こんにちは。新卒 1 年目エンジニアのすずまさです。
先日、弊社 VPoT の id:nkgt_chkonk が執筆した process-book の勉強会を修了しました。
process-book は *nix系のシステムにおけるプロセスやシグナルなどについて説明することを目的に書かれました。「プロセスとかよくわかってないからちゃんと知りたいな」みたいなひとたちが想定読者です。
参加する前は UNIX の基礎的な知識も乏しかった私ですが、学びがたくさんあり毎回楽しく参加できたので紹介します。
開催の経緯
Slack でシェルスクリプトの話題で盛り上がったのをきっかけに、プロセスモデルの重要性が話に挙がり、流れでその日のうちに「process-book 読もう会」が誕生しました。

進め方は下記の通りです。
- 日時: 毎週木曜日 15:00〜15:30
- 週に 1 章ペースで進める
- 初めに各章ごと担当者を決めておき、担当者は esa に内容をまとめ、当日司会をする
- 参加者は各自手を動かして予習しておく
- 疑問や気付いたことがあれば会の中で発言する
印象的だった章
4 章のファイルディスクリプタの話が印象的でした。
- OS は、プロセスから「ファイルを開いてね」というシステムコールを受け取ると、実際にファイルを開きます。
- OS は、その開いたファイルを表す「番号札」を作成します。
- OS は、その番号札をプロセスに対して返します。
この「番号札」のことを、「ファイルディスクリプタ」と呼びます
Ruby を使い、実際にファイルディスクリプタを出力してみると "5" が出力されます。
また、標準入力のファイルディスクリプタは 0、標準出力は 1、標準エラー出力は 2 ということを学びます。
ここで、「では 3 と 4 は何を指しているのか?」という疑問が生まれました。
会の中では「lsof コマンドを使うと調べられるよ!」とだけアドバイスを頂けたので、勉強会後に実際に実行してみると、下記のような結果が得られました。
# fd.rb file = File.open("nyan.txt","w") puts file.fileno puts $$ while(1) sleep end
$ ruby fd.rb & $ 5 # ファイルディスクリプタ 8300 # プロセスID $ lsof -p 8300 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME ~~~ 省略 ~~~ ruby 8300 ssm-user 0u CHR 136,1 0t0 4 /dev/pts/1 ruby 8300 ssm-user 1u CHR 136,1 0t0 4 /dev/pts/1 ruby 8300 ssm-user 2u CHR 136,1 0t0 4 /dev/pts/1 ruby 8300 ssm-user 3u a_inode 0,14 0 13 [eventfd] ruby 8300 ssm-user 4u a_inode 0,14 0 13 [eventfd] ruby 8300 ssm-user 5w REG 259,1 0 259116 /home/ssm-user/004/nyan.txt
ここで、FD (ファイルディスクリプタ) の 3u と 4u を見れば良さそうだと分かりますが、これだけ見ても実際に何が行われているのかは分かりません。
そこで、man eventfd を実行してみると、下記のような文章が得られます。
eventfd() creates an "eventfd object" that can be used as an event wait/notify mechanism by user-space applications, and by the kernel to notify user-space applications of events.
