こんにちは、データプラットフォームチームの鳥山(@to_lz1)です。
Classiでは、2019年ごろからデータ基盤に「ソクラテス」の愛称をつけて運用を続けています。初期の構成は2021年に書かれたエントリ*1にも詳しいですが、数年の間に進化したことも増えてきました。
大きな変化の一例として、最近、私たちのチームではdbt*2を導入してジョブ間の依存管理やメタデータの管理を改善しました。
本記事ではこの取り組みをピックアップして紹介します。また、進化したソクラテスの構成図をアップデートするとともに、Classiデータプラットフォームチームの最新版の雰囲気もお伝えできればと思います。
dbt移行前の構成
正直に言ってしまえばdbt移行前の構成でも運用が崩壊するほどには困っていなかったのですが、個人的には大きく以下の2点に課題を感じていました。
- ジョブ間の依存管理がつらい
- メタデータの管理がつらい
以下、それぞれ説明します。
ジョブ間の依存管理がつらい
dbt導入以前のジョブはCloud Composer(Airflow)が提供するOperator*3が担っており、1クエリ1タスクになるような構成でした。
ところで、データマートのテーブルは材料となるテーブルがあって初めて作れます。そして材料となるテーブルもまた加工テーブルである可能性があるので、必然的にクエリ間には依存関係が生じます。移行前はこうしたクエリの依存関係を以下のようなyamlの設定ファイルに書いて対応していました。
- task_id: update_classi_dwh.students file_path: queries/dwh/students.sql destination_table: classi_dwh.students table_type: table write_disposition: WRITE_TRUNCATE dependent_tasks: - update_classi_dwh.schools - update_classi_dwh.users
生徒のdwhは、学校のテーブルとユーザーのテーブルに依存して作られる...納得感が高いですね。
dependent_tasksが比較的自明であるうちは良いのですが、これだとテーブル数が増えてきたときや、処理の中心に新たにテーブルを加えたくなったときに認知コストが非常に高いという問題があります。また、このアプローチでは依存タスクの記述漏れがあったときにも気づくことができません。依存関係を目で追ってそれを慎重にyamlファイルに反映していくことが作業時間を圧迫するようになってしまっては本末転倒というものです。
メタデータの管理がつらい
Classiでは、過去在籍していたメンバーがFlask-AppBuilder*4を用いたメタデータ管理システムを作ってくれていました。
このシステムの功績は大きく、特にデータエンジニアでないメンバーが定義を書き込めるようになっていたことで、関係各所から「このテーブルのこのカラムはどういう意味?」といった重要なメタデータを収集することに成功しました。
しかしながら、独自管理Webシステムの限界もまたあります。
例えば、新たなテーブルをデータ基盤に追加したときにその説明をわざわざ書きに行くのか?というと微妙なところです。手間が勝ってしまうので充足率がいまいち高くならない、という課題もまた残っていました。
この点、dbtではmodelの定義ファイルにそもそもテーブルごと、カラムごとのdescriptionを記述できます。「新たなテーブルを追加するときに、そのPull Requestには同時にメタデータも書いてある」という世界なら、「リリース後にメタデータを書きに行く」という作業そのものが不要です。データ基盤の改善を加速させていくためにも、早くこのような構図に移行したい、というモチベーションがありました。
過去との差分と、移行への機運
実は、過去Classiではdbtに移行しようとしたものの諸々の状況を考慮して取りやめたことがあります。
当時との状況の差分としては、以下のようなものがあると思います。
周辺ツールのエコシステムが整った
「dbtならyamlにdescriptionを書ける」と言っても、全テーブルの全カラムに手でdescriptionを付けていくのは実際のところかなり大変です。しかし、 dbt-osmosis のようなツールが出てきたことでこうした作業を効率化できるようになり、dbtのエコシステムに乗るメリットが大きくなってきました。
dbt-osmosisについてはこちらのブログなどが詳しいため、詳細については割愛します。
