こんにちは、データAI部でPythonエンジニアをしている平田(@JesseTetsuya)です。普段は、PoCとデータをもってくる、というところ以外全部やる、というスタンスで開発業務を行っています。
今回は、PyCon JP 2021で登壇してきましたのでそちらの登壇ブログになります。 いままで一人で世界中のPyConで毎年登壇してきました。今年は、三年目になります。
いままでの登壇歴
PyCon US 2019 at US(オフライン開催) Lighting Talk:"How to Transform Research Oriented Code into Machine Learning APIs w/ Python"
PyCon TW 2019 at Taiwan(オフライン開催) Talk: "How to Transform Research Oriented Code into Machine Learning APIs with Python"
PyCon JP 2019 at Japan(オフライン開催) Poster: "Hybrid Keyword Extraction Automated by Python With Cloud Speech To Text API and Video API"
PyCon HK 2020 at 香港(オンライン開催) Talk: "How to Transform Research Oriented Code into Machine Learning APIs w/ Python"
PyCon JP 2020 at 日本(オンライン開催) Talk: "How to Transform Research Oriented Code into Machine Learning APIs with Python"
PyCon Taiwan 2020 at 台湾(オンラインとオフライン開催) Tutorial: "How to develop ML APIs with Python from Online Learning Dataset"
PyCon APAC 2020 at アジア太平洋(オンライン開催) Panel Discussion: "ML/DL on Edge Computing"
PyData Global 2020 at 世界(オンライン開催) Talk: "Transformation from Research Oriented Code into Machine Learning APIs with Python"
また、Classiは去年に引き続き、今年もシルバースポンサーをしています!
さらに、データAI部にPythonエンジニアが一人増え、今年からやっと一緒に参加してくれる仲間が増えたので、記事を書いていきます。
今回の発表内容についてと工藤さんの初参加レポートを当記事に書いていきます。
発表内容
今年、発表したタイトルは、"Flask 2.0 vs FastAPI in REST API developments" です。
FlaskとFastAPIは、Pythonのマイクロフレームワークを選ぶ際に、よく選択肢として上がってくるマイクロフレームワークのうちの2つになります。
この2つを比較するのは、人によっては挑発的なタイトルだと思わせてしまうかもしれません。
Flaskが良いという内容であれば、FastAPIユーザを攻撃することに、FastAPIが良いという内容になれば、Flaskユーザを攻撃することなりかねない内容です。
ただ、結論から言うと、両方ともいいとこがありますよ、という内容です。 内容が全て英語なので、日本語で軽く補足していきます。
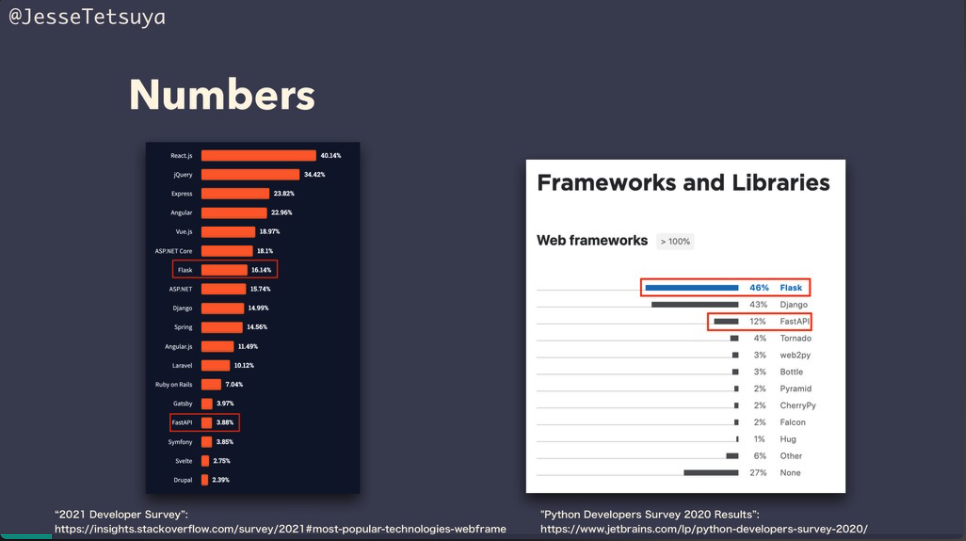
JetBrains社の調査結果によると、PythonフレームワークのなかでFlaskが一番人気のようです。

