開発本部の onigra です。今回の記事は、Classiのアプリケーション実行環境をAmazon EC2からECSに移行しているお話をします。
この記事では「Ruby on RailsのWebアプリケーションをECSに移行する上での技術的なトピック」ではなく、「なぜClassiはEC2からECSに移行する必要があるのか」「どのように移行を進めているのか」についてをお話します。
なお、この記事は Classi developers Advent Calendar 2021 11日目の記事です。昨日は データプラットフォームチームの滑川さんによる Cloud Composer 2へのupgradeでどハマりした話 でした。
なぜEC2からECSに移行する必要があったのか
私が入社した当初、Classiは前述の通りAmazon EC2で稼働していました。それ自体に問題は無いのですが、サーバのプロビジョニングとデプロイが遅く、不安定という課題を抱えていました。
また、普段プロダクトを開発・運用しているチームの中にデプロイ、インフラの知識や、既存の仕組みを把握しているメンバーが少なく、プロビジョニングやデプロイに何か問題があると、私のような組織横断的な技術課題に取り組むメンバーが対応にあたることが多々ありました。
近年、書籍 『LeanとDevOpsの科学』 でも語られているように、変更のリードタイムとデプロイの頻度は組織のパフォーマンスに大きく関わる要素であり、今後価値提供のスピードを上げていくにあたって大きな障害となるため、なんとか全社的に解決したい課題だと考えていました。
そんな中、 2020年の春に不正アクセスが発生し、その後サービスの高負荷によるアクセス障害が続く状態 になりました。
日々対応に追われる中、次から次へとサーバのチューニングやアプリケーションの修正をデプロイしなければならない状況で、デプロイとプロビジョニングの仕組みが大きなボトルネックになっていることをこの時に改めて痛感します。
また、今後Classiがセキュリティ面でもパフォーマンス面でもお客様からの信頼を回復しなければならない中で、今のままの仕組みではとても改善のスピードを上げることはできません。
この時、現状のEC2へのプロビジョニング、デプロイの仕組みを全て捨て、ECSに移行して1から作り直そうという決断をしました。
移行の戦略
最初の移行の成否が今後を左右する
この時点で現場は日々の対応で疲弊していました。そんな状況を打破し、サービスの改善にポジティブな勢いを生むためには、移行する1つめのリポジトリの成果に大きく左右されると考え、確実に成功させる必要がありました。
そのため、最初の移行対象はコンテナ化の難易度が比較的低いWeb APIの機能のみを提供しているリポジトリを選択することにしました。
運用ができるメンバーを増やしつつ、移行する