dbt-osmosisを利用して、なるべくコストを抑えつつ効率的にメタデータ管理を行なう - yasuhisa's blog
エンジニア以外のメンバーがPull Requestを出すことが減った
Classiではかつて、データサイエンティストやビジネス側のメンバーもデータ基盤のリポジトリにPull Request(以下、PR)を出す、という光景が当たり前でした。しかしながら、エンジニアリングを熟知したメンバーばかりではなかったので、これが逆に新たなツールを導入することをためらわせる要因にもなっていました。
時が経ち、ビジネスメンバーからエンジニア陣へのドメイン知識の移転(≒dwh化)はある程度果たされたので、継続的にPRを出し続ける必要は無くなってきました。これにより、「学習コストが隣のチームの人達には厳しすぎるかも...」といった心配をする必要がなくなり、自分たちの裁量で新しいツールをより気軽に導入できるようになりました。*5
移行に際しての工夫点
上に述べたような状況を踏まえて、2023年末から2024年初頭にかけてdbtへの移行をやり切りました。移行においては以下のようなことを意識しました。
少しずつ行う
ビッグバンリリースではトラブル発生時の影響が計り知れないので、独立してリリース可能な範囲を切り分け、比較的難易度・複雑度が低いと思われるものから以下の順に移行を進めていきました。
- 社内でしか使わない、独立した小さいワークフロー群
- 社内でしか使わないが、データ基盤のコアとなるワークフロー
- エンドユーザーにも使われる、プロダクト機能に関連するワークフロー
また、社内データ基盤のコアを移行する際にはテーブルの棚卸しも実施しました。少数ですが、「移行せずとも2024年度になれば必然的に要らなくなる」といったテーブルも混じっていたため、こうしたテーブルはあえてdbt移行せず古いバージョンのまま残しました。
これにより、後述する差分確認の手間を減らしつつ、利用者がいなくなってから削除することでユーザーに影響を与えることなく古い処理系を一掃することに成功しました。
後から思ったことですが、このように徐々に移行を進めていくアプローチは、Martin Fowlerが提案したstrangler figパターンに近いものがあるかもしれません。
strangler fig パターンを実装してモノリシックなアプリケーションからマイクロサービスに移行するプロセスは、変換、共存、排除の 3 つのステップで構成されています。
strangler fig パターン - AWS 規範ガイダンス
差分確認を怠らない、でも楽にやる
さて、dbtへの移行ですが、クエリを移動して、必要な部分を書き換えて、全体のジョブが成功したら終わり...でしょうか?
いえ、それでは不十分なケースもあります。例えば処理は成功しているのにテーブルには差分が出ている...ということになると大変ですよね。データ基盤ではデータの正確性が重要な要素の一つですから、移行前後のデータの比較をしておけると安全です。
BigQueryでは、こうしたテーブル同士の比較はExcept句を用いた集合演算で実現できます。
Query syntax | BigQuery | Google Cloud
移行前のテーブルbefore、移行後のテーブルafterがあるとして、以下のようなクエリが結果を返さなければ、2つのテーブルは完全に一致していると言えるわけです。
select * from before except distinct select * from after
こうしたクエリの作業を全テーブルで行うのは大変なので、小さなシェルスクリプトを書いてチーム内に共有し、簡単に差分比較を行えるようにしました。実際はもう少し機能を追加しましたが、概ね以下のようなものです。
#!/bin/bash # 比較元と比較先のテーブル名の組をCSVで作っておく TARGET_FILE="./target.csv" if [[ ! -f "$TARGET_FILE" ]]; then echo "File $TARGET_FILE not found!" exit 1 fi project_id=$1 tables_with_diff=() while IFS=, read -r compare base; do table_id_compare="${project_id}.${compare}" table_id_base="${project_id}.