加するようになって1ヶ月ほど経ったある日、部活メンバーから「Hardening 2020というイベントに参加してみませんか」と声をかけられました。
Hardeningとは、簡単に要約すると外部からの攻撃を防御しつつ、運用を任されたサービスの売り上げを最大化する競技のことです。このイベント自体はCTFに分類されるものではありませんが、CTF同様にセキュリティの知識を駆使して競技に挑むといった点では同様であると言えます。 公式サイトの説明では以下のように書かれています。
Hardening競技会は、基本的にチームに託されたウェブサイト(例えばEコマースサイト)を、ビジネス目的を踏まえ、降りかかるあらゆる障害や攻撃に対して、考えうる手だてを尽くしてセキュリティ対応を実施しつつ、ビジネス成果が最大化するよう調整する力を競うものです。
その説明だけを聞いた時点では、「どうやって守っていけばいいの……!そもそもどんな攻撃が飛んでくるんだ……!?」とまだまだ未知の領域でしたが、チームを組むことになった方々や過去にHardeningに参加したClassiの社内メンバーによって講習会が開催され、どのような準備や戦略立てが必要であるかを知ることができました。
準備期間は1ヶ月で、応募者の中から10人構成のチームを組んで準備を進め、本番当日は上記で説明したように出されたお題に応じてサービスを運用し、攻撃から守り抜くことになります。
ちなみに、大会応募時には個人応募とチーム応募(3人まで)を選ぶことができ筆者はチーム応募で部活メンバーの2人と一緒に参加しました。
他の7人のメンバーの方は、Classiと似たようなWeb関係の出身の方もいれば生活インフラのシステムや病院のシステムを運用されている方、学生とエンジニアの二足のわらじをやっている方など多種多様なメンバーで構成されており、普段交流できないような方々と協力し合いながら学ぶことができ、セキュリティ関係のコミュニティの空気感についても知ることができました。
チーム名はISUCONジェネレーターを使って「おにぎりまみれ」という名前に決まりました。アイスブレイクとして好きなおにぎりの具を言い合ったり、チームメンバーの一人かつClassi社員の野溝がロゴを作成しました。

結果は……?
チームの方々と一緒に大会本番に向けて準備を続け、ついに当日を迎えました。
本番中のインシデントでは、ショップのトップページが何者かに改ざんされ当時流行していたドラマの画像が貼られたindex.htmlに変えられてしまったり……(チームメンバーの1人かつClassi社員の高田が30分で直して事なきを得ました)。
運用の手続きに必要なWEBページがDNSエラーで到達不能になり、Discordで運営の方に購入サイトのIPアドレスを教えてもらい危機を回避するなどがありました。
技術的なイベント以外にも、発生したインシデントについて親会社の役員に説明を求められたという設定で、怖い役員に扮した運営メンバーの方から呼び出されるといったこともありました。どうやらこの公開呼び出しイベントは毎年お馴染みのようです。
そして結果は……! 筆者も含めたClassi社員の3名が所属するチーム「おにぎりまみれ」が総合優勝しました!!!!!!

まさかの初参加でこのような素敵な体験をさせていただくことができ、本当に感謝しています。後日行われた振り返りの場でもこのような結果が残せたのは、チームワーク重視で動き続けたことがよかったのではないかとチーム内で意見が一致しました。
具体的には、チーム内のメンバーの誰かが困っている時はすぐにチャットで反応したり声かけを行うなど、リアクションを徹底して行い、誰かの発言が虚空に消えそうな雰囲気を感じた場合はすぐに反応をして不安を取り除けるよう動くようにしたことで、お互いの役割を認識し合いながら作業内容を把握して進めていくことができたのではないかと思います。
まだまだ「旅」は続く
CTF caféがきっかけとなりこのような大変面白い体験ができました。しかし、これで終わらず部活メンバーと共にセキュリティに関する知見を深め合いながら問題を解き進めたり、他の面白そうなセキュリティ関連の大会に参加して経験を積んでいきたいです!
Classiでは、このような面白い課外活動が活発に行われております。 この記事を読んで「自分もこのようなコミュニティに関わってみたい!」と感じた方の応募をいつでもお待ちしています!