私はコンテナを普段から利用し、ECSを触った経験があったので、移行する上で知識の問題は無いのですが、コンテナの運用に慣れていないメンバーへレクチャーをしきれるのかという懸念がありました。
また、Classiには多くのリポジトリがあり、それらを1つ1つ移行していたらかなりの期間がかかってしまうことは容易に想像できます。そのため、移行作業と移行のレクチャーができる人員をスケールさせる戦略を練る必要がありました。
そのため、移行作業は以下のようにメンバーを巻き込みつつ、最終的に自分以外のメンバーがレクチャーを行えるような状態を目指して進めることにしました。
- 自分で検証環境の移行を行い、必要な作業を把握する
- 本番環境の移行に取り掛かる際に一緒に作業するメンバーをアサインし、ペア作業でレクチャーしながら移行を完了させる
- 次のリポジトリに取り掛かる際に新たにメンバーをアサインし、2のメンバーにレクチャーしてもらう
- 以降、自分はサポート役に回る
また、本番リリース直前は必ず一緒に「あと何をすればリリースできるのか」を確認する機会を設けました。 いわゆるリリーススプリントに臨むための準備です。以下のような内容を確認、レクチャーし、リリースマネジメントを行いました。
- Datadogの使い方
- Sentryの使い方
- 依存するアプリケーションの考慮
- 本番ネットワーク疎通確認と方法の確認
- リリースの手段と、ロールバックの仕方
- 関係各所への連絡と期待値調整
- EC2環境と、不要になるAWSのリソースを削除する手順
これらを移行作業の中でレクチャーすることによって、今後リポジトリ担当者が自立してサービスを運用できる状態になることを目指しました。移行の完了は終わりではありません、始まりなのです。
結果
2021年12月現在、13のリポジトリが移行完了しています。
何が移行を勢いづけたのか
フォロワーシップを強く発揮するメンバーの存在
同じ課題感を感じていたメンバーがフォロワーシップを発揮し、2つめのリポジトリの移行作業を早々に完了させ、以降に続くメンバーの勧誘とレクチャーを積極的に行ってくれました。
そのおかげで予定よりも早く自分がサポーターの役割に移行でき、アプリケーション固有の問題や例外的な対応をメインに行うことによって、移行プロセスのボトルネックの解消にフォーカスすることができました。
成長機会を貪欲に掴みにきた新卒、若手メンバーの存在
移行するメンバーを募集した際、新卒や若手が積極的に手をあげて参加してくれました。私自身、キャリアの中でもトップレベルに困難な状況と感じていたのに、それを成長機会と捉え、できることをしようとする姿勢には強く勇気づけられました。
会社の危機的な状況に対し、若いメンバーからサービス改善に繋がるポジティブなムーブメントを起こせたことは、非常に大きな意義があったと思っています。
移行に参加したメンバーの1人である小川さんがECS化について書いた記事も是非ご覧ください。