下記、4つのクライテリアを設定して、それぞれの軸で評価していきます。
- フレームワークの機能性や拡張性
- パフォーマンス(スピードと安定性)
- REST API設計の柔軟性
- 学習コスト
ここで、Flask 2.0としているのは、今年の5月にメジャーversion upがあり、大きく変更点がありましたので、比較するFlask のversionを2.0としています。詳細は、こちらのClassi開発者ブログ記事のFlask 2.0.xのアップデート項目紹介をご覧ください。
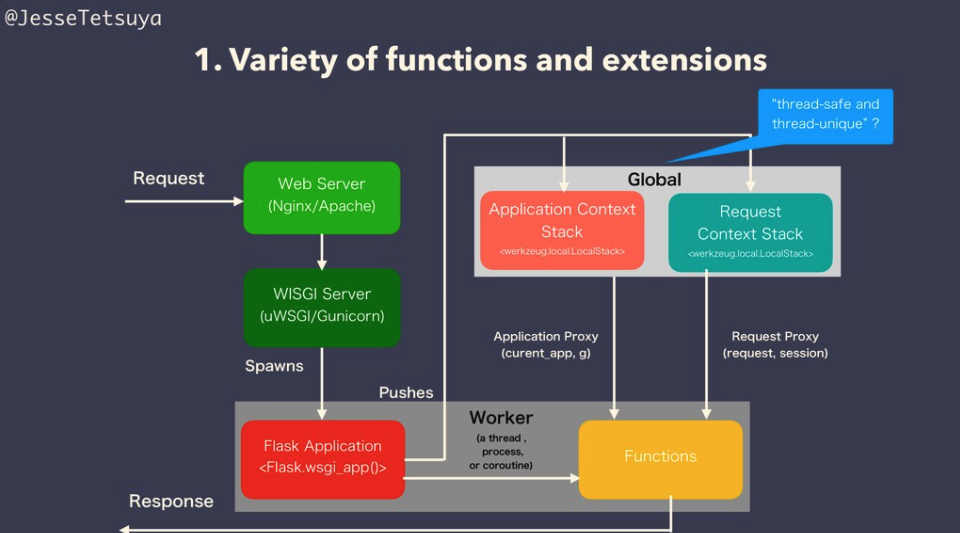
フレームワークの機能性や拡張性という点において、FlaskもFastAPIでの大きさ差分はなく、あるとしたらFlaskのApplication ContextとRequest Contextの実装は、ユニークなのではないか、また、拡張性においてFlaskの方が多くの拡張モジュールがあるという意味で、Flaskのほうが多少フレームワークの機能性や拡張性があるという結論にしました。

パフォーマンス(スピードと安定性) については、私が軽く実施した負荷試験や他の性能計測サイトでの確認によるとFastAPIの方が良いという結論です。これは、アーキテクチャや負荷試験の仕方によって異なってくる場合があります。負荷試験をどのコードをつかって、どう実施したかについては、スライドの中身を御覧ください。
REST API設計の柔軟性は、ディレクトリ構成の柔軟性という意味です。FlaskもFastAPIも似たようなディレクトリ構成が可能なので、どちらが良いかという判断はできない、と結論になりました。

ここで学習コストをはかる指標として、書き方の難しさ、書き方を知りやすいかという指標をおきました。
書き方の難しさの点において、両方とも簡潔な書き方ができるフレームワークです。また、Flask2.0とFastAPIの間では、書き方に殆ど差分がないと言ってもいいでしょう。
書き方の知りやすさに関しては、Flaskが2010年に作られ、FastAPIが2018年に作られたということもあり、Flaskの方が学習リソースは多いです。
そのため、Flaskの方が学びやすいだろうと結論づけました。

総評として、Flaskの方が少し強みがあるのかなという結論になりました。これは、FastAPIの歴史がまだ浅いのが影響しているかと思います。
また、FastAPIは、未だにPEPになっていないASGI準拠のフレームワークです。
PythonコミュニティでのコンセンサスがとれているPEPにあるか否かは、Pythonコミュニティでの認知度や信頼度、開発スピードにも影響しているかと思います。
また、近年の技術進化の早さにより、どれだけ早くキャッチアップできるか、キャッチアップしやすいか、という観点が技術選択において、大事です。
フレームワークの機能性や拡張性は、パッケージをインストールするか、モジュールを実装すれば済む話ですし、パフォーマンス(スピードと安定性)は、フレームワーク以外の部分、例えば、CPythonでかいたり、ロードバランサーを置くなり、インスタンスサイズをあげるなどの部分で補うことができます。
そのため、上記4つのクライテリアの中では、学習コストが一番大事な要素になると思います。