${base}" echo "Checking diff between ${table_id_compare} and ${table_id_base}." SELECT_MINUS_QUERY="\ (select '${table_id_compare}' as table_name, * from ${table_id_compare} except distinct select '${table_id_compare}' as table_name, * from ${table_id_base} limit 3)\ union all\ (select '${table_id_base}' as table_name, * from ${table_id_base} except distinct select '${table_id_base}' as table_name, * from ${table_id_compare} limit 3)" result_rows_with_headers=$(bq query -q --nouse_legacy_sql "$SELECT_MINUS_QUERY" | tee /dev/tty | wc -l) if [[ $result_rows_with_headers -gt 0 ]]; then tables_with_diff+=("${table_id_compare} and ${table_id_base}") fi done < $TARGET_FILE if [[ ${#tables_with_diff[@]} -gt 0 ]]; then echo "Tables with diff:" for table in "${tables_with_diff[@]}"; do echo "- ${table}" done exit 1 else echo "No diff found with $(wc -l < $TARGET_FILE) table pairs✨" fi
スクリプトを流した結果をrevieweeがPRに貼ることで、差分がないことについてはわざわざSQLをレビューしなくても分かります。これにより、それ以外の場所、例えばmacroの設計や命名、過去遡及時の冪等性の確保といったより重要な部分のコードレビューに集中できました。
反省点
以上述べたようにスクリプト等も駆使しつつ大きなトラブルなくdbt移行を終えたのですが、一部テーブルでCluster列*6の設定を忘れたまま移行してしまい、移行直後のクエリコストが急騰するという問題が発生しました。
幸い数日で気づけたので影響は小さかったのですが、皆さまに置かれましてはデータだけでなくメタデータ(descriptionに限らず、labelやpartition設定等も含む広義のメタデータ)もきちんと移植できているか、という観点も忘れられませんようご注意下さい。
ソクラテスの現在地
dbt移行などいくつかの刷新を経て、Classiのデータ基盤は今このようなアーキテクチャになっています。

ジョブの依存関係の管理の他、メタデータの提供もdbtの機能を使って実現できたのが大きな改善点です。
dbtをDockerizeされたジョブとして動かすようにしたため、model間の依存関係がComposer上では見れなくなってしまったのですが、dbt Docsを確認すればmodelごとのlineageグラフを可視化出来るので、大きな問題は出ていません。
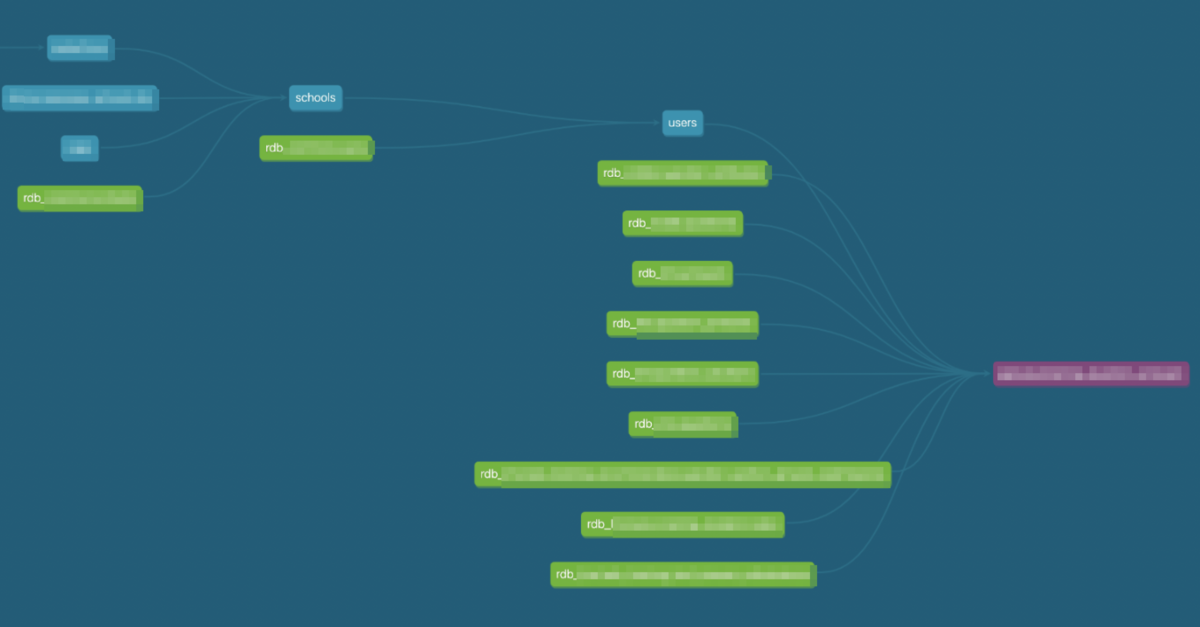
先述した独自のメタデータ管理システムについても、クローズする前にすべてのデータをCloud SQLから吸い上げ、dbtのConfigに反映する対応を行いました。これにより、これまでメンバーが書いてくれた有益な情報をdbt Docs上に集約でき、データカタログの利便性も向上したと思います。
dbt移行の他に大きい差分としては、ログのBigQueryへの連携を毎時のバッチで動かすようになりました。
実はそれまではAWS Athenaをベースに作られていたログ分析基盤を使っていました。それはそれで便利な点もあったのですが、AWS内に独自にホストされたRedashがメンテナンス不能になっていたり、BigQuery上のデータともjoinできないなど、負の側面も強くなっていました。このため、2024年初頭にBigQueryへの連携パイプラインを構築し、旧システムも先日すべて無事に削除しました。
これらの取り組みによって、RDBデータはdaily、ログデータはhourlyで、それぞれBigQuery(a.k.a. ソクラテス)に安定して供給される状態が実現できました。
今後の展望
Data Catalog as a Code
dbtによってメタデータの管理性は向上しましたが、今後のメンテナンスが本当に円滑に行われるか、という点では更なる工夫が必要です。メンテナンス業務にあたっては、descriptionをあちらにもこちらにも書かないといけない...といった二重管理を避けることが何より重要ではないでしょうか。