移行に関わるメンバー同志のコミュニティのようなつながり
私はチャットへのレスポンスが早い方なのですが、移行作業を行うメンバーが集まるチャネルではよりそれを心がけました。未知の作業を行うことに不安を感じているメンバーに対し、何か書き込めばレスポンスが返ってくる安心感を与えたかったからです。結果的にその行動はチャネルが盛り上がることに繋がり、コミュニティのようになりました。
移行セレモニー
社内にポジティブな雰囲気を起こすことと、移行しきったメンバーを称えて成功体験にしてもらうために、移行が完了したら担当したメンバーにオープンチャンネルで移行完了宣言してもらい、スタンプを可能な限りつけて盛大に祝うというセレモニーを必ず行っていました。

その後
運用の知識を身につけたメンバーを触媒に、社内で徐々にサービス運用を改善する動きが浸透していきました。
運用改善を行うWorking Groupの定期開催化
まず、株式会社はてな様で行っている Performance Working Group を自主的に行うチームが現れました。その活動が他のチームに広がり、チームで個別に行うだけではなく、インフラチームが主催で行う組織横断的なPerformance Working Groupも定期開催されるようになりました。
また、定期的にSentryの整理やエラー内容の調査する取り組みも各チームで行われています。アプリケーションやエラー監視ツールはインシデント以前から導入されていたものの、これまではエラーが多すぎたり、使い方がわからないメンバーも多く、放置されがちだった状況から大きく改善されました。
これは、lacolacoさんがSentryについての継続的な活用支援を続けてきてくれたことも大きな後押しであったと感じています。
システムアラート発生時のメンバーのレスポンスが向上した
インシデント以前はシステムアラートの発生に対して、特定のメンバーしか反応しない・できない状態で、反応したメンバーが担当しているチームに「これ大丈夫ですか?」と伝えに行くことも多かったのですが、徐々に反応するメンバーが増えてきて、今では担当チームのメンバーがシステムアラート発生から真っ先に「確認します」と反応することがほとんどになりました。
これにはインフラチームが主体で行っていた、サービスのピークタイムの監視を当番制で行う取り組みが定常化し、インフラチーム以外のメンバーもその当番に参加するようになり、システムアラートへの対応経験を積んだメンバーが徐々に増えていったことも後押しになりました。
今となってはピークタイムの監視当番は、システムアラート対応のオンボーディングの役割も兼ねるようになりました。
インフラに興味を持つメンバーが増えた
移行作業をきっかけにインフラに興味を持ち、自主的にAWSの資格を受験して合格したメンバーも数名います。