最後にFlaskとFastAPIへの今後の期待を込めてのスライドを追加しました。FlaskとFastAPIの日本語でかかれた学習リソースが未だに少ないです。
学習リソースの量が増えれば、とくに書籍が増えると、学習者が増え、コミュニティのサイズも大きくなっていくと思います。
とは言いつつ、自分からアクションをしていかないと気がすみません。
そこで、来年度、Flaskについての書籍を出版します!楽しみにしていてください!
今回の発表や当記事をきっかけにFlaskとFastAPIへの興味を持っていただき、学習者が増え、みんなで学び合いができたら良いなと思っています。
PyCon JP 2021に初参加したミニレポート(工藤さん)
こんにちは、データAI部でPythonエンジニアをしている工藤( id: irisu-inwl )です。
今回はPyCon JP 2021に初めて参加したので、個人的に興味深かった講演について紹介します!
Vertex Pipelines ではじめるサーバーレス機械学習パイプライン
Sugiyama Asei さんの Google Cloud の Vertex Pipeline を使った機械学習パイプライン構築についての講演です。 公演詳細リンク
Vertex Pipelines は Kubeflow Pipelines SDK, TensorFlow Extended を利用したパイプライン実行できる ML パイプラインサービスです。
元々、Google Cloud には AI Platform Pipeline というKubeflow Pipelinesのマネージドサービスがありましたが、Vertex AI という AI Platform が GA となり、サーバーレスな MLパイプラインサービスとして Vertex Pipeline がリリースされました。
発表で下記のことを知ることができました。
fullstack Kubeflowと比較して、Vertex Pipelines の良いところとして、管理が楽 (Data Scientist には k8s を管理しながらは辛い)
実際に弊社でもアプリケーション基盤として GKE の standard mode を運用していますが、バージョン管理戦略や、ノードの管理、スケーリングの設定など、諸々を考えなくては運用が難しいので、運用負荷が高いことは容易に想像ができました。
Kubeflow Pipelines を使った パイプライン構築の例
コンポーネント実行順序のプラクティス
Kubeflow上での GPU 利用などの計算リソースを設定する方法
弊社のデータAI部でも Vertex AI の様々な機能を MLプロダクト開発に活用していこうと考えているので、非常に参考となりました。
実装で知るasyncio -イベントループの正体とは-
REI SUYAMAさんのasyncioの生成処理部分を解説した講演です。 公演詳細リンク
こちらの講演に興味を持った理由は以下です。
データAI部で平田さんが FastAPI と Flask の性能比較などしていることもあり、asyncio は FastAPI を使っていく上で、理解を避けて通れません。
データAI部の勉強会で CPython Internals の Multiprocessing の章を読んでいたので、内部実装が気になったためです。
講演では、asyncio の具体的な処理の解説と、理解する上で必要な CPython の coroutine について解説されてます。
まず、generator の特徴を解説し、その次にcoroutine と generator の類似について説明することで coroutine を説明するアプローチがされてました。特にバイトコードでの処理の比較があったのは非常に理解しやすかったです。
Pythonでのコードの例と、実際に asyncio の内部挙動をシークエンス図として示しており、 EventLoop が Task を作ってから send で実行し、Future に結果を格納するまでの流れが詳細に分かりました。
参加してみた所感
今回、PyCon JP に初めて参加しましたが、最近の動向を知ることや、様々な Python Engineer の方の知見を得るいい機会となりました。
PyCon JP の会自体が円滑に運営されており、discordのチャットやボイスチャンネルの雰囲気も良く、楽しく参加することができました。
今回はオンラインでの参加となりましたが、是非今後はオンサイトでの参加や、スピーカーとしての登壇をしていきたいと思っております!
最後に、Pythonエンジニアの募集を引き続き行っています。
下記URLを確認していただきカジュアル面談の応募お待ちしています!