これに関しては、RDBのテーブルと加工テーブルのメタデータをそれぞれ1回記述すれば他のすべてのコンポーネントに反映されるような仕組みを構築中です。目指したい構成は以下のようなものです。

順を追って説明します。
- データエンジニアおよびデータ供給者(プロダクトチームのエンジニア)は、RDBのテーブルをBigQueryに連携するときにdescriptionを記述する
- bq load時に、書かれたテーブル定義を参照して実テーブルにメタデータが付与される
- dbt-source-importerによって、sourceテーブルのメタデータがymlに反映される
- dbt-osmosisによって、sourceテーブルのメタデータは加工テーブルのymlにも反映される
- データエンジニア及びデータ利用者は、集計カラムなど加工テーブル独自の列があればそのdescriptionを記述する
- dbt build時に、ymlを参照して実テーブルにメタデータが付与される
- dbt docs serveの定期的な実行により、最新のデータカタログが社内に公開される
dbt-source-importerが初出なので説明しておきますと、これはBigQueryの実テーブルからsourceの設定ファイルの内容を生成してくれるCLIツールです*7。sourceのメンテナンスについて、dbt-helperやdbt-osmosisなど公式に近いツール群ではかゆいところに手が届かないケースがあるのですが、こちらは必要な機能が軽量にまとまっているため重宝しています。
余談ながら、先日機能追加のPRを送った際も迅速に対応いただき、非常にありがたかったです。この場を借りて感謝いたします!
上図のような世界が実現できれば、人間の手が必要な作業は「RDBのテーブルのメタデータの記述」「加工テーブルのメタデータの記述」だけになります。あとは各ツール群が実テーブルにも設定ファイルにも、データカタログにも最新の状態を反映してくれるという算段で、細かい部分を調整しつつこうした自動化を進めています。
ここに書き切れないさまざまなこと
本記事では技術的なトピックに焦点を当てて来ましたが、ここに書き切れない施策もたくさん行っています。例えば、私のチームが属するプラットフォーム部では、より事業成果に直結する取り組みを増やすべく、全チームそれぞれがプロダクトのKPIに直接コミットするような目標を盛り込みました。
これに伴い、データプラットフォームチームでは例えば、
- KPIのモニタリングと提言
- 施策の立案と効果検証
- ユーザー向け調査の設問設計
などビジネス的にチャレンジングな活動にも取り組み始めています。KPIをタイムリーに測定するためのデータマートの整備もアナリティクスエンジニアリングの一環ですから、当然我々の守備範囲です。データとビジネスが重なることは何でもやる。という覚悟で引き続きやっていきます。
We are hiring!
dbt移行プロジェクトの詳細と、データプラットフォームチームの近況についてお話してきました。何でもやる、とは言いましたが、現在データプラットフォームチームは4月からリーダーとなった筆者を含め3名しかおらず、やりたいことに対しては手が足りていない状況です。
データエンジニアリングもアナリティクスエンジニアリングも存分に行える環境が揃いつつあるため、Classiのデータプラットフォームチームに興味をお持ち頂いた方はカジュアル面談や面接にエントリー頂ければ嬉しいです!
*1:https://tech.classi.jp/entry/2021/05/31/120000
*3:https://airflow.apache.org/docs/apache-airflow-providers-google/stable/operators/cloud/bigquery.html
*4:https://flask-appbuilder.readthedocs.io/en/latest/
*5:かつてPRを出してくれていたメンバーはSQLやBIツールを使って今もガンガン力を発揮してくれていますし、dbt Docsへのフィードバックやデータ項目の追加依頼をもらうことで間接的にデータ整備にも貢献してくれています。PRが頻繁に飛んでくる文化も素敵とは思うのですが、形を変えて引き続き良い関係が築けているため、自分はこの変化はポジティブに捉えています。
*6:https://cloud.google.com/bigquery/docs/clustered-tables?hl=ja