こんにちは。開発本部プロダクト開発部学習チームでエンジニアをしています、id:tkdn 武田です。
弊社もスポンサーとして後援していた JSConfJP へ参加してきましたので、今日はそのレポートと特に気になったセッションを中心に感想をまとめていきます。
なお、この記事は Classi developers Advent Calendar 2021 の 3 日目の記事です。
JSConfJP について
本カンファレンスは本年が 2 回目の開催です。前身となっている Node 学園祭が、各国で開催する JSConf といった冠のついた日本版 JSConf といった趣きのイベントとなり、2019 年から生まれ変わっています。私個人としては前身のイベントには 2017, 2018 に参加、JSConfJP 2019 に参加しているので、今回のオンラインイベント含めて 4 回目の参加になります。
今年は SpatialChat の会場が用意されスポンサーブースの設置もありましたが、自身の性格もあいまって話しかけるのは難しかったなという印象でした。Twitter でのハッシュタグつきの投稿は盛り上がっており、当日は私も見ていたセッションについて積極的にコメントしていました。
アーカイブが残っていますので見逃したセッションのある方や当日参加できなかった方は以下からご覧になれます。
ソフトウェアをめぐる話
最初に取り上げるのは Classi フロントエンドのプロジェクトに入っているツールの 1 つでもある Prettier、そのメンテナーである sosukesuzuki さんのセッション。そして、今年会社化され Deno Deploy など分散ホスティングサービスも展開する Deno、その中の人でもある kt3k さんによるセッションです。
エコシステムを支える OSS の努力や課題
sosukesuzuki さんのセッションで語られた印象的な部分は Prettier がエコシステムでどういった立ち位置にあるのかといったものです。
下記は TC39 Proposal の策定プロセスから、各ツールチェインに新しい構文がどう反映されどのパーサにどういった役割があるか発表のスライドから引用したものですが、かなり複雑な図に感じますね。
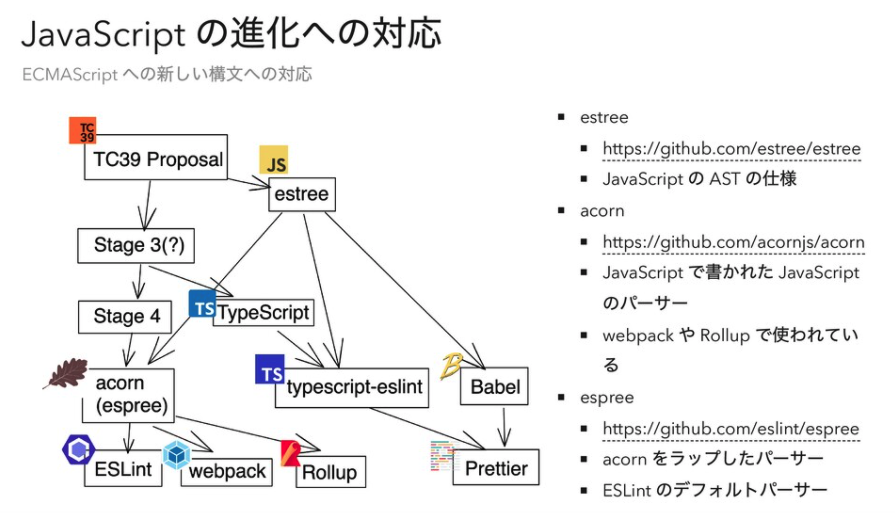
セッション後の質疑応答では sosukesuzuki さんの個人的な見解ではあるものの、「今の JavaScript を支えるツールチェインは歪な形をしている」という話が出ていました。
Rome などのオールインワンの OSS が代替ツールとして出てくることについても、各ツールが独自にもつパーサによる解析を統一すればコンピュータリソースの削減もできるし計算効率も高くなり無駄がなくなる、順当な流れなのではないだろうかというお話でした。このくだりは本当にいいお話だったので、執筆の際にも何度か繰り返し再生しています。
OSS のメンテナーが感じている所感をほかのソフトウェア(webpack, Babel)のメンテナーのインタビューも交えながらリアルな声を聞けたのは、OSS の実際というところを垣間見る良い機会となりました。
しばしば話題になる以下のようなメンテナー不足の issue を見るたびにユーザーとして心を痛める反面、ソフトウェアにできることは何なのかを考え、還元していかなければとあらためて感じました。
- We need regualr CRA maintainer · Issue #11180 · facebook/create-react-app
- Project dead? · Issue #3930 · axios/axios ※ 執筆時点ではすでに解決済みです
法人化しユーザー・ソフトウェアを増やそうとするプラットフォーム
スライドリンク:Deno のこれまでとこれから JSConf JP 2021
一方で Deno は法人化しており Deno Deploy をベータで公開しながらも GA した際には収益化も検討しているプラットフォームでありカンパニーです。すでに GitHub においての採用が発表されていますし、つい先ごろ発表された Slack の新しい開発プラットフォームのバックエンドとしても採用されています。
kt3k さんから語られたのは Deno のこれまでの歩みとこれからについてでした。Deno は Node.js の作者でもあった Ryan Dahl が Node.js をデザインした際の後悔を元に、それらを克服したプロジェクトとして立ち上げたものです。

Ryan Dahl の後悔はいくつかあるようなのですが、その中でも実行環境におけるセキュリティサンドボックスのモデルについてをここでは取り上げています。
Node.js は実行時の許可なくファイルの読み書き、ネットワークアクセスなどが自由にできますが、Deno では実行時のパーミッションオプション(--allow-read, --allow-net など)を有効にしないとできません。実行時に明示的に権限を与える必要があるのです。これによって高いセキュリティを期待できる点も採用事例が増えてきた理由でしょう。