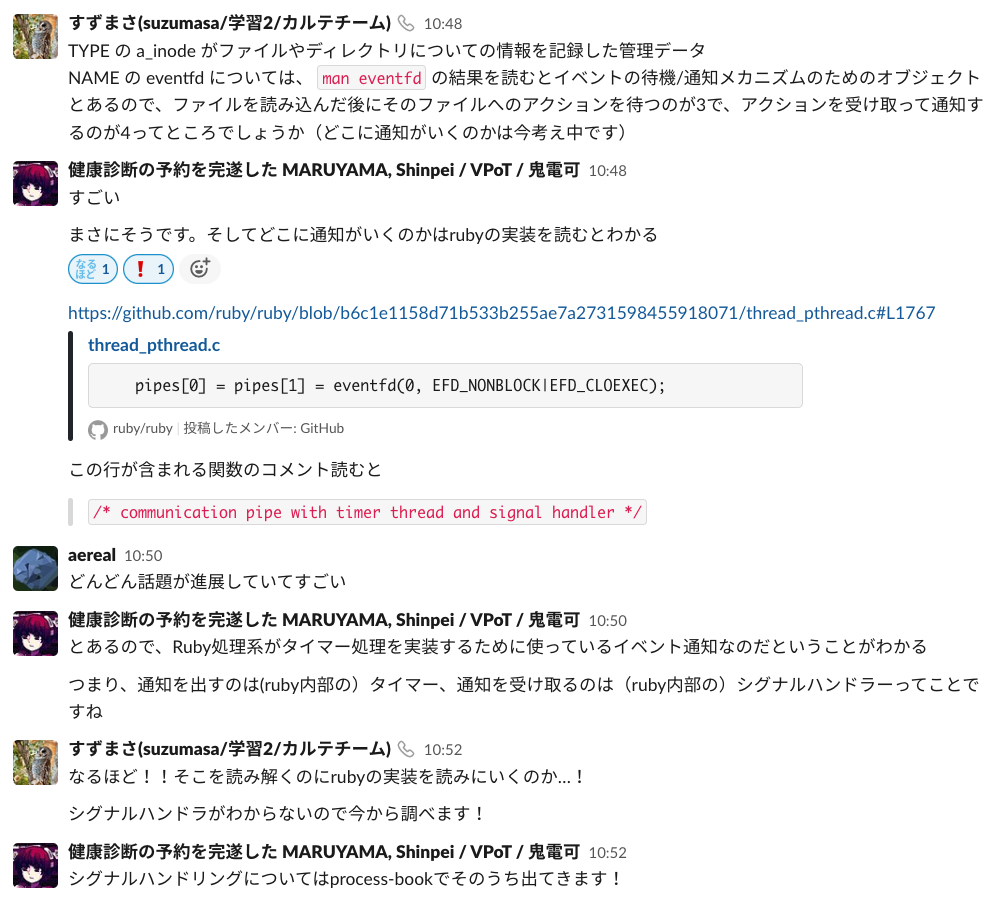
この文章から、ファイルを読み込んだ後にそのファイルへのアクションを待つのが 3 で、アクションを受け取って通知するのが 4 だと予想できます。
では、その通知はどこに向けてされているのでしょうか?
Ruby の実装を読んでみましょう。
pipes[0] = pipes[1] = eventfd(0, EFD_NONBLOCK|EFD_CLOEXEC);
https://github.com/ruby/ruby/blob/b6c1e1158d71b533b255ae7a2731598455918071/thread_pthread.c#L1767
この文が呼び出されているコメントを読むと、"communication pipe with timer thread and signal handler" と書かれています。 つまり、通知を出しているのは Ruby 内部のタイマーで、通知を受け取っているのはシグナルハンドラーなのだと分かります。
上記は勉強会後に Slack で質問したことで得られた学びなのですが、「ファイルディスクリプタの 3 と 4 が何を指しているのか知りたい」という当初のシンプルな疑問から Ruby の実装を読むことになるとは思わなかったので感動しました。
1 つの疑問から新たに疑問が生まれ、それがどんどん解消されていくのが気持ち良くて楽しかったです。
参加して嬉しかったこと
質問が歓迎される
本勉強会では先生役のような詳しい人が何人かおり、その方たちに出てきた疑問をよくぶつけていたのですが、たまに「良い疑問ですね」と言われるのが嬉しくてかなりモチベーションになりました。
疑問をぶつけるとその場で解消され、解消されなかったとしても考察が広がるので、疑問を持てば持つほど楽しい勉強会でした。
man を読むようになった
man はman コマンド名でそのコマンドのマニュアルを読むことができるコマンドです。
正直今まで man コマンドを使ってマニュアルを読んだことがほとんどなかったのですが、今回の勉強会を経て man をしっかり読むようになりました。
man を読むことで疑問が解決できたり、新しく洞察が得られたりすることが多く、改めて公式ドキュメントの重要さを認識しました。
ボリュームがちょうど良かった
文字数が多くないので予習が苦ではありませんでした。 余裕があったため、章の内容通りに手を動かすだけでなく、毎回気になった箇所をじっくり調べることもできました。
感想
最初の方は分からないことが多すぎて議論についていくので精一杯でしたが、途中からわかることが増えて様々な疑問が浮かび、そこから一気に楽しい勉強会になりました。
他の方の鋭い疑問に驚く場面も多く、一人でやっていたらここまで学びは多くなかったと思うので、本当に参加して良かったです。
開催してくださった先輩やサポートしてくださった方々には感謝の気持ちでいっぱいです。
今回学んだ内容を活かした発展的な内容もやりたいという話が挙がっているので、次回があれば是非また参加したいと思います!