AWS 認定 ソリューションアーキテクト - アソシエイト(SAA-C02) 試験に合格したので振り返る
受験費用は会社でサポートしているのですが、最初に受験したメンバーは会社で精算できるということを知らず、たまたまSlackで「この間の試験受かってよかった〜」という発言を見かけて「会社で精算できるから申請してね」と声をかけたこともありました。
また、理解の必要はあるが自分で構築することは少ないAWSのネットワーク(VPC、Subnetなど)について、移行に参加したメンバーが勉強会を開催したいと相談され、一緒に内容を考えてハンズオンを実施したりもしました。
その他
監視についての記事を開発者ブログに執筆してくれるメンバーもいました。
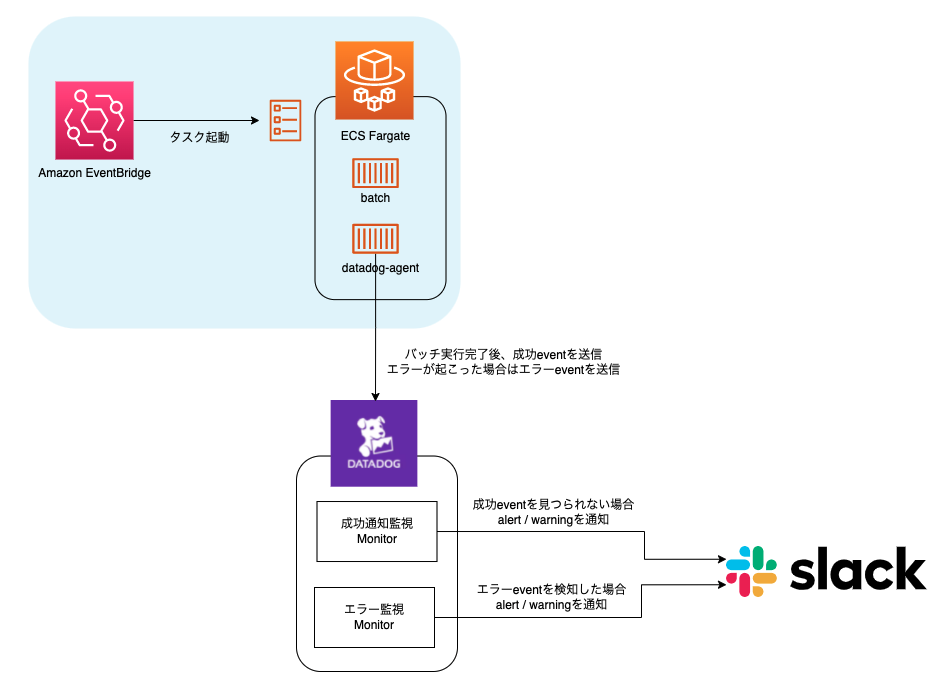
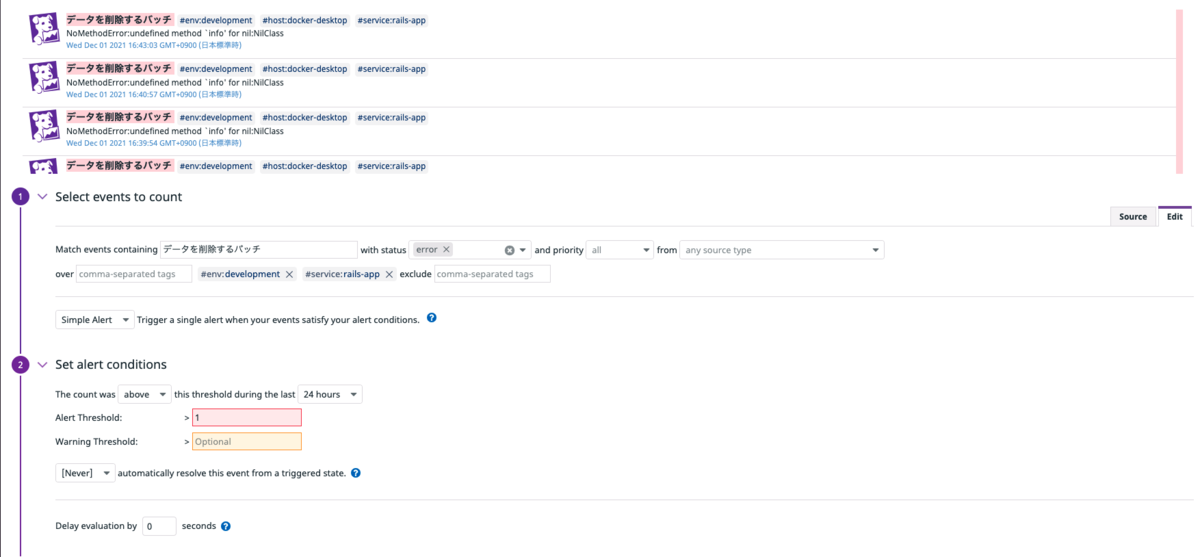
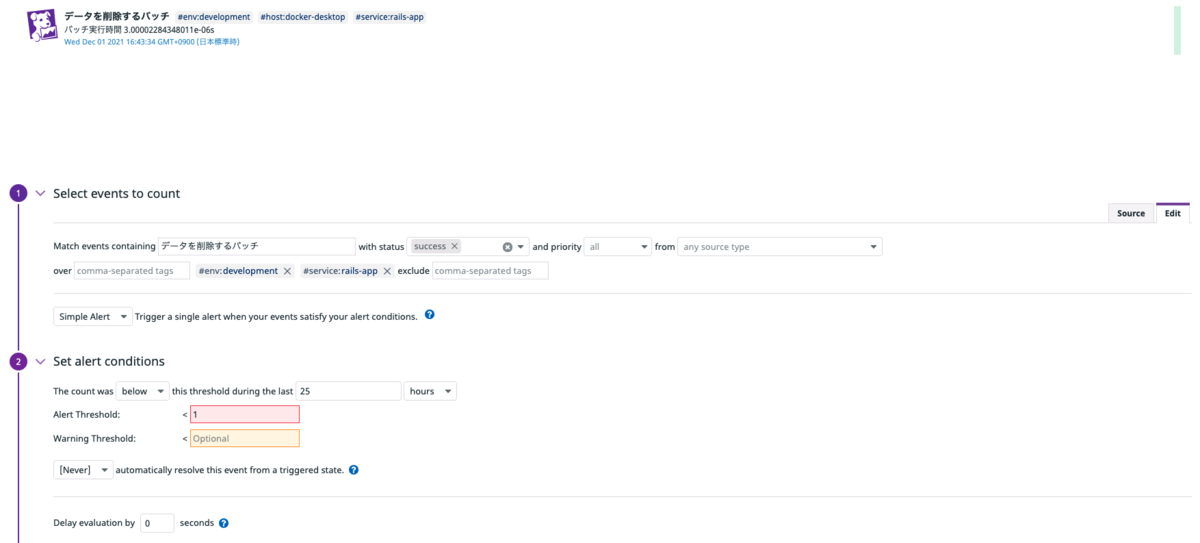
AWS ECS監視のオオカミ少年化を防ぐために考えたちょっとしたこと Amazon EventBridge(CloudWatch Events)で動かしているバッチをDatadogで監視する仕組みを構築した話
現状維持を良しとせず、試行錯誤しながらアウトプットする姿勢はとても頼もしく感じます。
反省点
ここまで良かった点ばかり書いていますが、当然省みることもあります。
「移行に関わりたい」というメンバーが想定以上に多く、移行作業が勢いよく進んでしまい、私がコントロール仕切れないこともありました。また、私が移行作業しつつアクセス障害への対応も行なっていたため、当然作業の中でボトルネックになってしまうことも発生し、十分にサポート仕切れないまま進んでしまい、不安を感じさせてしまったメンバーもいました。私がボトルネックになってしまうことは、事前に予測できていたことでした。
移行のふりかえりを行なった際に、「表面的にうまくいってると評価されているECS移行のイメージと参加当初ギャップがあった」というフィードバックをもらいました。これは当時、十分なサポート体制を組めなかった状態を的確に指摘していると感じています。
最後に
結果、Classiでは現在ほとんどのサービスをECSで運用し、デプロイの安定化と頻度の向上に成功しました。また、移行作業を通して若手メンバーを中心に、全社的な運用力の底上げに繋げられたと感じています。最悪の状況から前を向けるようになったのは、間違いなくこの時に成長してくれたメンバーのおかげです。
一方で繰り返しになりますが、移行の完了は終わりではありません、始まりなのです。移行は価値提供のスピードを上げていくにあたっての最低条件でしかありません。また、「ほぼ」と書いた通り移行完了していないリポジトリは残っています。
引き続き、より良いサービスを運用していくために精進していきます。