ですが、セッションでも語られたように 10 月に大きなロードマップの追加がありました。それが Node.js 互換モードです。おい待てよと、Node.js との差別化のために生まれたはずなのに迎合しているのでは、といった意見がコミュニティや社内から湧き上がったそうです。
Node.js 互換といった 180 度の転換が Ryan Dahl 本人からの発案であることも驚きですし社内では反対意見が多かったということも驚きですが、背景としては Deno をインストールするユーザー数の今のところ横ばいであるのも起因しているようです(質疑応答より)。
スライドでも登場しますが、卵が先か鶏が先かのプラットフォームの問題にも触れ、ユーザーが少なければそのプラットフォームで動くソフトウェアは増えず、ソフトウェアが少なければそのプラットフォームを使うユーザーが増えないという Deno が今直面している状況と、今回の Node.js 互換モードが紐付けられています。
こういった Deno の裏側を知ることができたのも興味深くおもしろい話でした。
アクセシブルな Web のためのフロントエンド開発
最後に取り上げるのは yamanoku さんによる「アクセシブルなフロントエンド開発のこれまでとこれから」というセッションです。
この発表の前に yamanoku さんは「HTML だけで UI を作る限界、あるいは無理なくユースケースと向き合っていくためには」と題した発表も別の場でされており、そちらも強く私の印象に残った内容でした。

今回はその限界を示しながらもっとアクセシブルであるためには、といった内容が主題になっています。Web, HTML そして HTTP の父であるティム・バーナーズ・リーの引用も交えながら、アクセシブルとは普遍的に障害の有無に関係なく誰も使えることが本質だという力強い言葉に、Web が好きなフロントエンド開発者として冒頭から胸が打たれました。
そして肝心のアクセシビリティに関してですが、セッションの内容には恥ずかしながら自身にとっては初めて知ることが多く反省も多くありました。
たとえば SPA におけるルーティングの遷移後、スクリーンリーダーでの読み上げ時にページが変わったことを検知できないというデモを見て、初めて WAI-ARIA aria-live について認識できました。Angular では下記のような実装イメージで画面タイトルの変更をスクリーンリーダーを扱うユーザーに通知できます。
<div *ngIf="pageTitle$ | async as pageTitle" aria-live="polite"> {{ pageTitle }} </div>
発表のあとに調べると Angular CDK では LiveAnnouncer といったモジュールも提供されておりこちらもうまく活用できそうです。
@Component({/* ... */}) export class MyComponent { // ... constructor(liveAnnouncer: LiveAnnouncer) { liveAnnouncer.announce(this.pageTitle)); } }
ほかにも Custom Elements に直接 role 属性を与えずに JavaScript から内部的に与えるという Accessibility Object Model といった案もコミュニティから出ていると知りました。利用時に都度必要な属性を利用者が付与せず、Custom Elements の実装者が内部的に担保できるというのは納得の提案ではあります。
スクリーンリーダーへの対応というと身構えそうですが、スライドでも出てきたようにキーボード操作のタブフォーカスでアクセスが可能かといった小さなところからでも始められるはずです。UI が知覚可能であるかどうかということを気にかけるだけでも、考慮できるポイントが増えそうだと感じました。
JSConfJP オンライン参加を終えて
Node 学園祭から参加し続け、今回は初めてのオンライン開催でしたが、オフラインと変わりなく JSConfJP を楽しむことができました。カンファレンスでは新たに気付くことも多く、今回は特に OSS やソフトウェアが成立するためのプラットフォームの話から、我々開発者はどうコミュニティに貢献するのかといったことをあらためて考えさせられる良い機会を得ることができました。
まだまだ数は少ないですが社内メンバーの登壇やコミットメントという形でも成果を発揮しながら、Classi は今後もコミュニティを通じて OSS への還元を目的に、利用技術のカンファレンスやイベントに支援していく予定です。
またカンファレンスで得た知識、特に今回はアクセシブルな UI を実装していくことなどを現場のプロダクト開発に持ち帰りたいと思います。
JSConfJP 運営の皆さま、ご苦労さまでした!